 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAIE: Region-Aware Incremental Preference Editing with LoRA for LLM-based Recommendation
Feb 28, 2026Large language models (LLMs) are increasingly adopted as the backbone of recommender systems. However, user-item interactions in real-world scenarios are non-stationary, making preference drift over time inevitable. Existing model update strategies mainly rely on global fine-tuning or pointwise editing, but they face two fundamental challenges: (i) imbalanced update granularity, where global updates perturb behaviors unrelated to the target while pointwise edits fail to capture broader preference shifts; (ii) unstable incremental updates, where repeated edits interfere with prior adaptations, leading to catastrophic forgetting and inconsistent recommendations. To address these issues, we propose Region-Aware Incremental Editing (RAIE), a plug-in framework that freezes the backbone model and performs region-level updates. RAIE first constructs semantically coherent preference regions via spherical k-means in the representation space. It then assigns incoming sequences to regions via confidence-aware gating and performs three localized edit operations - Update, Expand, and Add - to dynamically revise the affected region. Each region is equipped with a dedicated Low-Rank Adaptation (LoRA) module, which is trained only on the region's updated data. During inference, RAIE routes each user sequence to its corresponding region and activates the region-specific adapter for prediction. Experiments on two benchmark datasets under a time-sliced protocol that segments data into Set-up (S), Finetune (F), and Test (T) show that RAIE significantly outperforms state-of-the-art baselines while effectively mitigating forgetting. These results demonstrate that region-aware editing offers an accurate and scalable mechanism for continual adaptation in dynamic recommendation scenarios. Our code is available at https://github.com/fengaogao/RAIE.
LGAN: An Efficient High-Order Graph Neural Network via the Line Graph Aggregation
Dec 11, 2025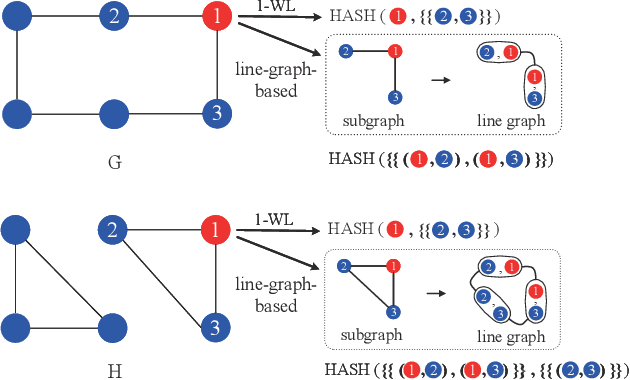
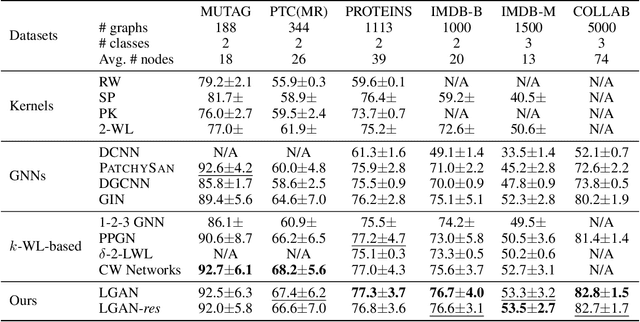
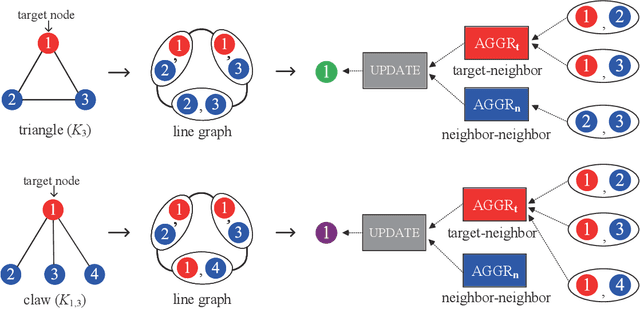
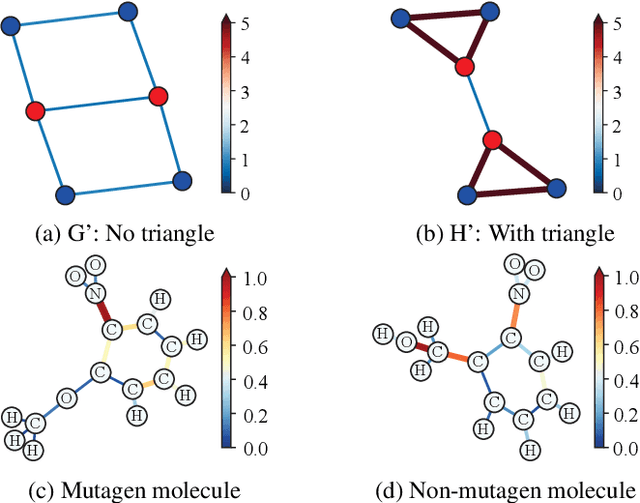
Graph Neural Networks (GNNs) have emerged as a dominant paradigm for graph classification. Specifically, most existing GNNs mainly rely on the message passing strategy between neighbor nodes, where the expressivity is limited by the 1-dimensional Weisfeiler-Lehman (1-WL) test. Although a number of k-WL-based GNNs have been proposed to overcome this limitation, their computational cost increases rapidly with k, significantly restricting the practical applicability. Moreover, since the k-WL models mainly operate on node tuples, these k-WL-based GNNs cannot retain fine-grained node- or edge-level semantics required by attribution methods (e.g., Integrated Gradients), leading to the less interpretable problem. To overcome the above shortcomings, in this paper, we propose a novel Line Graph Aggregation Network (LGAN), that constructs a line graph from the induced subgraph centered at each node to perform the higher-order aggregation. We theoretically prove that the LGAN not only possesses the greater expressive power than the 2-WL under injective aggregation assumptions, but also has lower time complexity. Empirical evaluations on benchmarks demonstrate that the LGAN outperforms state-of-the-art k-WL-based GNNs, while offering better interpretability.
