 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal Intelligent U2V Channel Model for 6G Sensing-Communication Integration
May 13, 2026This paper proposes a novel UAV-to-Vehicle (U2V) channel model for sixth-generation (6G) intelligent sensing-communication integration, based on three-dimensional (3D) scatterer prediction. To explore the mapping relationship between physical environment and electromagnetic space, a new high-fidelity mixed sensing-communication integration U2V simulation dataset under wide-lane scenarios with different vehicular traffic densities (VTDs) and UAV heights is constructed. Based on the constructed dataset, a novel 3D Scatterer Prediction and Distribution Estimation (3D-SPADE) algorithm is proposed, which leverages LiDAR point clouds to accurately predict the spatial distribution of scatterers. Furthermore, the clustering of scatterers and the subsequent classification into dynamic and static types are meticulously designed for highly dynamic U2V scenarios, while reducing computational complexity and improving modeling accuracy. As LiDAR point clouds vary over time, dynamic and static clusters evolve via 3D-SPADE, enabling precise modeling of channel non-stationarity and consistency. Simulation results demonstrate that, in the wide-lane scenario with varying VTDs and UAV heights, the proposed 3D-SPADE consistently achieves high scatterer occupancy detection performance within the voxel grid. In particular, under favorable configurations, recall reaches 93.26%, and precision reaches 95.74%, highlighting the reliability of 3D-SPADE. Key channel statistical characteristics are simulated and analyzed. These characteristics from the simulation experiments are highly consistent with ray-tracing results and exhibit better agreement than with the standardized model and inconsistent model, validating the necessity of exploring the mapping relationship and the effectiveness of the proposed model.
Sensing-Assisted LoS/NLoS Identification in Dynamic UAV Positioning Systems
May 13, 2026In this paper, a sensing-assisted non-line-of-sight (NLoS) identification method for dynamic uncrewed aerial vehicle (UAV) positioning is proposed for the first time. For urban UAV-to-ground scenarios, a new multi-modal sensing-communication integrated dataset is constructed to support line-of-sight (LoS)/NLoS identification, covering two typical urban scenarios and a wide range of flight altitudes. Based on the constructed dataset, a novel dual-input feature fusion network is proposed, which addresses the challenge of heterogeneous representations between RGB images and channel impulse response (CIR) data to enable the joint extraction and fusion of sensing and communication features for LoS/NLoS identification. Simulation results show that the identification accuracy can reach up to 97.69%, while achieving an improvement of at least 3.59% compared to traditional CIR-only and RGB-only methods. Moreover, strong few-shot generalization is observed, as the proposed method stabilizes and approaches full-sample performance with fewer than 200 target samples and exceeds traditional CIR-only and RGB-only methods with fewer than 100 target samples in all cross-scenario and cross-altitude experiments. Even under Gaussian noise with a variance of 0.35 applied to RGB images, the accuracy degradation remains approximately 0.5%. By utilizing the proposed LoS/NLoS identification method, the error of trilateration positioning can be reduced by approximately 70% in a crossroad scenario, verifying the utility of the proposed method.
HeterSEED: Semantics-Structure Decoupling for Heterogeneous Graph Learning under Heterophily
May 06, 2026Many real-world heterogeneous graphs exhibit pronounced heterophily, where connected nodes often have dissimilar labels or play different semantic roles. In such settings, standard heterogeneous graph neural networks that aggregate messages along metapaths or meta-relations primarily based on feature similarity can propagate misleading information, since feature similarity may be misaligned with underlying relational semantics. In this paper, we propose HeterSEED, a semantics-structure decoupling framework for heterogeneous graph learning under heterophily. HeterSEED decouples representation learning into a heterogeneous semantic channel that captures type- and relation-aware local semantics and a structure-aware heterophily channel that separates homophilic and heterophilic neighborhoods via pseudo-label-guided partitioning and aggregates them using metapath-based structural weights. A node-level adaptive fusion mechanism then combines the two channels to produce context-dependent node representations. Theoretically, we establish that, on heterogeneous graphs under heterophily, HeterSEED is strictly more expressive than standard heterogeneous graph neural networks that rely primarily on feature similarity and provably reduces the prediction bias introduced by heterophilic neighbors. Experiments on five real-world heterogeneous graphs, including two large-scale networks at the million-node and hundred-million-edge scale, demonstrate that HeterSEED consistently outperforms representative heterogeneous graph neural networks and recent heterophily-aware baselines, especially in strongly heterophilic regimes.
