 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Question Embeddings with Cognitiv Representation Optimization for Knowledge Tracing
Apr 05, 2025The Knowledge Tracing (KT) aims to track changes in students' knowledge status and predict their future answers based on their historical answer records. Current research on KT modeling focuses on predicting student' future performance based on existing, unupdated records of student learning interactions. However, these approaches ignore the distractors (such as slipping and guessing) in the answering process and overlook that static cognitive representations are temporary and limited. Most of them assume that there are no distractors in the answering process and that the record representations fully represent the students' level of understanding and proficiency in knowledge. In this case, it may lead to many insynergy and incoordination issue in the original records. Therefore we propose a Cognitive Representation Optimization for Knowledge Tracing (CRO-KT) model, which utilizes a dynamic programming algorithm to optimize structure of cognitive representations. This ensures that the structure matches the students' cognitive patterns in terms of the difficulty of the exercises. Furthermore, we use the co-optimization algorithm to optimize the cognitive representations of the sub-target exercises in terms of the overall situation of exercises responses by considering all the exercises with co-relationships as a single goal. Meanwhile, the CRO-KT model fuses the learned relational embeddings from the bipartite graph with the optimized record representations in a weighted manner, enhancing the expression of students' cognition. Finally, experiments are conducted on three publicly available datasets respectively to validate the effectiveness of the proposed cognitive representation optimization model.
Group Multi-View Transformer for 3D Shape Analysis with Spatial Encoding
Dec 30, 2023In recent years, the results of view-based 3D shape recognition methods have saturated, and models with excellent performance cannot be deployed on memory-limited devices due to their huge size of parameters. To address this problem, we introduce a compression method based on knowledge distillation for this field, which largely reduces the number of parameters while preserving model performance as much as possible. Specifically, to enhance the capabilities of smaller models, we design a high-performing large model called Group Multi-view Vision Transformer (GMViT). In GMViT, the view-level ViT first establishes relationships between view-level features. Additionally, to capture deeper features, we employ the grouping module to enhance view-level features into group-level features. Finally, the group-level ViT aggregates group-level features into complete, well-formed 3D shape descriptors. Notably, in both ViTs, we introduce spatial encoding of camera coordinates as innovative position embeddings. Furthermore, we propose two compressed versions based on GMViT, namely GMViT-simple and GMViT-mini. To enhance the training effectiveness of the small models, we introduce a knowledge distillation method throughout the GMViT process, where the key outputs of each GMViT component serve as distillation targets. Extensive experiments demonstrate the efficacy of the proposed method. The large model GMViT achieves excellent 3D classification and retrieval results on the benchmark datasets ModelNet, ShapeNetCore55, and MCB. The smaller models, GMViT-simple and GMViT-mini, reduce the parameter size by 8 and 17.6 times, respectively, and improve shape recognition speed by 1.5 times on average, while preserving at least 90% of the classification and retrieval performance.
