 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Training Sample Difficulty Balancing for Local Descriptor Learning
Mar 10, 2023

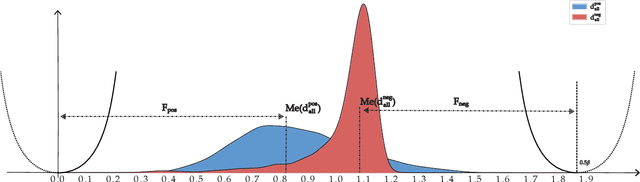

In the case of an imbalance between positive and negative samples, hard negative mining strategies have been shown to help models learn more subtle differences between positive and negative samples, thus improving recognition performance. However, if too strict mining strategies are promoted in the dataset, there may be a risk of introducing false negative samples. Meanwhile, the implementation of the mining strategy disrupts the difficulty distribution of samples in the real dataset, which may cause the model to over-fit these difficult samples. Therefore, in this paper, we investigate how to trade off the difficulty of the mined samples in order to obtain and exploit high-quality negative samples, and try to solve the problem in terms of both the loss function and the training strategy. The proposed balance loss provides an effective discriminant for the quality of negative samples by combining a self-supervised approach to the loss function, and uses a dynamic gradient modulation strategy to achieve finer gradient adjustment for samples of different difficulties. The proposed annealing training strategy then constrains the difficulty of the samples drawn from negative sample mining to provide data sources with different difficulty distributions for the loss function, and uses samples of decreasing difficulty to train the model. Extensive experiments show that our new descriptors outperform previous state-of-the-art descriptors for patch validation, matching, and retrieval tasks.
Interval Type-2 Fuzzy Neural Networks for Multi-Label Classification
Feb 21, 2023Prediction of multi-dimensional labels plays an important role in machine learning problems. We found that the classical binary labels could not reflect the contents and their relationships in an instance. Hence, we propose a multi-label classification model based on interval type-2 fuzzy logic. In the proposed model, we use a deep neural network to predict the type-1 fuzzy membership of an instance and another one to predict the fuzzifiers of the membership to generate interval type-2 fuzzy memberships. We also propose a loss function to measure the similarities between binary labels in datasets and interval type-2 fuzzy memberships generated by our model. The experiments validate that our approach outperforms baselines on multi-label classification benchmarks.
Global Hashing System for Fast Image Search
Apr 18, 2019
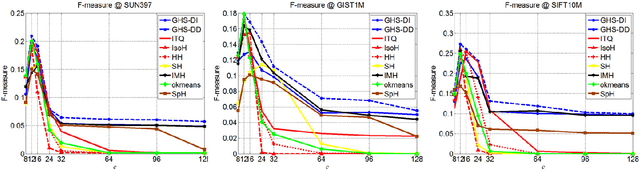
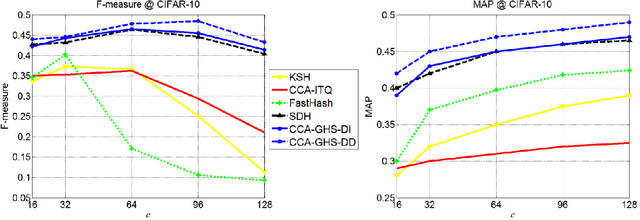

Hashing methods have been widely investigated for fast approximate nearest neighbor searching in large data sets. Most existing methods use binary vectors in lower dimensional spaces to represent data points that are usually real vectors of higher dimensionality. We divide the hashing process into two steps. Data points are first embedded in a low-dimensional space, and the global positioning system method is subsequently introduced but modified for binary embedding. We devise dataindependent and data-dependent methods to distribute the satellites at appropriate locations. Our methods are based on finding the tradeoff between the information losses in these two steps. Experiments show that our data-dependent method outperforms other methods in different-sized data sets from 100k to 10M. By incorporating the orthogonality of the code matrix, both our data-independent and data-dependent methods are particularly impressive in experiments on longer bits.
Coupled Learning for Facial Deblur
Apr 18, 2019