A multi-stage soft computing framework for complex disease modelling and decision support: A liver cirrhosis case study
Apr 26, 2026Liver cirrhosis is a major global health problem causing millions of deaths annually, and timely detection with aggressive treatment can significantly improve patients' quality of life. Modelling complex diseases from biomedical data is computationally challenging due to high dimensionality, strong feature correlations, noise, and limited labelled samples. Conventional Machine Learning (ML) pipelines often struggle with robustness, interpretability, and generalisation under such conditions. In this study, we propose an ML-driven multi-stage decision framework for complex disease modelling and therapeutic exploration. The framework integrates single-cell transcriptomic profiling, high-dimensional network-based feature stabilisation, multi-model learning, deep representation construction, and post-hoc decision support. Specifically, single-cell sequencing data were analysed to identify key cellular subpopulations, followed by high-dimensional weighted gene co-expression network analysis (hdWGCNA) to stabilise gene modules under sparsity and noise. To enhance non-linear feature interaction modelling, tabular molecular features were restructured into two-dimensional disease maps and analysed using a CNN. Finally, molecular docking was incorporated as a decision-support module to evaluate candidate therapeutic compounds. Using liver cirrhosis as a representative case, the framework identified a disease-associated endothelial subpopulation and extracted seven robust signature genes (HSPB1, GADD45A, CLDN5, ATP1B3, C1QBP, ENPP2, and PARL). The CNN-based representation learning module outperformed conventional pipelines in classification. The framework is disease-agnostic and readily extends to other omics-driven biomedical applications involving uncertainty, heterogeneity, and limited samples.
Dual-Stage Invariant Continual Learning under Extreme Visual Sparsity
Mar 27, 2026Continual learning seeks to maintain stable adaptation under non-stationary environments, yet this problem becomes particularly challenging in object detection, where most existing methods implicitly assume relatively balanced visual conditions. In extreme-sparsity regimes, such as those observed in space-based resident space object (RSO) detection scenarios, foreground signals are overwhelmingly dominated by background observations. Under such conditions, we analytically demonstrate that background-driven gradients destabilize the feature backbone during sequential domain shifts, causing progressive representation drift. This exposes a structural limitation of continual learning approaches relying solely on output-level distillation, as they fail to preserve intermediate representation stability. To address this, we propose a dual-stage invariant continual learning framework via joint distillation, enforcing structural and semantic consistency on both backbone representations and detection predictions, respectively, thereby suppressing error propagation at its source while maintaining adaptability. Furthermore, to regulate gradient statistics under severe imbalance, we introduce a sparsity-aware data conditioning strategy combining patch-based sampling and distribution-aware augmentation. Experiments on a high-resolution space-based RSO detection dataset show consistent improvement over established continual object detection methods, achieving an absolute gain of +4.0 mAP under sequential domain shifts.
Multi-Modal Intelligent Channel Modeling: From Fine-tuned LLMs to Pre-trained Foundation Models
Mar 11, 2026To meet the evolving demands of sixth-generation (6G) wireless channel modeling, such as precise prediction capability, extension capabilities, and system participation capability, multi-modal intelligent channel modeling (MMICM) has been proposed based on Synesthesia of Machines (SoM) which explores the mapping relationship between multi-modal sensing in physical environment and channel characteristics in electromagnetic space. Furthermore, for integrating heterogeneous sensing, reasoning across scales, and generalizing to complex air-space-ground-sea communication environments, two new paradigms of MMICM are explored, including fine-tuned large language models (LLMs) for Channel Modeling (LLM4CM) and Wireless Channel Foundation Model (WiCo). LLM4CM leverages pre-trained LLMs on channel representations for cross-modal alignment and lightweight adaptation, enabling flexible channel modeling for 6G multi-band and multi-scenario communication systems. WiCo, which pre-trained on physically valid channel realizations and their associated environmental and modal observations, embeds electromagnetic equations for physical interpretability and uses parameterized adapters for scalability. This article details the architectures and features of LLM4CM and WiCo, laying a foundation for artificial intelligence (AI)-native 6G wireless communication systems. Then, we conducts a comparative analysis of the two emerging paradigms, focusing on their distinct characteristics, relative advantages, inherent limitations, and performance attributes. Finally, we discuss the future research directions.
