 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Question Embeddings with Cognitiv Representation Optimization for Knowledge Tracing
Apr 05, 2025The Knowledge Tracing (KT) aims to track changes in students' knowledge status and predict their future answers based on their historical answer records. Current research on KT modeling focuses on predicting student' future performance based on existing, unupdated records of student learning interactions. However, these approaches ignore the distractors (such as slipping and guessing) in the answering process and overlook that static cognitive representations are temporary and limited. Most of them assume that there are no distractors in the answering process and that the record representations fully represent the students' level of understanding and proficiency in knowledge. In this case, it may lead to many insynergy and incoordination issue in the original records. Therefore we propose a Cognitive Representation Optimization for Knowledge Tracing (CRO-KT) model, which utilizes a dynamic programming algorithm to optimize structure of cognitive representations. This ensures that the structure matches the students' cognitive patterns in terms of the difficulty of the exercises. Furthermore, we use the co-optimization algorithm to optimize the cognitive representations of the sub-target exercises in terms of the overall situation of exercises responses by considering all the exercises with co-relationships as a single goal. Meanwhile, the CRO-KT model fuses the learned relational embeddings from the bipartite graph with the optimized record representations in a weighted manner, enhancing the expression of students' cognition. Finally, experiments are conducted on three publicly available datasets respectively to validate the effectiveness of the proposed cognitive representation optimization model.
ENADPool: The Edge-Node Attention-based Differentiable Pooling for Graph Neural Networks
May 16, 2024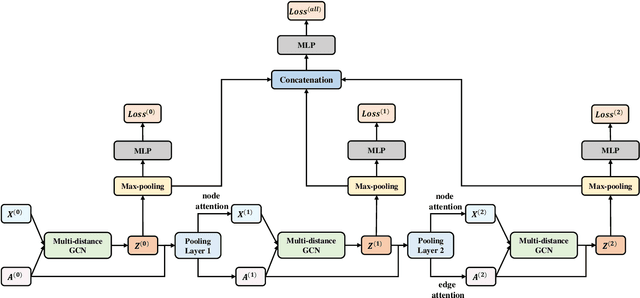
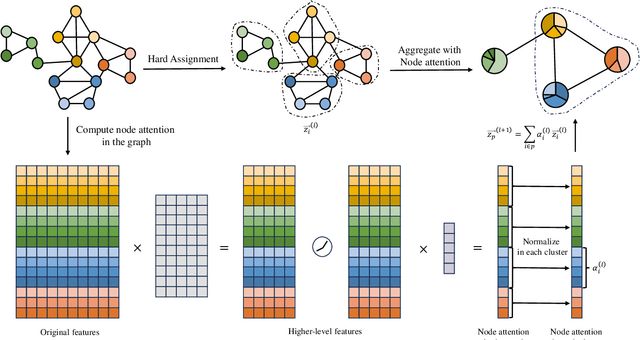
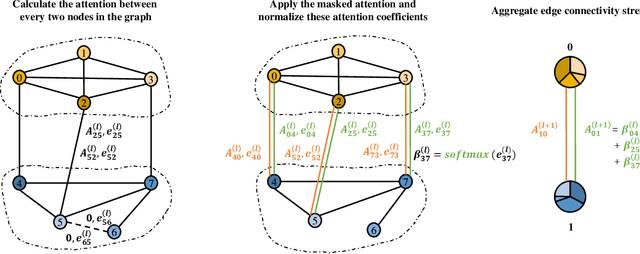
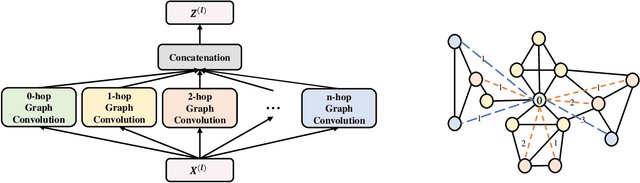
Graph Neural Networks (GNNs) are powerful tools for graph classification. One important operation for GNNs is the downsampling or pooling that can learn effective embeddings from the node representations. In this paper, we propose a new hierarchical pooling operation, namely the Edge-Node Attention-based Differentiable Pooling (ENADPool), for GNNs to learn effective graph representations. Unlike the classical hierarchical pooling operation that is based on the unclear node assignment and simply computes the averaged feature over the nodes of each cluster, the proposed ENADPool not only employs a hard clustering strategy to assign each node into an unique cluster, but also compress the node features as well as their edge connectivity strengths into the resulting hierarchical structure based on the attention mechanism after each pooling step. As a result, the proposed ENADPool simultaneously identifies the importance of different nodes within each separated cluster and edges between corresponding clusters, that significantly addresses the shortcomings of the uniform edge-node based structure information aggregation arising in the classical hierarchical pooling operation. Moreover, to mitigate the over-smoothing problem arising in existing GNNs, we propose a Multi-distance GNN (MD-GNN) model associated with the proposed ENADPool operation, allowing the nodes to actively and directly receive the feature information from neighbors at different random walk steps. Experiments demonstrate the effectiveness of the MD-GNN associated with the proposed ENADPool.