Knowledge Probing for Graph Representation Learning
Aug 07, 2024Graph learning methods have been extensively applied in diverse application areas. However, what kind of inherent graph properties e.g. graph proximity, graph structural information has been encoded into graph representation learning for downstream tasks is still under-explored. In this paper, we propose a novel graph probing framework (GraphProbe) to investigate and interpret whether the family of graph learning methods has encoded different levels of knowledge in graph representation learning. Based on the intrinsic properties of graphs, we design three probes to systematically investigate the graph representation learning process from different perspectives, respectively the node-wise level, the path-wise level, and the structural level. We construct a thorough evaluation benchmark with nine representative graph learning methods from random walk based approaches, basic graph neural networks and self-supervised graph methods, and probe them on six benchmark datasets for node classification, link prediction and graph classification. The experimental evaluation verify that GraphProbe can estimate the capability of graph representation learning. Remaking results have been concluded: GCN and WeightedGCN methods are relatively versatile methods achieving better results with respect to different tasks.
HC-GAE: The Hierarchical Cluster-based Graph Auto-Encoder for Graph Representation Learning
May 23, 2024Graph Auto-Encoders (GAEs) are powerful tools for graph representation learning. In this paper, we develop a novel Hierarchical Cluster-based GAE (HC-GAE), that can learn effective structural characteristics for graph data analysis. To this end, during the encoding process, we commence by utilizing the hard node assignment to decompose a sample graph into a family of separated subgraphs. We compress each subgraph into a coarsened node, transforming the original graph into a coarsened graph. On the other hand, during the decoding process, we adopt the soft node assignment to reconstruct the original graph structure by expanding the coarsened nodes. By hierarchically performing the above compressing procedure during the decoding process as well as the expanding procedure during the decoding process, the proposed HC-GAE can effectively extract bidirectionally hierarchical structural features of the original sample graph. Furthermore, we re-design the loss function that can integrate the information from either the encoder or the decoder. Since the associated graph convolution operation of the proposed HC-GAE is restricted in each individual separated subgraph and cannot propagate the node information between different subgraphs, the proposed HC-GAE can significantly reduce the over-smoothing problem arising in the classical convolution-based GAEs. The proposed HC-GAE can generate effective representations for either node classification or graph classification, and the experiments demonstrate the effectiveness on real-world datasets.
