 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAFD: Domain Adaptation via Feature Disentanglement for Image Classification
Jan 30, 2023



A good feature representation is the key to image classification. In practice, image classifiers may be applied in scenarios different from what they have been trained on. This so-called domain shift leads to a significant performance drop in image classification. Unsupervised domain adaptation (UDA) reduces the domain shift by transferring the knowledge learned from a labeled source domain to an unlabeled target domain. We perform feature disentanglement for UDA by distilling category-relevant features and excluding category-irrelevant features from the global feature maps. This disentanglement prevents the network from overfitting to category-irrelevant information and makes it focus on information useful for classification. This reduces the difficulty of domain alignment and improves the classification accuracy on the target domain. We propose a coarse-to-fine domain adaptation method called Domain Adaptation via Feature Disentanglement~(DAFD), which has two components: (1)the Category-Relevant Feature Selection (CRFS) module, which disentangles the category-relevant features from the category-irrelevant features, and (2)the Dynamic Local Maximum Mean Discrepancy (DLMMD) module, which achieves fine-grained alignment by reducing the discrepancy within the category-relevant features from different domains. Combined with the CRFS, the DLMMD module can align the category-relevant features properly. We conduct comprehensive experiment on four standard datasets. Our results clearly demonstrate the robustness and effectiveness of our approach in domain adaptive image classification tasks and its competitiveness to the state of the art.
Domain-Invariant Proposals based on a Balanced Domain Classifier for Object Detection
Feb 12, 2022


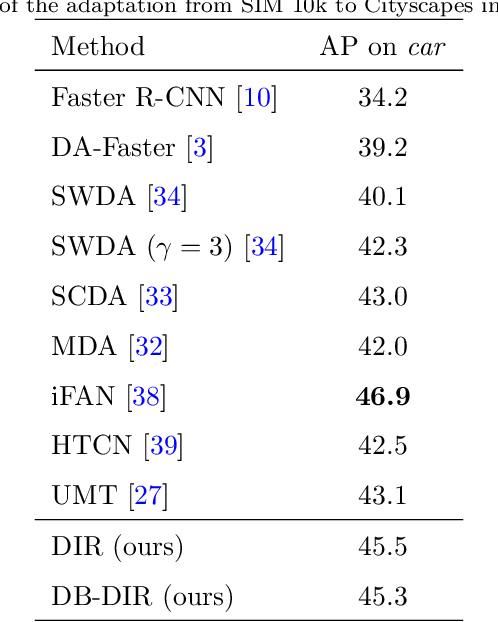
Object recognition from images means to automatically find object(s) of interest and to return their category and location information. Benefiting from research on deep learning, like convolutional neural networks~(CNNs) and generative adversarial networks, the performance in this field has been improved significantly, especially when training and test data are drawn from similar distributions. However, mismatching distributions, i.e., domain shifts, lead to a significant performance drop. In this paper, we build domain-invariant detectors by learning domain classifiers via adversarial training. Based on the previous works that align image and instance level features, we mitigate the domain shift further by introducing a domain adaptation component at the region level within Faster \mbox{R-CNN}. We embed a domain classification network in the region proposal network~(RPN) using adversarial learning. The RPN can now generate accurate region proposals in different domains by effectively aligning the features between them. To mitigate the unstable convergence during the adversarial learning, we introduce a balanced domain classifier as well as a network learning rate adjustment strategy. We conduct comprehensive experiments using four standard datasets. The results demonstrate the effectiveness and robustness of our object detection approach in domain shift scenarios.