Group Multi-View Transformer for 3D Shape Analysis with Spatial Encoding
Dec 30, 2023In recent years, the results of view-based 3D shape recognition methods have saturated, and models with excellent performance cannot be deployed on memory-limited devices due to their huge size of parameters. To address this problem, we introduce a compression method based on knowledge distillation for this field, which largely reduces the number of parameters while preserving model performance as much as possible. Specifically, to enhance the capabilities of smaller models, we design a high-performing large model called Group Multi-view Vision Transformer (GMViT). In GMViT, the view-level ViT first establishes relationships between view-level features. Additionally, to capture deeper features, we employ the grouping module to enhance view-level features into group-level features. Finally, the group-level ViT aggregates group-level features into complete, well-formed 3D shape descriptors. Notably, in both ViTs, we introduce spatial encoding of camera coordinates as innovative position embeddings. Furthermore, we propose two compressed versions based on GMViT, namely GMViT-simple and GMViT-mini. To enhance the training effectiveness of the small models, we introduce a knowledge distillation method throughout the GMViT process, where the key outputs of each GMViT component serve as distillation targets. Extensive experiments demonstrate the efficacy of the proposed method. The large model GMViT achieves excellent 3D classification and retrieval results on the benchmark datasets ModelNet, ShapeNetCore55, and MCB. The smaller models, GMViT-simple and GMViT-mini, reduce the parameter size by 8 and 17.6 times, respectively, and improve shape recognition speed by 1.5 times on average, while preserving at least 90% of the classification and retrieval performance.
New Benchmark for Household Garbage Image Recognition
Feb 24, 2022
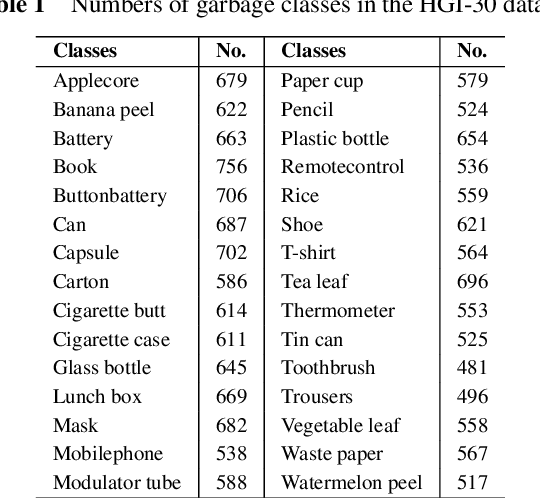

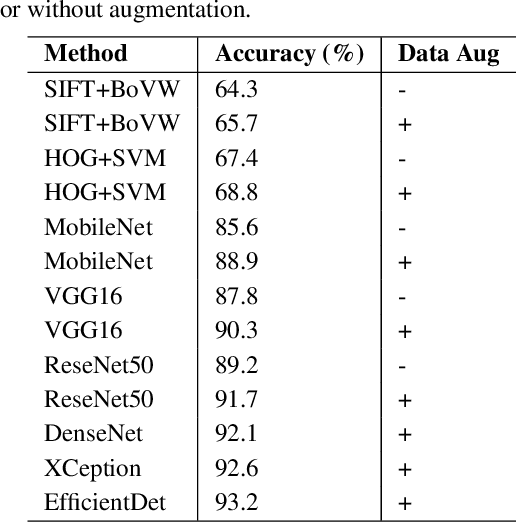
Household garbage images are usually faced with complex backgrounds, variable illuminations, diverse angles, and changeable shapes, which bring a great difficulty in garbage image classification. Due to the ability to discover problem-specific features, deep learning and especially convolutional neural networks (CNNs) have been successfully and widely used for image representation learning. However, available and stable household garbage datasets are insufficient, which seriously limits the development of research and application. Besides, the state of the art in the field of garbage image classification is not entirely clear. To solve this problem, in this study, we built a new open benchmark dataset for household garbage image classification by simulating different lightings, backgrounds, angles, and shapes. This dataset is named 30 Classes of Household Garbage Images (HGI-30), which contains 18,000 images of 30 household garbage classes. The publicly available HGI-30 dataset allows researchers to develop accurate and robust methods for household garbage recognition. We also conducted experiments and performance analysis of the state-of-the-art deep CNN methods on HGI-30, which serves as baseline results on this benchmark.