ENADPool: The Edge-Node Attention-based Differentiable Pooling for Graph Neural Networks
May 16, 2024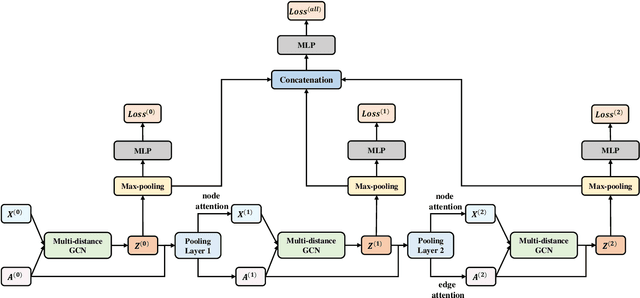
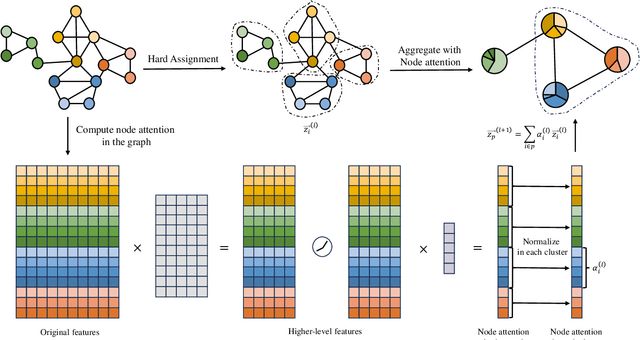
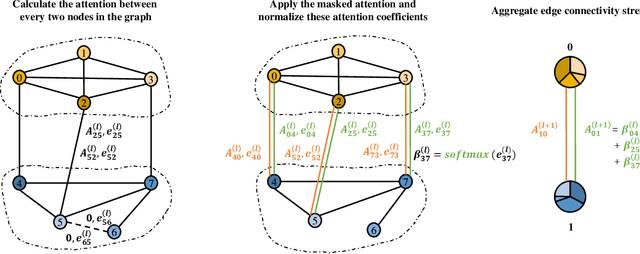
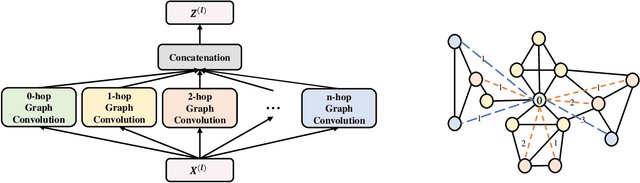
Graph Neural Networks (GNNs) are powerful tools for graph classification. One important operation for GNNs is the downsampling or pooling that can learn effective embeddings from the node representations. In this paper, we propose a new hierarchical pooling operation, namely the Edge-Node Attention-based Differentiable Pooling (ENADPool), for GNNs to learn effective graph representations. Unlike the classical hierarchical pooling operation that is based on the unclear node assignment and simply computes the averaged feature over the nodes of each cluster, the proposed ENADPool not only employs a hard clustering strategy to assign each node into an unique cluster, but also compress the node features as well as their edge connectivity strengths into the resulting hierarchical structure based on the attention mechanism after each pooling step. As a result, the proposed ENADPool simultaneously identifies the importance of different nodes within each separated cluster and edges between corresponding clusters, that significantly addresses the shortcomings of the uniform edge-node based structure information aggregation arising in the classical hierarchical pooling operation. Moreover, to mitigate the over-smoothing problem arising in existing GNNs, we propose a Multi-distance GNN (MD-GNN) model associated with the proposed ENADPool operation, allowing the nodes to actively and directly receive the feature information from neighbors at different random walk steps. Experiments demonstrate the effectiveness of the MD-GNN associated with the proposed ENADPool.
SSHPool: The Separated Subgraph-based Hierarchical Pooling
Mar 24, 2024In this paper, we develop a novel local graph pooling method, namely the Separated Subgraph-based Hierarchical Pooling (SSHPool), for graph classification. To this end, we commence by assigning the nodes of a sample graph into different clusters, resulting in a family of separated subgraphs. We individually employ a local graph convolution units as the local structure to further compress each subgraph into a coarsened node, transforming the original graph into a coarsened graph. Since these subgraphs are separated by different clusters and the structural information cannot be propagated between them, the local convolution operation can significantly avoid the over-smoothing problem arising in most existing Graph Neural Networks (GNNs). By hierarchically performing the proposed procedures on the resulting coarsened graph, the proposed SSHPool can effectively extract the hierarchical global feature of the original graph structure, encapsulating rich intrinsic structural characteristics. Furthermore, we develop an end-to-end GNN framework associated with the proposed SSHPool module for graph classification. Experimental results demonstrate the superior performance of the proposed model on real-world datasets, significantly outperforming state-of-the-art GNN methods in terms of the classification accuracies.