RAIE: Region-Aware Incremental Preference Editing with LoRA for LLM-based Recommendation
Feb 28, 2026Large language models (LLMs) are increasingly adopted as the backbone of recommender systems. However, user-item interactions in real-world scenarios are non-stationary, making preference drift over time inevitable. Existing model update strategies mainly rely on global fine-tuning or pointwise editing, but they face two fundamental challenges: (i) imbalanced update granularity, where global updates perturb behaviors unrelated to the target while pointwise edits fail to capture broader preference shifts; (ii) unstable incremental updates, where repeated edits interfere with prior adaptations, leading to catastrophic forgetting and inconsistent recommendations. To address these issues, we propose Region-Aware Incremental Editing (RAIE), a plug-in framework that freezes the backbone model and performs region-level updates. RAIE first constructs semantically coherent preference regions via spherical k-means in the representation space. It then assigns incoming sequences to regions via confidence-aware gating and performs three localized edit operations - Update, Expand, and Add - to dynamically revise the affected region. Each region is equipped with a dedicated Low-Rank Adaptation (LoRA) module, which is trained only on the region's updated data. During inference, RAIE routes each user sequence to its corresponding region and activates the region-specific adapter for prediction. Experiments on two benchmark datasets under a time-sliced protocol that segments data into Set-up (S), Finetune (F), and Test (T) show that RAIE significantly outperforms state-of-the-art baselines while effectively mitigating forgetting. These results demonstrate that region-aware editing offers an accurate and scalable mechanism for continual adaptation in dynamic recommendation scenarios. Our code is available at https://github.com/fengaogao/RAIE.
LGAN: An Efficient High-Order Graph Neural Network via the Line Graph Aggregation
Dec 11, 2025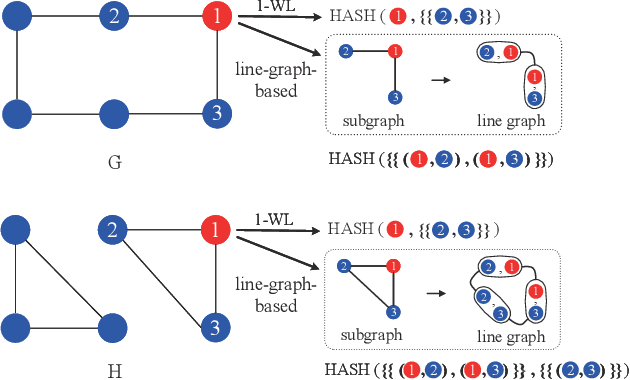
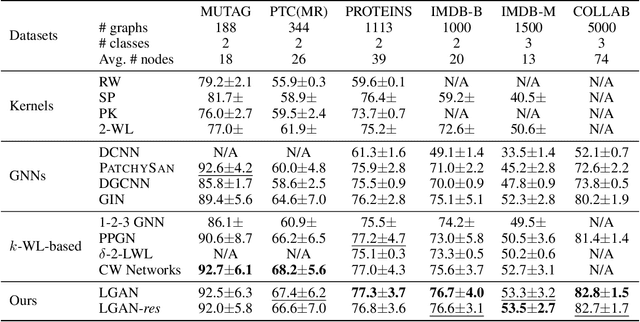
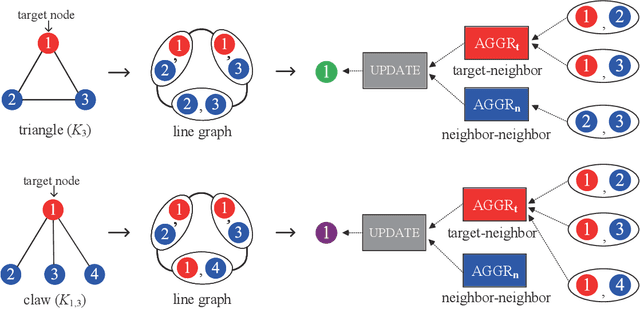
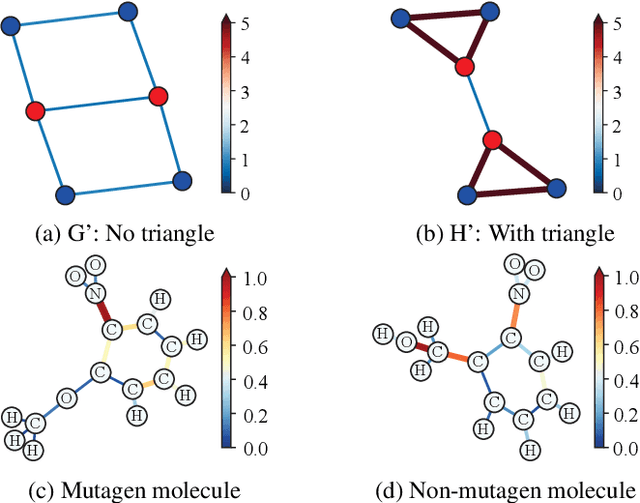
Graph Neural Networks (GNNs) have emerged as a dominant paradigm for graph classification. Specifically, most existing GNNs mainly rely on the message passing strategy between neighbor nodes, where the expressivity is limited by the 1-dimensional Weisfeiler-Lehman (1-WL) test. Although a number of k-WL-based GNNs have been proposed to overcome this limitation, their computational cost increases rapidly with k, significantly restricting the practical applicability. Moreover, since