Frequency Fitness Assignment: Optimization without a Bias for Good Solutions can be Efficient
Dec 02, 2021
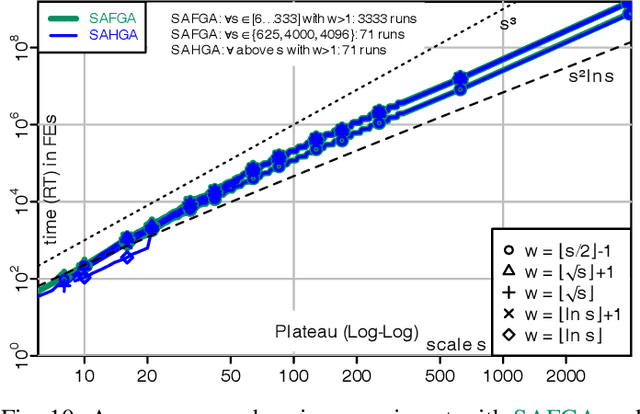
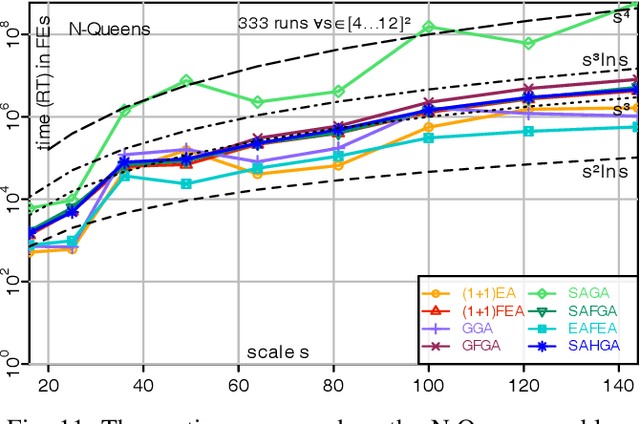
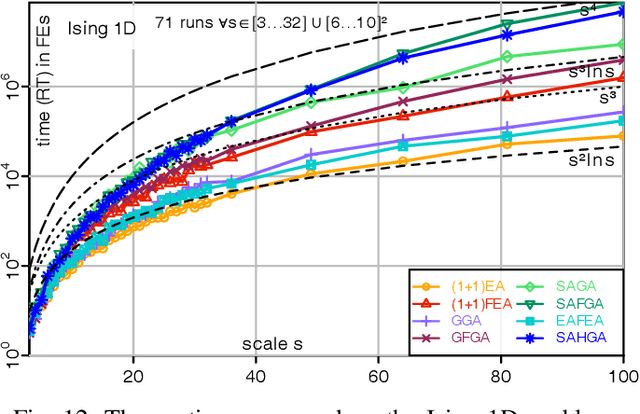
A fitness assignment process transforms the features (such as the objective value) of a candidate solution to a scalar fitness, which then is the basis for selection. Under Frequency Fitness Assignment (FFA), the fitness corresponding to an objective value is its encounter frequency and is subject to minimization. FFA creates algorithms that are not biased towards better solutions and are invariant under all bijections of the objective function value. We investigate the impact of FFA on the performance of two theory-inspired, state-of-the-art EAs, the Greedy (2+1) GA and the Self-Adjusting (1+(lambda,lambda)) GA. FFA improves their performance significantly on some problems that are hard for them. We empirically find that one FFA-based algorithm can solve all theory-based benchmark problems in this study, including traps, jumps, and plateaus, in polynomial time. We propose two hybrid approaches that use both direct and FFA-based optimization and find that they perform well. All FFA-based algorithms also perform better on satisfiability problems than all pure algorithm variants.
Benchmarking in Optimization: Best Practice and Open Issues
Jul 07, 2020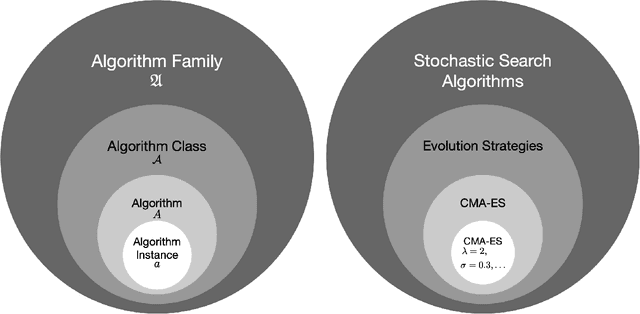
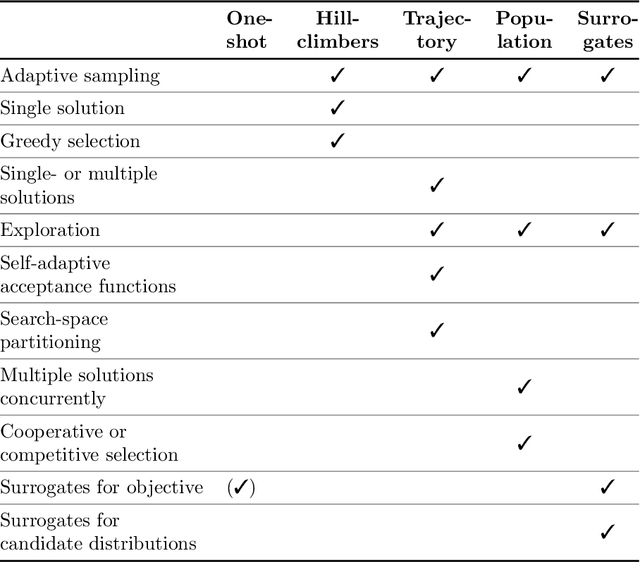
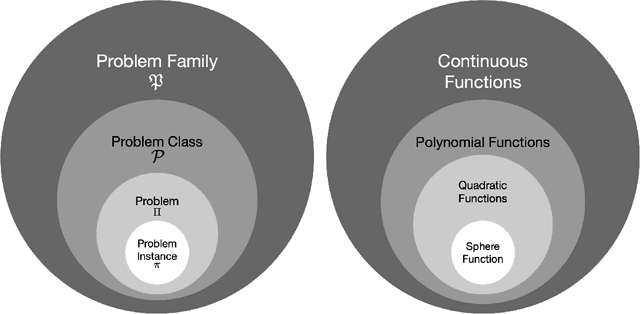

This survey compiles ideas and recommendations from more than a dozen researchers with different backgrounds and from different institutes around the world. Promoting best practice in benchmarking is its main goal. The article discusses eight essential topics in benchmarking: clearly stated goals, well-specified problems, suitable algorithms, adequate performance measures, thoughtful analysis, effective and efficient designs, comprehensible presentations, and guaranteed reproducibility. The final goal is to provide well-accepted guidelines (rules) that might be useful for authors and reviewers. As benchmarking in optimization is an active and evolving field of research this manuscript is meant to co-evolve over time by means of periodic updates.