Dual-modal Prior Semantic Guided Infrared and Visible Image Fusion for Intelligent Transportation System
Mar 24, 2024
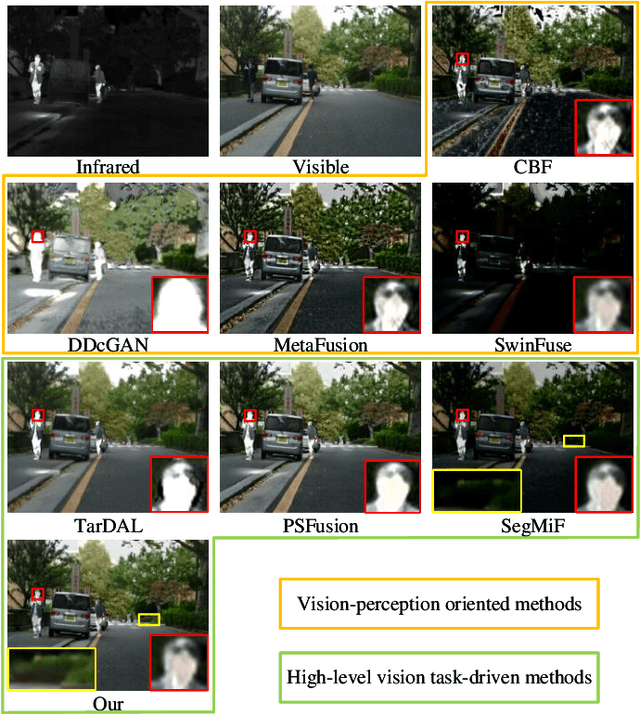

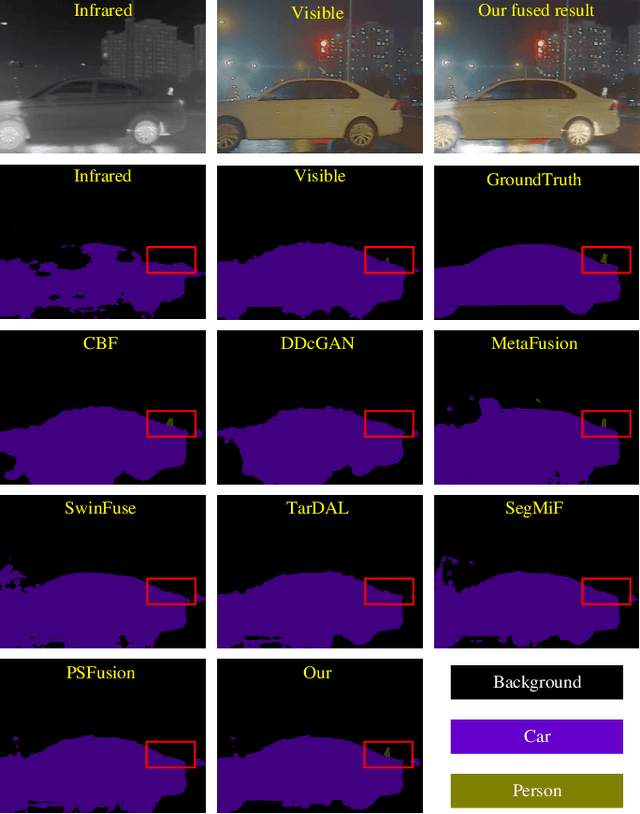
Infrared and visible image fusion (IVF) plays an important role in intelligent transportation system (ITS). The early works predominantly focus on boosting the visual appeal of the fused result, and only several recent approaches have tried to combine the high-level vision task with IVF. However, they prioritize the design of cascaded structure to seek unified suitable features and fit different tasks. Thus, they tend to typically bias toward to reconstructing raw pixels without considering the significance of semantic features. Therefore, we propose a novel prior semantic guided image fusion method based on the dual-modality strategy, improving the performance of IVF in ITS. Specifically, to explore the independent significant semantic of each modality, we first design two parallel semantic segmentation branches with a refined feature adaptive-modulation (RFaM) mechanism. RFaM can perceive the features that are semantically distinct enough in each semantic segmentation branch. Then, two pilot experiments based on the two branches are conducted to capture the significant prior semantic of two images, which then is applied to guide the fusion task in the integration of semantic segmentation branches and fusion branches. In addition, to aggregate both high-level semantics and impressive visual effects, we further investigate the frequency response of the prior semantics, and propose a multi-level representation-adaptive fusion (MRaF) module to explicitly integrate the low-frequent prior semantic with the high-frequent details. Extensive experiments on two public datasets demonstrate the superiority of our method over the state-of-the-art image fusion approaches, in terms of either the visual appeal or the high-level semantics.
