 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Decision Trees for Interpretable Machine Learning
Nov 26, 2022This work introduces a novel interpretable machine learning method called Mixture of Decision Trees (MoDT). It constitutes a special case of the Mixture of Experts ensemble architecture, which utilizes a linear model as gating function and decision trees as experts. Our proposed method is ideally suited for problems that cannot be satisfactorily learned by a single decision tree, but which can alternatively be divided into subproblems. Each subproblem can then be learned well from a single decision tree. Therefore, MoDT can be considered as a method that improves performance while maintaining interpretability by making each of its decisions understandable and traceable to humans. Our work is accompanied by a Python implementation, which uses an interpretable gating function, a fast learning algorithm, and a direct interface to fine-tuned interpretable visualization methods. The experiments confirm that the implementation works and, more importantly, show the superiority of our approach compared to single decision trees and random forests of similar complexity.
Towards Measuring Bias in Image Classification
Jul 01, 2021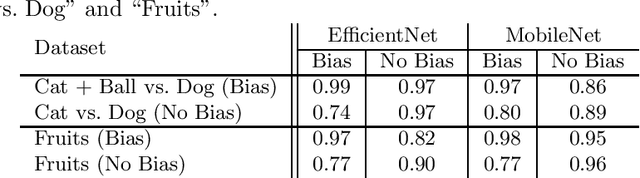

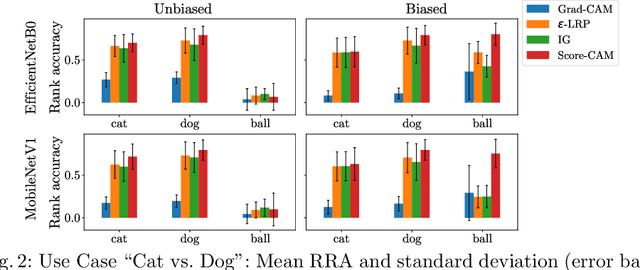

Convolutional Neural Networks (CNN) have become de fact state-of-the-art for the main computer vision tasks. However, due to the complex underlying structure their decisions are hard to understand which limits their use in some context of the industrial world. A common and hard to detect challenge in machine learning (ML) tasks is data bias. In this work, we present a systematic approach to uncover data bias by means of attribution maps. For this purpose, first an artificial dataset with a known bias is created and used to train intentionally biased CNNs. The networks' decisions are then inspected using attribution maps. Finally, meaningful metrics are used to measure the attribution maps' representativeness with respect to the known bias. The proposed study shows that some attribution map techniques highlight the presence of bias in the data better than others and metrics can support the identification of bias.
Enhancing Decision Tree based Interpretation of Deep Neural Networks through L1-Orthogonal Regularization
Apr 10, 2019

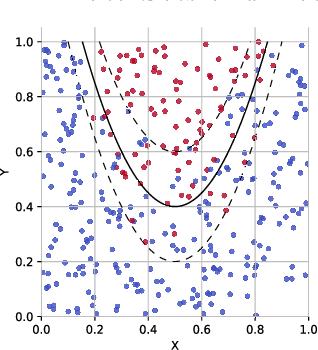
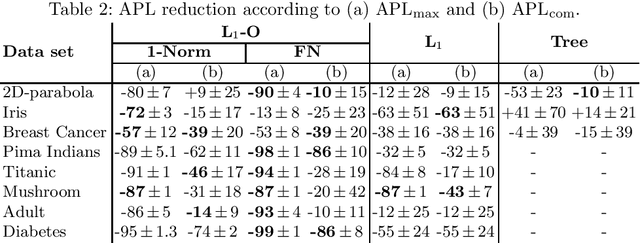
One obstacle that so far prevents the introduction of machine learning models primarily in critical areas is the lack of explainability. In this work, a practicable approach of gaining explainability of deep artificial neural networks (NN) using an interpretable surrogate model based on decision trees is presented. Simply fitting a decision tree to a trained NN usually leads to unsatisfactory results in terms of accuracy and fidelity. Using \Lo-orthogonal regularization during training, however, preserves the accuracy of the NN, while it can be closely approximated by small decision trees. Tests with different data sets confirm that \Lo-orthogonal regularization yields models of lower complexity and at the same time higher fidelity compared to other regularizers.