 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBONO-Bench: A Comprehensive Test Suite for Bi-objective Numerical Optimization with Traceable Pareto Sets
Jan 23, 2026The evaluation of heuristic optimizers on test problems, better known as \emph{benchmarking}, is a cornerstone of research in multi-objective optimization. However, most test problems used in benchmarking numerical multi-objective black-box optimizers come from one of two flawed approaches: On the one hand, problems are constructed manually, which result in problems with well-understood optimal solutions, but unrealistic properties and biases. On the other hand, more realistic and complex single-objective problems are composited into multi-objective problems, but with a lack of control and understanding of problem properties. This paper proposes an extensive problem generation approach for bi-objective numerical optimization problems consisting of the combination of theoretically well-understood convex-quadratic functions into unimodal and multimodal landscapes with and without global structure. It supports configuration of test problem properties, such as the number of decision variables, local optima, Pareto front shape, plateaus in the objective space, or degree of conditioning, while maintaining theoretical tractability: The optimal front can be approximated to an arbitrary degree of precision regarding Pareto-compliant performance indicators such as the hypervolume or the exact R2 indicator. To demonstrate the generator's capabilities, a test suite of 20 problem categories, called \emph{BONO-Bench}, is created and subsequently used as a basis of an illustrative benchmark study. Finally, the general approach underlying our proposed generator, together with the associated test suite, is publicly released in the Python package \texttt{bonobench} to facilitate reproducible benchmarking.
To Repair or Not to Repair? Investigating the Importance of AB-Cycles for the State-of-the-Art TSP Heuristic EAX
May 01, 2025
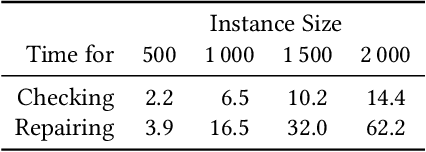


The Edge Assembly Crossover (EAX) algorithm is the state-of-the-art heuristic for solving the Traveling Salesperson Problem (TSP). It regularly outperforms other methods, such as the Lin-Kernighan-Helsgaun heuristic (LKH), across diverse sets of TSP instances. Essentially, EAX employs a two-stage mechanism that focuses on improving the current solutions, first, at the local and, subsequently, at the global level. Although the second phase of the algorithm has been thoroughly studied, configured, and refined in the past, in particular, its first stage has hardly been examined. In this paper, we thus focus on the first stage of EAX and introduce a novel method that quickly verifies whether the AB-cycles, generated during its internal optimization procedure, yield valid tours -- or whether they need to be repaired. Knowledge of the latter is also particularly relevant before applying other powerful crossover operators such as the Generalized Partition Crossover (GPX). Based on our insights, we propose and evaluate several improved versions of EAX. According to our benchmark study across 10 000 different TSP instances, the most promising of our proposed EAX variants demonstrates improved computational efficiency and solution quality on previously rather difficult instances compared to the current state-of-the-art EAX algorithm.
Dancing to the State of the Art? How Candidate Lists Influence LKH for Solving the Traveling Salesperson Problem
Jul 04, 2024Solving the Traveling Salesperson Problem (TSP) remains a persistent challenge, despite its fundamental role in numerous generalized applications in modern contexts. Heuristic solvers address the demand for finding high-quality solutions efficiently. Among these solvers, the Lin-Kernighan-Helsgaun (LKH) heuristic stands out, as it complements the performance of genetic algorithms across a diverse range of problem instances. However, frequent timeouts on challenging instances hinder the practical applicability of the solver. Within this work, we investigate a previously overlooked factor contributing to many timeouts: The use of a fixed candidate set based on a tree structure. Our investigations reveal that candidate sets based on Hamiltonian circuits contain more optimal edges. We thus propose to integrate this promising initialization strategy, in the form of POPMUSIC, within an efficient restart version of LKH. As confirmed by our experimental studies, this refined TSP heuristic is much more efficient - causing fewer timeouts and improving the performance (in terms of penalized average runtime) by an order of magnitude - and thereby challenges the state of the art in TSP solving.