Skeleton Based Action Recognition using a Stacked Denoising Autoencoder with Constraints of Privileged Information
Mar 12, 2020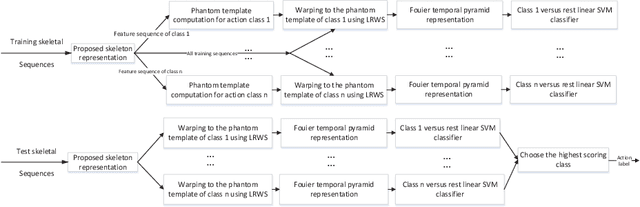
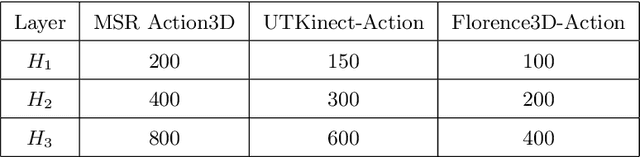
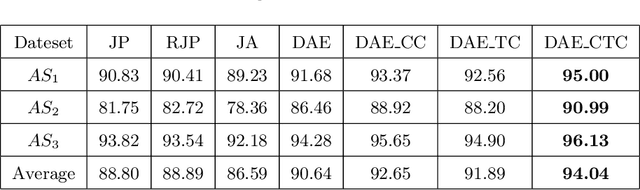
Recently, with the availability of cost-effective depth cameras coupled with real-time skeleton estimation, the interest in skeleton-based human action recognition is renewed. Most of the existing skeletal representation approaches use either the joint location or the dynamics model. Differing from the previous studies, we propose a new method called Denoising Autoencoder with Temporal and Categorical Constraints (DAE_CTC)} to study the skeletal representation in a view of skeleton reconstruction. Based on the concept of learning under privileged information, we integrate action categories and temporal coordinates into a stacked denoising autoencoder in the training phase, to preserve category and temporal feature, while learning the hidden representation from a skeleton. Thus, we are able to improve the discriminative validity of the hidden representation. In order to mitigate the variation resulting from temporary misalignment, a new method of temporal registration, called Locally-Warped Sequence Registration (LWSR), is proposed for registering the sequences of inter- and intra-class actions. We finally represent the sequences using a Fourier Temporal Pyramid (FTP) representation and perform classification using a combination of LWSR registration, FTP representation, and a linear Support Vector Machine (SVM). The experimental results on three action data sets, namely MSR-Action3D, UTKinect-Action, and Florence3D-Action, show that our proposal performs better than many existing methods and comparably to the state of the art.