the k-WL models mainly operate on node tuples, these k-WL-based GNNs cannot retain fine-grained node- or edge-level semantics required by attribution methods (e.g., Integrated Gradients), leading to the less interpretable problem. To overcome the above shortcomings, in this paper, we propose a novel Line Graph Aggregation Network (LGAN), that constructs a line graph from the induced subgraph centered at each node to perform the higher-order aggregation. We theoretically prove that the LGAN not only possesses the greater expressive power than the 2-WL under injective aggregation assumptions, but also has lower time complexity. Empirical evaluations on benchmarks demonstrate that the LGAN outperforms state-of-the-art k-WL-based GNNs, while offering better interpretability.
WiCo-MG: Wireless Channel Foundation Model for Multipath Generation via Synesthesia of Machines
Nov 19, 2025Precise modeling of channel multipath is essential for understanding wireless propagation environments and optimizing communication systems. In particular, sixth-generation (6G) artificial intelligence (AI)-native communication systems demand massive and high-quality multipath channel data to enable intelligent model training and performance optimization. In this paper, we propose a wireless channel foundation model (WiCo) for multipath generation (WiCo-MG) via Synesthesia of Machines (SoM). To provide a solid training foundation for WiCo-MG, a new synthetic intelligent sensing-communication dataset for uncrewed aerial vehicle (UAV)-to-ground (U2G) communications is constructed. To overcome the challenges of cross-modal alignment and mapping, a two-stage training framework is proposed. In the first stage, sensing images are embedded into discrete-continuous SoM feature spaces, and multipath maps are embedded into a sensing-initialized discrete SoM space to align the representations. In the second stage, a mixture of shared and routed experts (S-R MoE) Transformer with frequency-aware expert routing learns the mapping from sensing to channel SoM feature spaces, enabling decoupled and adaptive multipath generation. Experimental results demonstrate that WiCo-MG achieves state-of-the-art in-distribution generation performance and superior out-of-distribution generalization, reducing NMSE by more than 2.59 dB over baselines, while exhibiting strong scalability in model and dataset growth and extensibility to new multipath parameters and tasks. Owing to higher accuracy, stronger generalization, and better scalability, WiCo-MG is expected to enable massive and high-fidelity channel data generation for the development of 6G AI-native communication systems.