A Regularization Approach for Instance-Based Superset Label Learning
Apr 05, 2019
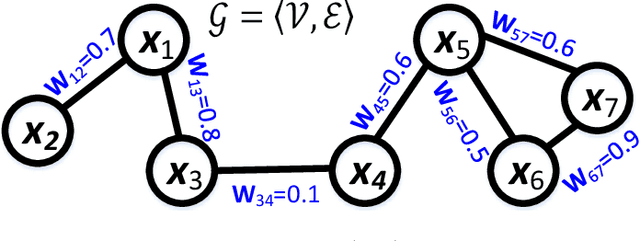
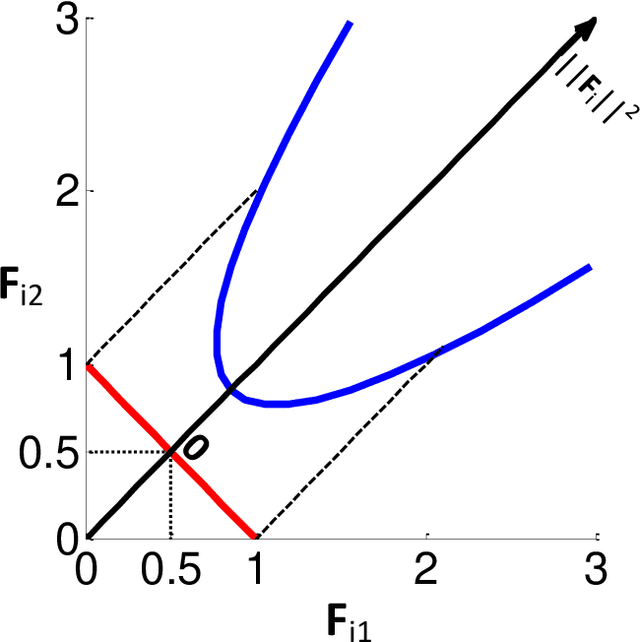
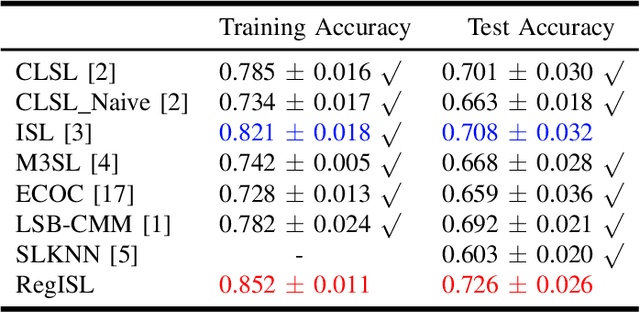
Different from the traditional supervised learning in which each training example has only one explicit label, superset label learning (SLL) refers to the problem that a training example can be associated with a set of candidate labels, and only one of them is correct. Existing SLL methods are either regularization-based or instance-based, and the latter of which has achieved state-of-the-art performance. This is because the latest instance-based methods contain an explicit disambiguation operation that accurately picks up the groundtruth label of each training example from its ambiguous candidate labels. However, such disambiguation operation does not fully consider the mutually exclusive relationship among different candidate labels, so the disambiguated labels are usually generated in a nondiscriminative way, which is unfavorable for the instance-based methods to obtain satisfactory performance. To address this defect, we develop a novel regularization approach for instance-based superset label (RegISL) learning so that our instance-based method also inherits the good discriminative ability possessed by the regularization scheme. Specifically, we employ a graph to represent the training set, and require the examples that are adjacent on the graph to obtain similar labels. More importantly, a discrimination term is proposed to enlarge the gap of values between possible labels and unlikely labels for every training example. As a result, the intrinsic constraints among different candidate labels are deployed, and the disambiguated labels generated by RegISL are more discriminative and accurate than those output by existing instance-based algorithms. The experimental results on various tasks convincingly demonstrate the superiority of our RegISL to other typical SLL methods in terms of both training accuracy and test accuracy.
A survey on trajectory clustering analysis
Feb 20, 2018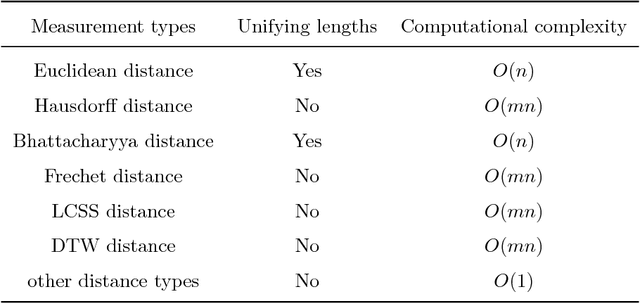
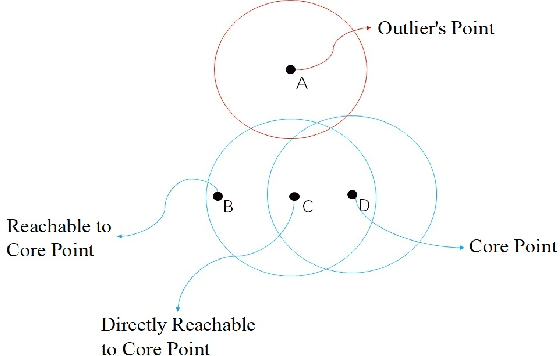
This paper comprehensively surveys the development of trajectory clustering. Considering the critical role of trajectory data mining in modern intelligent systems for surveillance security, abnormal behavior detection, crowd behavior analysis, and traffic control, trajectory clustering has attracted growing attention. Existing trajectory clustering methods can be grouped into three categories: unsupervised, supervised and semi-supervised algorithms. In spite of achieving a certain level of development, trajectory clustering is limited in its success by complex conditions such as application scenarios and data dimensions. This paper provides a holistic understanding and deep insight into trajectory clustering, and presents a comprehensive analysis of representative methods and promising future directions.