Reinvestigating the R2 Indicator: Achieving Pareto Compliance by Integration
Jul 01, 2024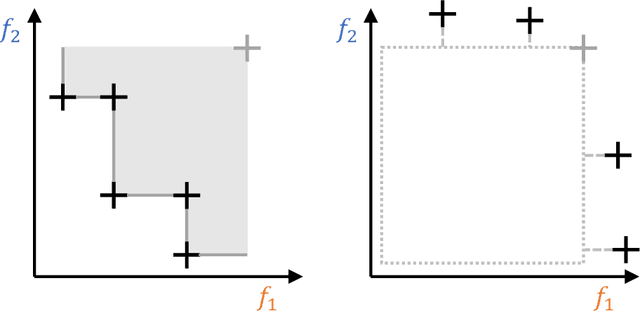


In multi-objective optimization, set-based quality indicators are a cornerstone of benchmarking and performance assessment. They capture the quality of a set of trade-off solutions by reducing it to a scalar number. One of the most commonly used set-based metrics is the R2 indicator, which describes the expected utility of a solution set to a decision-maker under a distribution of utility functions. Typically, this indicator is applied by discretizing this distribution of utility functions, yielding a weakly Pareto-compliant indicator. In consequence, adding a nondominated or dominating solution to a solution set may - but does not have to - improve the indicator's value. In this paper, we reinvestigate the R2 indicator under the premise that we have a continuous, uniform distribution of (Tchebycheff) utility functions. We analyze its properties in detail, demonstrating that this continuous variant is indeed Pareto-compliant - that is, any beneficial solution will improve the metric's value. Additionally, we provide an efficient computational procedure to compute this metric for bi-objective problems in $\mathcal O (N \log N)$. As a result, this work contributes to the state-of-the-art Pareto-compliant unary performance metrics, such as the hypervolume indicator, offering an efficient and promising alternative.
Impact of Training Instance Selection on Automated Algorithm Selection Models for Numerical Black-box Optimization
Apr 11, 2024



The recently proposed MA-BBOB function generator provides a way to create numerical black-box benchmark problems based on the well-established BBOB suite. Initial studies on this generator highlighted its ability to smoothly transition between the component functions, both from a low-level landscape feature perspective, as well as with regard to algorithm performance. This suggests that MA-BBOB-generated functions can be an ideal testbed for automated machine learning methods, such as automated algorithm selection (AAS). In this paper, we generate 11800 functions in dimensions $d=2$ and $d=5$, respectively, and analyze the potential gains from AAS by studying performance complementarity within a set of eight algorithms. We combine this performance data with exploratory landscape features to create an AAS pipeline that we use to investigate how to efficiently select training sets within this space. We show that simply using the BBOB component functions for training yields poor test performance, while the ranking between uniformly chosen and diversity-based training sets strongly depends on the distribution of the test set.