Domain-Invariant Proposals based on a Balanced Domain Classifier for Object Detection
Feb 12, 2022


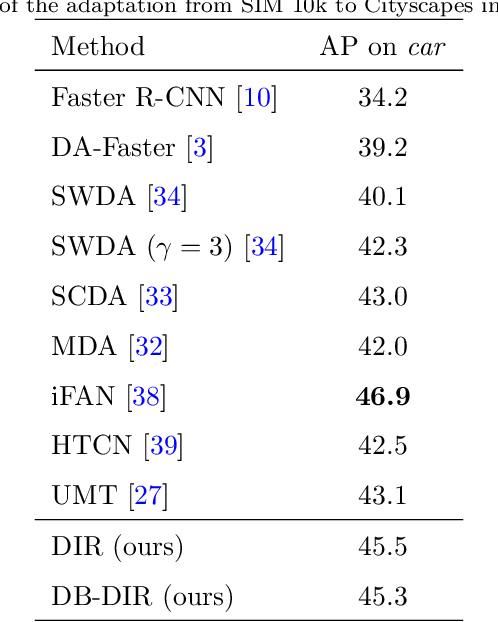
Object recognition from images means to automatically find object(s) of interest and to return their category and location information. Benefiting from research on deep learning, like convolutional neural networks~(CNNs) and generative adversarial networks, the performance in this field has been improved significantly, especially when training and test data are drawn from similar distributions. However, mismatching distributions, i.e., domain shifts, lead to a significant performance drop. In this paper, we build domain-invariant detectors by learning domain classifiers via adversarial training. Based on the previous works that align image and instance level features, we mitigate the domain shift further by introducing a domain adaptation component at the region level within Faster \mbox{R-CNN}. We embed a domain classification network in the region proposal network~(RPN) using adversarial learning. The RPN can now generate accurate region proposals in different domains by effectively aligning the features between them. To mitigate the unstable convergence during the adversarial learning, we introduce a balanced domain classifier as well as a network learning rate adjustment strategy. We conduct comprehensive experiments using four standard datasets. The results demonstrate the effectiveness and robustness of our object detection approach in domain shift scenarios.
Entropic Dynamic Time Warping Kernels for Co-evolving Financial Time Series Analysis
Oct 21, 2019
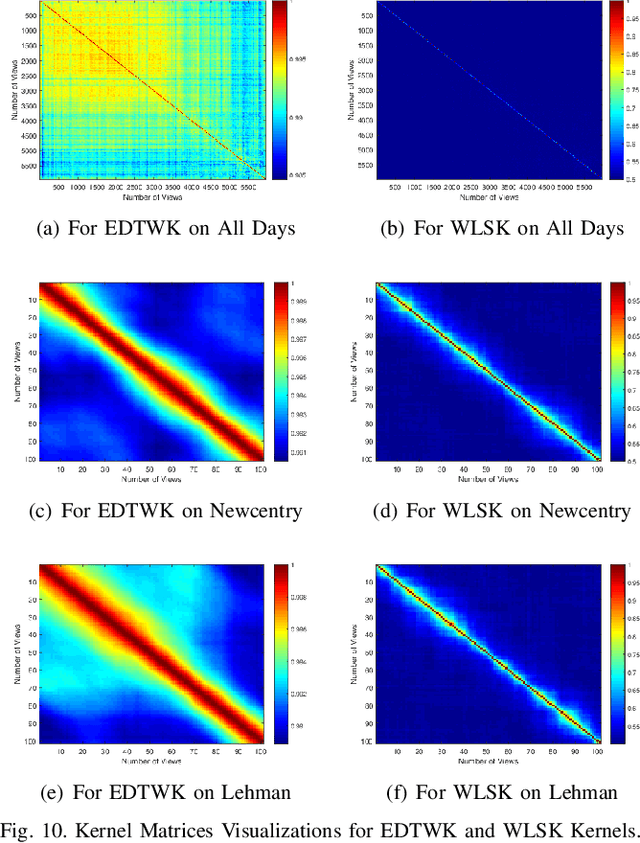


In this work, we develop a novel framework to measure the similarity between dynamic financial networks, i.e., time-varying financial networks. Particularly, we explore whether the proposed similarity measure can be employed to understand the structural evolution of the financial networks with time. For a set of time-varying financial networks with each vertex representing the individual time series of a different stock and each edge between a pair of time series representing the absolute value of their Pearson correlation, our start point is to compute the commute time matrix associated with the weighted adjacency matrix of the network structures, where each element of the matrix can be seen as the enhanced correlation value between pairwise stocks. For each network, we show how the commute time matrix allows us to identify a reliable set of dominant correlated time series as well as an associated dominant probability distribution of the stock belonging to this set. Furthermore, we represent each original network as a discrete dominant Shannon entropy time series computed from the dominant probability distribution. With the dominant entropy time series for each pair of financial networks to hand, we develop a similarity measure based on the classical dynamic time warping framework, for analyzing the financial time-varying networks. We show that the proposed similarity measure is positive definite and thus corresponds to a kernel measure on graphs. The proposed kernel bridges the gap between graph kernels and the classical dynamic time warping framework for multiple financial time series analysis. Experiments on time-varying networks extracted through New York Stock Exchange (NYSE) database demonstrate the effectiveness of the proposed approach.