AKBR: Learning Adaptive Kernel-based Representations for Graph Classification
Mar 24, 2024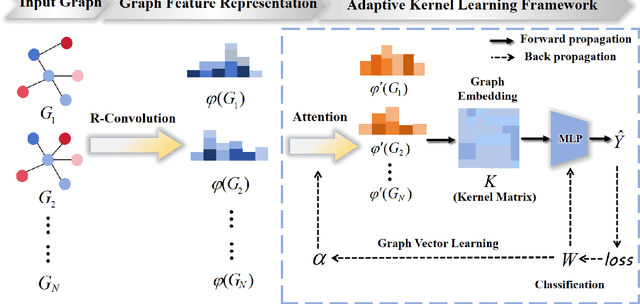
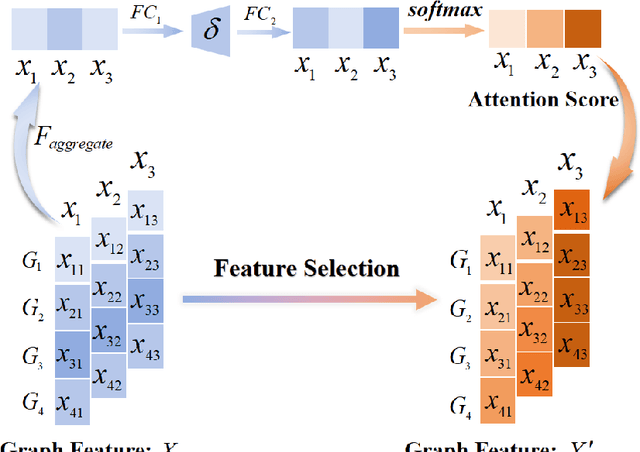
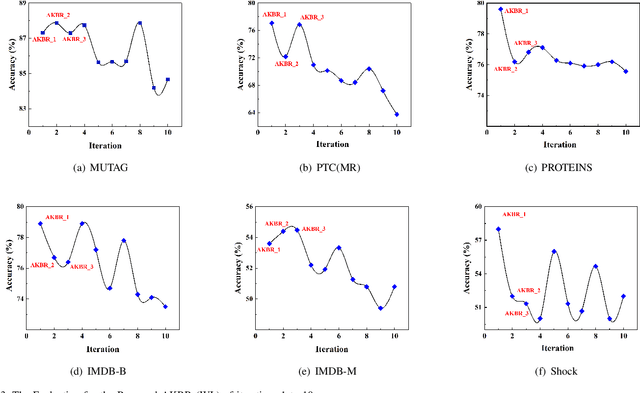
In this paper, we propose a new model to learn Adaptive Kernel-based Representations (AKBR) for graph classification. Unlike state-of-the-art R-convolution graph kernels that are defined by merely counting any pair of isomorphic substructures between graphs and cannot provide an end-to-end learning mechanism for the classifier, the proposed AKBR approach aims to define an end-to-end representation learning model to construct an adaptive kernel matrix for graphs. To this end, we commence by leveraging a novel feature-channel attention mechanism to capture the interdependencies between different substructure invariants of original graphs. The proposed AKBR model can thus effectively identify the structural importance of different substructures, and compute the R-convolution kernel between pairwise graphs associated with the more significant substructures specified by their structural attentions. Since each row of the resulting kernel matrix can be theoretically seen as the embedding vector of a sample graph, the proposed AKBR model is able to directly employ the resulting kernel matrix as the graph feature matrix and input it into the classifier for classification (i.e., the SoftMax layer), naturally providing an end-to-end learning architecture between the kernel computation as well as the classifier. Experimental results show that the proposed AKBR model outperforms existing state-of-the-art graph kernels and deep learning methods on standard graph benchmarks.