Frequency Fitness Assignment: Making Optimization Algorithms Invariant under Bijective Transformations of the Objective Function
Jan 07, 2020
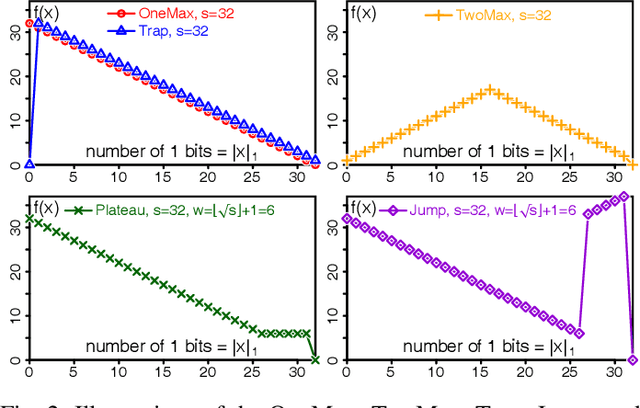
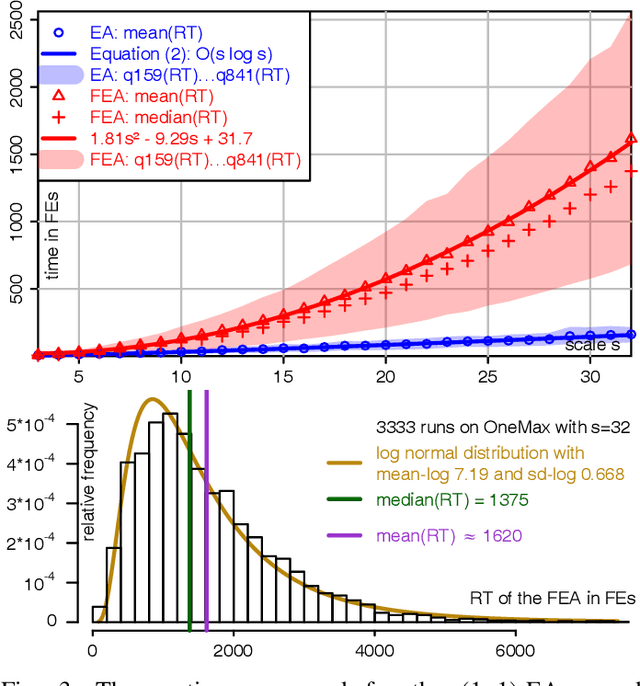
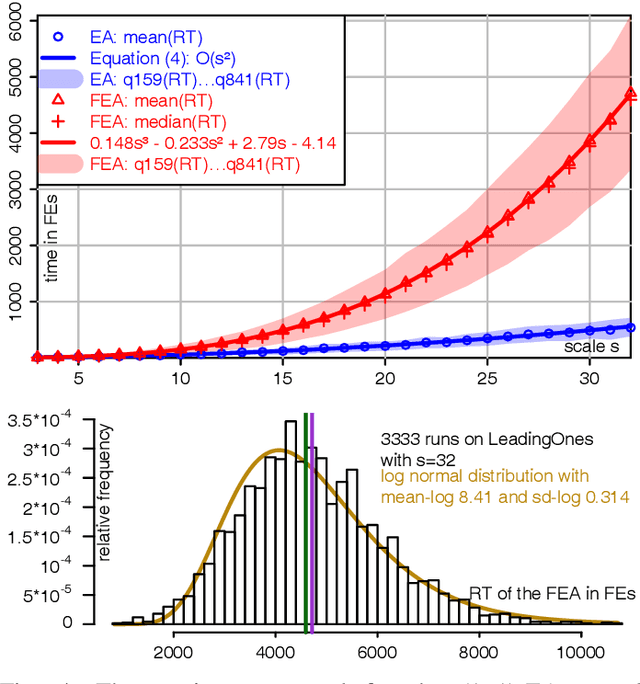
Under Frequency Fitness Assignment (FFA), the fitness corresponding to an objective value is its encounter frequency in fitness assignment steps and is subject to minimization. FFA renders optimization processes invariant under bijective transformations of the objective function. This is the strongest invariance property of any optimization procedure to our knowledge. On TwoMax, Jump, and Trap functions of scale s, a (1+1)-EA with standard mutation at rate 1/s can have expected running times exponential in s. In our experiments, a (1+1)-FEA, the same algorithm but using FFA, exhibits mean running times quadratic in s. Since Jump and Trap are bijective transformations of OneMax, it behaves identical on all three. On the LeadingOnes and Plateau problems, it seems to be slower than the (1+1)-EA by a factor linear in s. The (1+1)-FEA performs much better than the (1+1)-EA on W-Model and MaxSat instances. Due to the bijection invariance, the behavior of an optimization algorithm using FFA does not change when the objective values are encrypted. We verify this by applying the Md5 checksum computation as transformation to some of the above problems and yield the same behaviors. Finally, FFA can improve the performance of a Memetic Algorithm for Job Shop Scheduling.