Blur in facial images significantly impedes the efficiency of recognition approaches. However, most existing blind deconvolution methods cannot generate satisfactory results due to their dependence on strong edges, which are sufficient in natural images but not in facial images. In this paper, we represent point spread functions (PSFs) by the linear combination of a set of pre-defined orthogonal PSFs, and similarly, an estimated intrinsic (EI) sharp face image is represented by the linear combination of a set of pre-defined orthogonal face images. In doing so, PSF and EI estimation is simplified to discovering two sets of linear combination coefficients, which are simultaneously found by our proposed coupled learning algorithm. To make our method robust to different types of blurry face images, we generate several candidate PSFs and EIs for a test image, and then, a non-blind deconvolution method is adopted to generate more EIs by those candidate PSFs. Finally, we deploy a blind image quality assessment metric to automatically select the optimal EI. Thorough experiments on the facial recognition technology database, extended Yale face database B, CMU pose, illumination, and expression (PIE) database, and face recognition grand challenge database version 2.0 demonstrate that the proposed approach effectively restores intrinsic sharp face images and, consequently, improves the performance of face recognition.
A survey on trajectory clustering analysis
Feb 20, 2018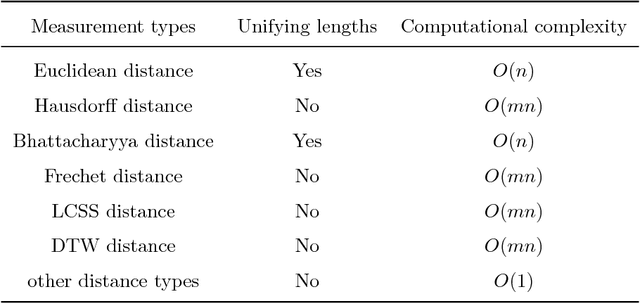
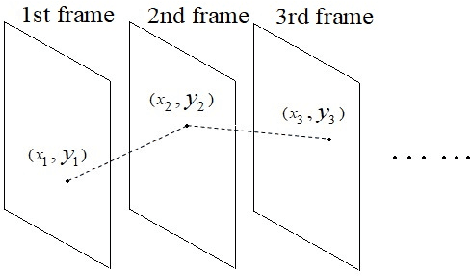
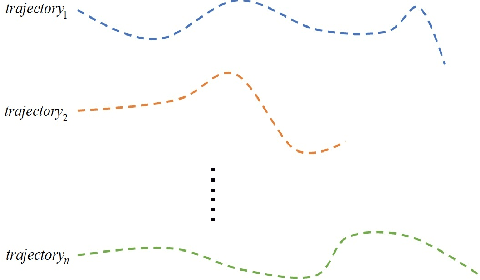
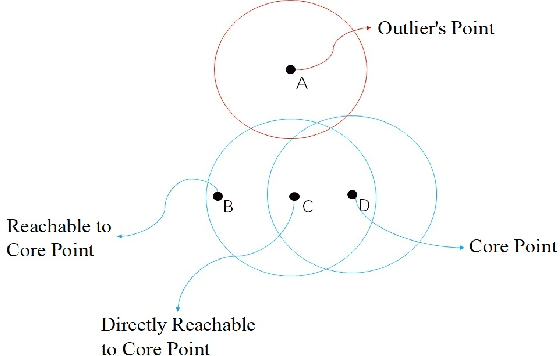
This paper comprehensively surveys the development of trajectory clustering. Considering the critical role of trajectory data mining in modern intelligent systems for surveillance security, abnormal behavior detection, crowd behavior analysis, and traffic control, trajectory clustering has attracted growing attention. Existing trajectory clustering methods can be grouped into three categories: unsupervised, supervised and semi-supervised algorithms. In spite of achieving a certain level of development, trajectory clustering is limited in its success by complex conditions such as application scenarios and data dimensions. This paper provides a holistic understanding and deep insight into trajectory clustering, and presents a comprehensive analysis of representative methods and promising future directions.