Deep-ELA: Deep Exploratory Landscape Analysis with Self-Supervised Pretrained Transformers for Single- and Multi-Objective Continuous Optimization Problems
Jan 02, 2024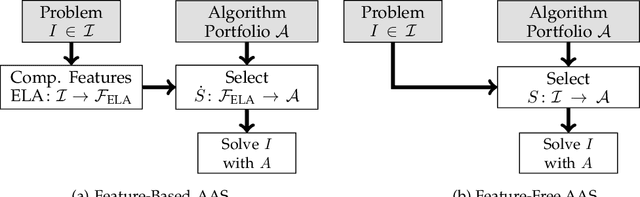
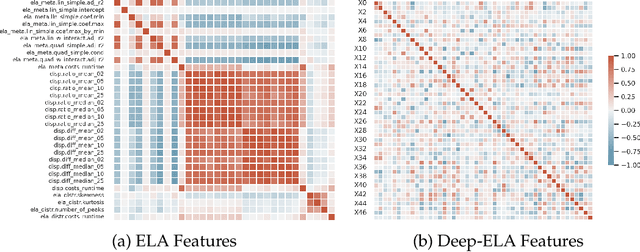
In many recent works, the potential of Exploratory Landscape Analysis (ELA) features to numerically characterize, in particular, single-objective continuous optimization problems has been demonstrated. These numerical features provide the input for all kinds of machine learning tasks on continuous optimization problems, ranging, i.a., from High-level Property Prediction to Automated Algorithm Selection and Automated Algorithm Configuration. Without ELA features, analyzing and understanding the characteristics of single-objective continuous optimization problems would be impossible. Yet, despite their undisputed usefulness, ELA features suffer from several drawbacks. These include, in particular, (1.) a strong correlation between multiple features, as well as (2.) its very limited applicability to multi-objective continuous optimization problems. As a remedy, recent works proposed deep learning-based approaches as alternatives to ELA. In these works, e.g., point-cloud transformers were used to characterize an optimization problem's fitness landscape. However, these approaches require a large amount of labeled training data. Within this work, we propose a hybrid approach, Deep-ELA, which combines (the benefits of) deep learning and ELA features. Specifically, we pre-trained four transformers on millions of randomly generated optimization problems to learn deep representations of the landscapes of continuous single- and multi-objective optimization problems. Our proposed framework can either be used out-of-the-box for analyzing single- and multi-objective continuous optimization problems, or subsequently fine-tuned to various tasks focussing on algorithm behavior and problem understanding.
Tools for Landscape Analysis of Optimisation Problems in Procedural Content Generation for Games
Feb 16, 2023



The term Procedural Content Generation (PCG) refers to the (semi-)automatic generation of game content by algorithmic means, and its methods are becoming increasingly popular in game-oriented research and industry. A special class of these methods, which is commonly known as search-based PCG, treats the given task as an optimisation problem. Such problems are predominantly tackled by evolutionary algorithms. We will demonstrate in this paper that obtaining more information about the defined optimisation problem can substantially improve our understanding of how to approach the generation of content. To do so, we present and discuss three efficient analysis tools, namely diagonal walks, the estimation of high-level properties, as well as problem similarity measures. We discuss the purpose of each of the considered methods in the context of PCG and provide guidelines for the interpretation of the results received. This way we aim to provide methods for the comparison of PCG approaches and eventually, increase the quality and practicality of generated content in industry.
Mixture of Decision Trees for Interpretable Machine Learning
Nov 26, 2022This work introduces a novel interpretable machine learning method called Mixture of Decision Trees (MoDT). It constitutes a special case of the Mixture of Experts ensemble architecture, which utilizes a linear model as gating function and decision trees as experts. Our proposed method is ideally suited for problems that cannot be satisfactorily learned by a single decision tree, but which can alternatively be divided into subproblems. Each subproblem can then be learned well from a single decision tree. Therefore, MoDT can be considered as a method that improves performance while maintaining interpretability by making each of its decisions understandable and traceable to humans. Our work is accompanied by a Python implementation, which uses an interpretable gating function, a fast learning algorithm, and a direct interface to fine-tuned interpretable visualization methods. The experiments confirm that the implementation works and, more importantly, show the superiority of our approach compared to single decision trees and random forests of similar complexity.