AERK: Aligned Entropic Reproducing Kernels through Continuous-time Quantum Walks
Mar 04, 2023In this work, we develop an Aligned Entropic Reproducing Kernel (AERK) for graph classification. We commence by performing the Continuous-time Quantum Walk (CTQW) on each graph structure, and computing the Averaged Mixing Matrix (AMM) to describe how the CTQW visit all vertices from a starting vertex. More specifically, we show how this AMM matrix allows us to compute a quantum Shannon entropy for each vertex of a graph. For pairwise graphs, the proposed AERK kernel is defined by computing a reproducing kernel based similarity between the quantum Shannon entropies of their each pair of aligned vertices. The analysis of theoretical properties reveals that the proposed AERK kernel cannot only address the shortcoming of neglecting the structural correspondence information between graphs arising in most existing R-convolution graph kernels, but also overcome the problem of neglecting the structural differences between pairs of aligned vertices arising in existing vertex-based matching kernels. Moreover, unlike existing classical graph kernels that only focus on the global or local structural information of graphs, the proposed AERK kernel can simultaneously capture both global and local structural information through the quantum Shannon entropies, reflecting more precise kernel based similarity measures between pairs of graphs. The above theoretical properties explain the effectiveness of the proposed kernel. The experimental evaluation on standard graph datasets demonstrates that the proposed AERK kernel is able to outperform state-of-the-art graph kernels for graph classification tasks.
QESK: Quantum-based Entropic Subtree Kernels for Graph Classification
Dec 10, 2022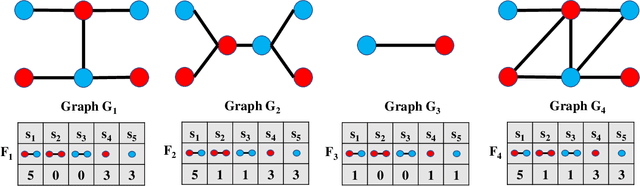
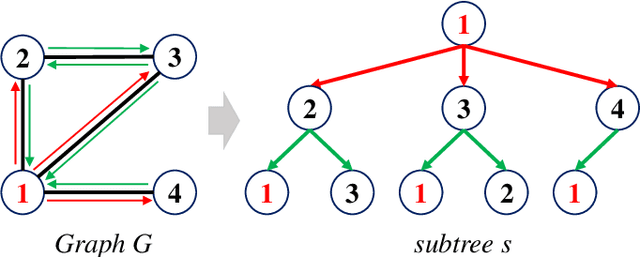
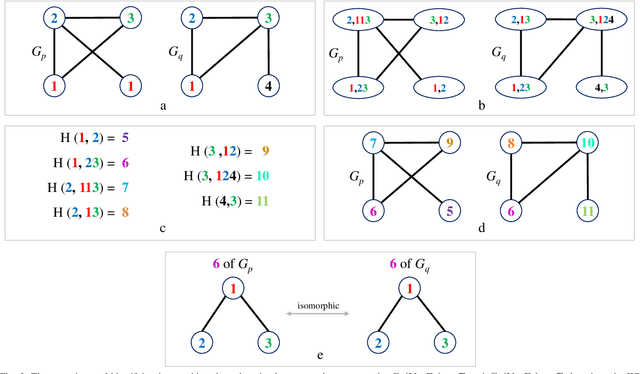
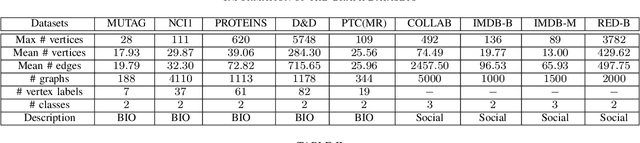
In this paper, we propose a novel graph kernel, namely the Quantum-based Entropic Subtree Kernel (QESK), for Graph Classification. To this end, we commence by computing the Average Mixing Matrix (AMM) of the Continuous-time Quantum Walk (CTQW) evolved on each graph structure. Moreover, we show how this AMM matrix can be employed to compute a series of entropic subtree representations associated with the classical Weisfeiler-Lehman (WL) algorithm. For a pair of graphs, the QESK kernel is defined by computing the exponentiation of the negative Euclidean distance between their entropic subtree representations, theoretically resulting in a positive definite graph kernel. We show that the proposed QESK kernel not only encapsulates complicated intrinsic quantum-based structural characteristics of graph structures through the CTQW, but also theoretically addresses the shortcoming of ignoring the effects of unshared substructures arising in state-of-the-art R-convolution graph kernels. Moreover, unlike the classical R-convolution kernels, the proposed QESK can discriminate the distinctions of isomorphic subtrees in terms of the global graph structures, theoretically explaining the effectiveness. Experiments indicate that the proposed QESK kernel can significantly outperform state-of-the-art graph kernels and graph deep learning methods for graph classification problems.