 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Regularization Approach for Instance-Based Superset Label Learning
Paper and Code
Apr 05, 2019
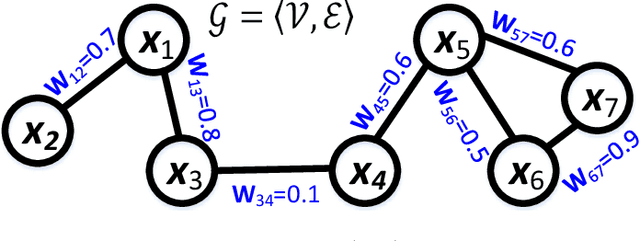
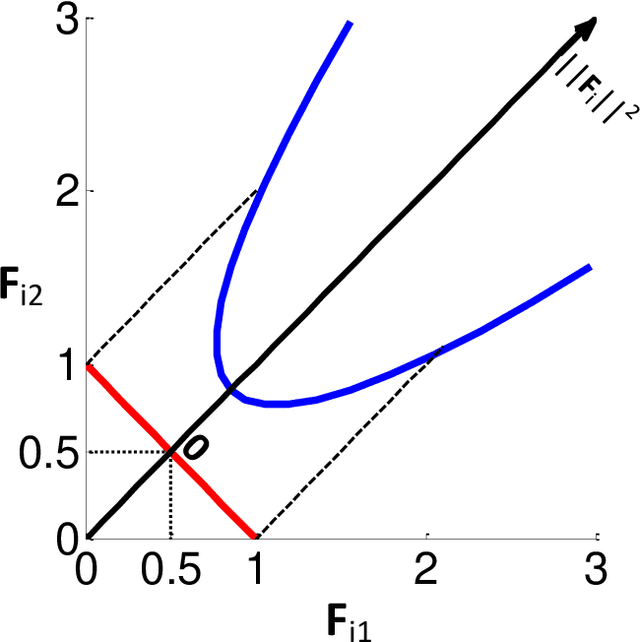
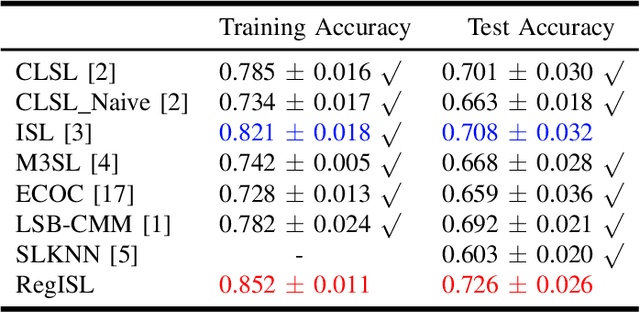
Different from the traditional supervised learning in which each training example has only one explicit label, superset label learning (SLL) refers to the problem that a training example can be associated with a set of candidate labels, and only one of them is correct. Existing SLL methods are either regularization-based or instance-based, and the latter of which has achieved state-of-the-art performance. This is because the latest instance-based methods contain an explicit disambiguation operation that accurately picks up the groundtruth label of each training example from its ambiguous candidate labels. However, such disambiguation operation does not fully consider the mutually exclusive relationship among different candidate labels, so the disambiguated labels are usually generated in a nondiscriminative way, which is unfavorable for the instance-based methods to obtain satisfactory performance. To address this defect, we develop a novel regularization approach for instance-based superset label (RegISL) learning so that our instance-based method also inherits the good discriminative ability possessed by the regularization scheme. Specifically, we employ a graph to represent the training set, and require the examples that are adjacent on the graph to obtain similar labels. More importantly, a discrimination term is proposed to enlarge the gap of values between possible labels and unlikely labels for every training example. As a result, the intrinsic constraints among different candidate labels are deployed, and the disambiguated labels generated by RegISL are more discriminative and accurate than those output by existing instance-based algorithms. The experimental results on various tasks convincingly demonstrate the superiority of our RegISL to other typical SLL methods in terms of both training accuracy and test accuracy.