Face Aging Effect Simulation using Hidden Factor Analysis Joint Sparse Representation
Nov 04, 2015


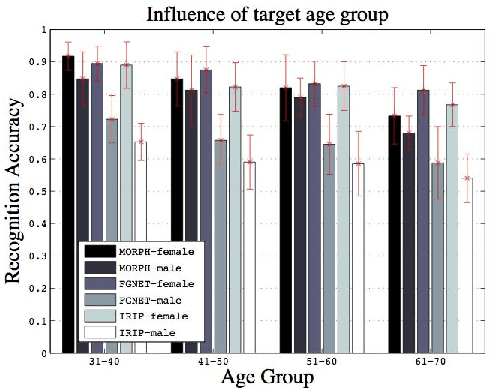
Face aging simulation has received rising investigations nowadays, whereas it still remains a challenge to generate convincing and natural age-progressed face images. In this paper, we present a novel approach to such an issue by using hidden factor analysis joint sparse representation. In contrast to the majority of tasks in the literature that handle the facial texture integrally, the proposed aging approach separately models the person-specific facial properties that tend to be stable in a relatively long period and the age-specific clues that change gradually over time. It then merely transforms the age component to a target age group via sparse reconstruction, yielding aging effects, which is finally combined with the identity component to achieve the aged face. Experiments are carried out on three aging databases, and the results achieved clearly demonstrate the effectiveness and robustness of the proposed method in rendering a face with aging effects. Additionally, a series of evaluations prove its validity with respect to identity preservation and aging effect generation.
Multiview Hessian Discriminative Sparse Coding for Image Annotation
Jul 15, 2013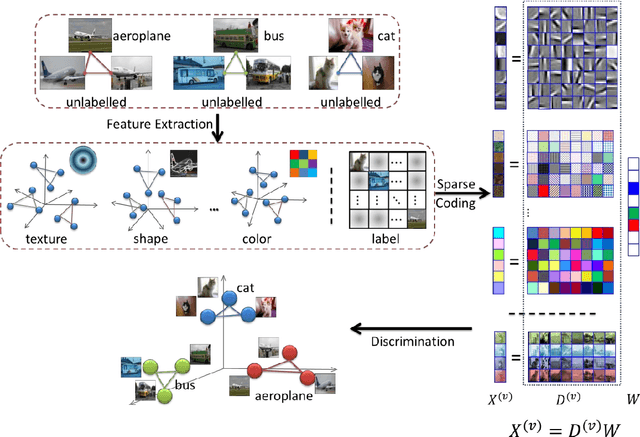
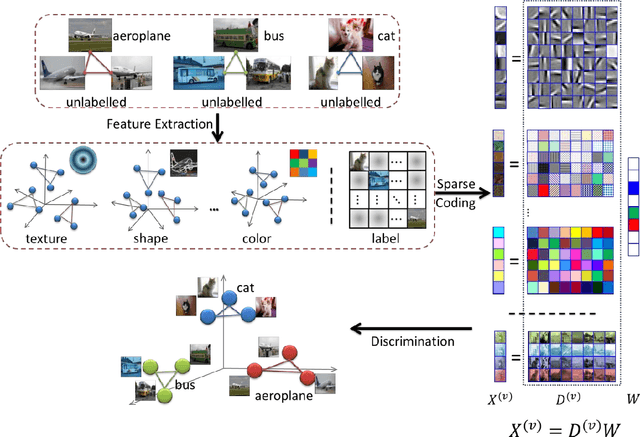


Sparse coding represents a signal sparsely by using an overcomplete dictionary, and obtains promising performance in practical computer vision applications, especially for signal restoration tasks such as image denoising and image inpainting. In recent years, many discriminative sparse coding algorithms have been developed for classification problems, but they cannot naturally handle visual data represented by multiview features. In addition, existing sparse coding algorithms use graph Laplacian to model the local geometry of the data distribution. It has been identified that Laplacian regularization biases the solution towards a constant function which possibly leads to poor extrapolating power. In this paper, we present multiview Hessian discriminative sparse coding (mHDSC) which seamlessly integrates Hessian regularization with discriminative sparse coding for multiview learning problems. In particular, mHDSC exploits Hessian regularization to steer the solution which varies smoothly along geodesics in the manifold, and treats the label information as an additional view of feature for incorporating the discriminative power for image annotation. We conduct extensive experiments on PASCAL VOC'07 dataset and demonstrate the effectiveness of mHDSC for image annotation.
* 35 pages