WiCo-PG: Wireless Channel Foundation Model for Pathloss Map Generation via Synesthesia of Machines
Nov 19, 2025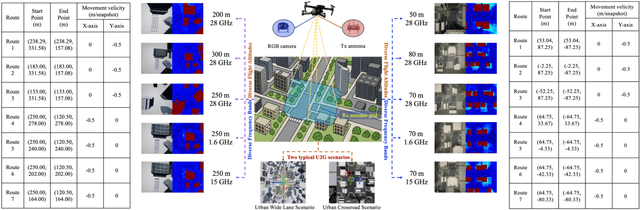
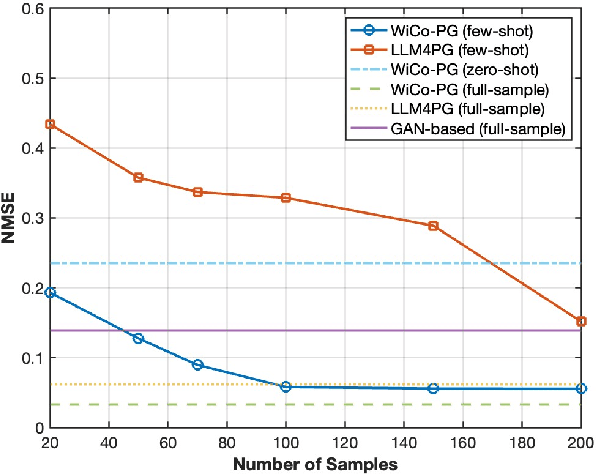
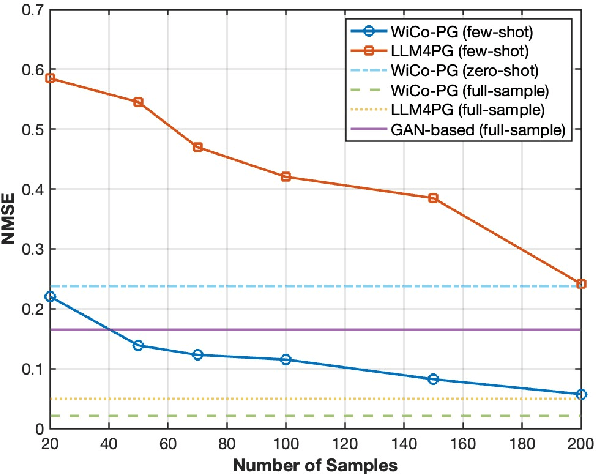
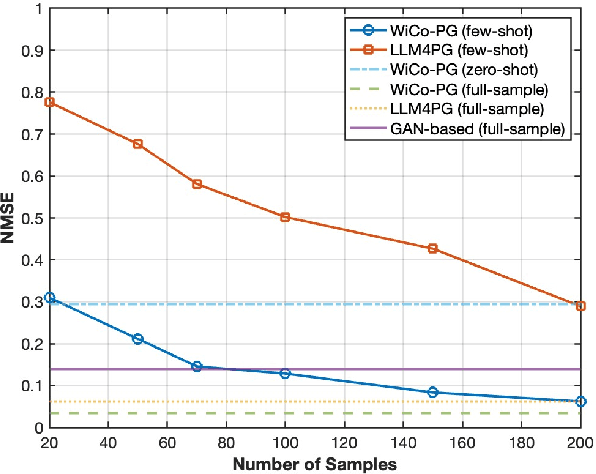
A wireless channel foundation model for pathloss map generation (WiCo-PG) via Synesthesia of Machines (SoM) is developed for the first time. Considering sixth-generation (6G) uncrewed aerial vehicle (UAV)-to-ground (U2G) scenarios, a new multi-modal sensing-communication dataset is constructed for WiCo-PG pre-training, including multiple U2G scenarios, diverse flight altitudes, and diverse frequency bands. Based on the constructed dataset, the proposed WiCo-PG enables cross-modal pathloss map generation by leveraging RGB images from different scenarios and flight altitudes. In WiCo-PG, a novel network architecture designed for cross-modal pathloss map generation based on dual vector quantized generative adversarial networks (VQGANs) and Transformer is proposed. Furthermore, a novel frequency-guided shared-routed mixture of experts (S-R MoE) architecture is designed for cross-modal pathloss map generation. Simulation results demonstrate that the proposed WiCo-PG achieves improved pathloss map generation accuracy through pre-training with a normalized mean squared error (NMSE) of 0.012, outperforming the large language model (LLM)-based scheme, i.e., LLM4PG, and the conventional deep learning-based scheme by more than 6.98 dB. The enhanced generality of the proposed WiCo-PG can further outperform the LLM4PG by at least 1.37 dB using 2.7% samples in few-shot generalization.