An Improved Generic Bet-and-Run Strategy for Speeding Up Stochastic Local Search
Jun 23, 2018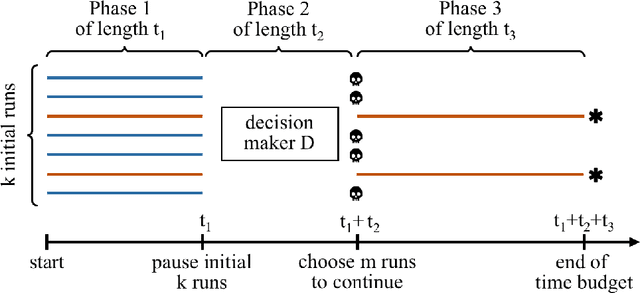
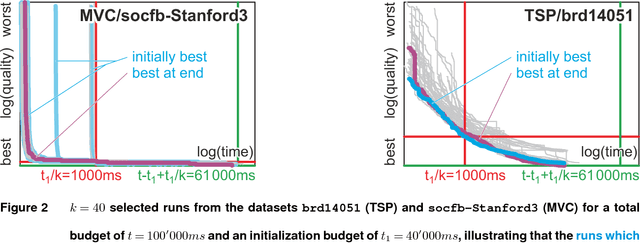
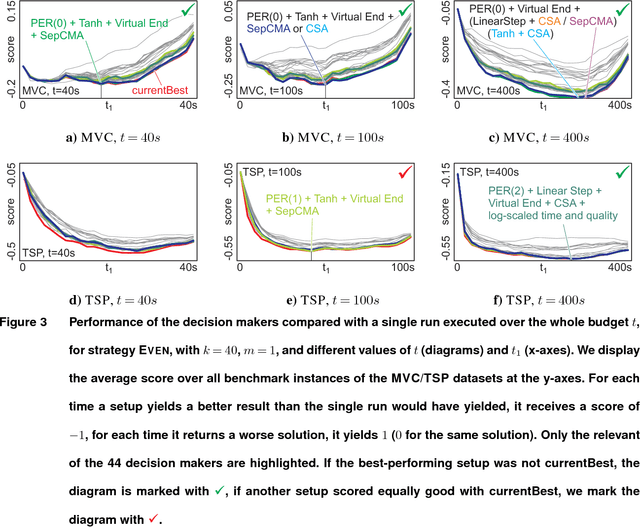
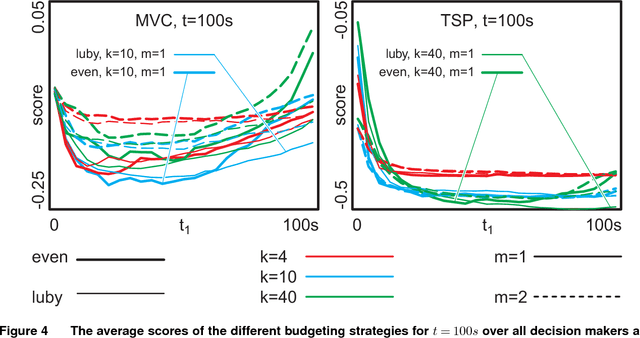
A commonly used strategy for improving optimization algorithms is to restart the algorithm when it is believed to be trapped in an inferior part of the search space. Building on the recent success of Bet-and-Run approaches for restarted local search solvers, we introduce an improved generic Bet-and-Run strategy. The goal is to obtain the best possible results within a given time budget t using a given black-box optimization algorithm. If no prior knowledge about problem features and algorithm behavior is available, the question about how to use the time budget most efficiently arises. We propose to first start k>=1 independent runs of the algorithm during an initialization budget t1<t, pausing these runs, then apply a decision maker D to choose 1<=m<=k runs from them (consuming t2>=0 time units in doing so), and then continuing these runs for the remaining t3=t-t1-t2 time units. In previous Bet-and-Run strategies, the decision maker D=currentBest would simply select the run with the best- so-far results at negligible time. We propose using more advanced methods to discriminate between "good" and "bad" sample runs, with the goal of increasing the correlation of the chosen run with the a-posteriori best one. We test several different approaches, including neural networks trained or polynomials fitted on the current trace of the algorithm to predict which run may yield the best results if granted the remaining budget. We show with extensive experiments that this approach can yield better results than the previous methods, but also find that the currentBest method is a very reliable and robust baseline approach.