HPO X ELA: Investigating Hyperparameter Optimization Landscapes by Means of Exploratory Landscape Analysis
Jul 30, 2022
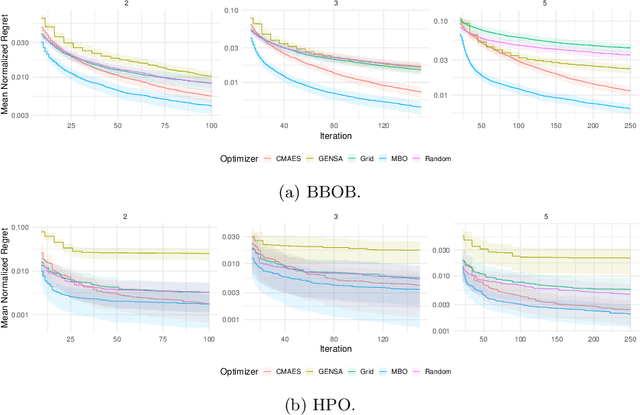

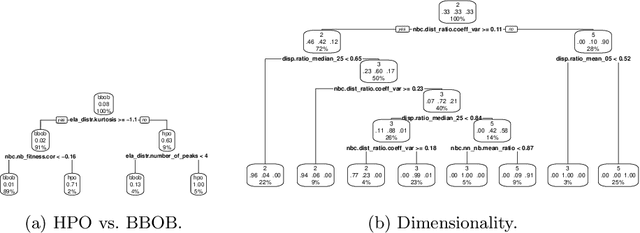
Hyperparameter optimization (HPO) is a key component of machine learning models for achieving peak predictive performance. While numerous methods and algorithms for HPO have been proposed over the last years, little progress has been made in illuminating and examining the actual structure of these black-box optimization problems. Exploratory landscape analysis (ELA) subsumes a set of techniques that can be used to gain knowledge about properties of unknown optimization problems. In this paper, we evaluate the performance of five different black-box optimizers on 30 HPO problems, which consist of two-, three- and five-dimensional continuous search spaces of the XGBoost learner trained on 10 different data sets. This is contrasted with the performance of the same optimizers evaluated on 360 problem instances from the black-box optimization benchmark (BBOB). We then compute ELA features on the HPO and BBOB problems and examine similarities and differences. A cluster analysis of the HPO and BBOB problems in ELA feature space allows us to identify how the HPO problems compare to the BBOB problems on a structural meta-level. We identify a subset of BBOB problems that are close to the HPO problems in ELA feature space and show that optimizer performance is comparably similar on these two sets of benchmark problems. We highlight open challenges of ELA for HPO and discuss potential directions of future research and applications.
MOLE: Digging Tunnels Through Multimodal Multi-Objective Landscapes
Apr 22, 2022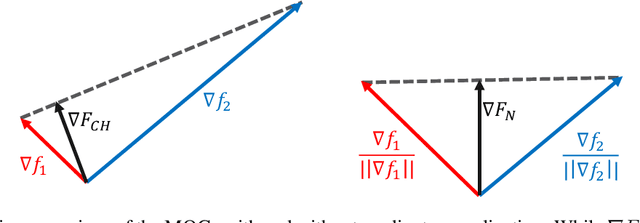
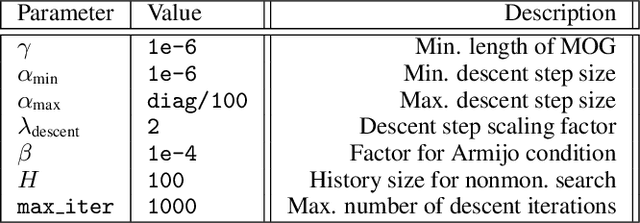

Recent advances in the visualization of continuous multimodal multi-objective optimization (MMMOO) landscapes brought a new perspective to their search dynamics. Locally efficient (LE) sets, often considered as traps for local search, are rarely isolated in the decision space. Rather, intersections by superposing attraction basins lead to further solution sets that at least partially contain better solutions. The Multi-Objective Gradient Sliding Algorithm (MOGSA) is an algorithmic concept developed to exploit these superpositions. While it has promising performance on many MMMOO problems with linear LE sets, closer analysis of MOGSA revealed that it does not sufficiently generalize to a wider set of test problems. Based on a detailed analysis of shortcomings of MOGSA, we propose a new algorithm, the Multi-Objective Landscape Explorer (MOLE). It is able to efficiently model and exploit LE sets in MMMOO problems. An implementation of MOLE is presented for the bi-objective case, and the practicality of the approach is shown in a benchmarking experiment on the Bi-Objective BBOB testbed.