 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Repair or Not to Repair? Investigating the Importance of AB-Cycles for the State-of-the-Art TSP Heuristic EAX
May 01, 2025
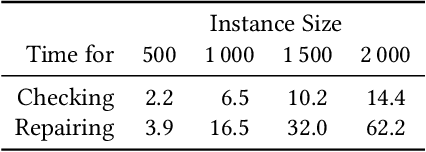


The Edge Assembly Crossover (EAX) algorithm is the state-of-the-art heuristic for solving the Traveling Salesperson Problem (TSP). It regularly outperforms other methods, such as the Lin-Kernighan-Helsgaun heuristic (LKH), across diverse sets of TSP instances. Essentially, EAX employs a two-stage mechanism that focuses on improving the current solutions, first, at the local and, subsequently, at the global level. Although the second phase of the algorithm has been thoroughly studied, configured, and refined in the past, in particular, its first stage has hardly been examined. In this paper, we thus focus on the first stage of EAX and introduce a novel method that quickly verifies whether the AB-cycles, generated during its internal optimization procedure, yield valid tours -- or whether they need to be repaired. Knowledge of the latter is also particularly relevant before applying other powerful crossover operators such as the Generalized Partition Crossover (GPX). Based on our insights, we propose and evaluate several improved versions of EAX. According to our benchmark study across 10 000 different TSP instances, the most promising of our proposed EAX variants demonstrates improved computational efficiency and solution quality on previously rather difficult instances compared to the current state-of-the-art EAX algorithm.
Iterated Local Search with Linkage Learning
Oct 02, 2024In pseudo-Boolean optimization, a variable interaction graph represents variables as vertices, and interactions between pairs of variables as edges. In black-box optimization, the variable interaction graph may be at least partially discovered by using empirical linkage learning techniques. These methods never report false variable interactions, but they are computationally expensive. The recently proposed local search with linkage learning discovers the partial variable interaction graph as a side-effect of iterated local search. However, information about the strength of the interactions is not learned by the algorithm. We propose local search with linkage learning 2, which builds a weighted variable interaction graph that stores information about the strength of the interaction between variables. The weighted variable interaction graph can provide new insights about the optimization problem and behavior of optimizers. Experiments with NK landscapes, knapsack problem, and feature selection show that local search with linkage learning 2 is able to efficiently build weighted variable interaction graphs. In particular, experiments with feature selection show that the weighted variable interaction graphs can be used for visualizing the feature interactions in machine learning. Additionally, new transformation operators that exploit the interactions between variables can be designed. We illustrate this ability by proposing a new perturbation operator for iterated local search.
Generalizing and Unifying Gray-box Combinatorial Optimization Operators
Jul 09, 2024Gray-box optimization leverages the information available about the mathematical structure of an optimization problem to design efficient search operators. Efficient hill climbers and crossover operators have been proposed in the domain of pseudo-Boolean optimization and also in some permutation problems. However, there is no general rule on how to design these efficient operators in different representation domains. This paper proposes a general framework that encompasses all known gray-box operators for combinatorial optimization problems. The framework is general enough to shed light on the design of new efficient operators for new problems and representation domains. We also unify the proofs of efficiency for gray-box hill climbers and crossovers and show that the mathematical property explaining the speed-up of gray-box crossover operators, also explains the efficient identification of improving moves in gray-box hill climbers. We illustrate the power of the new framework by proposing an efficient hill climber and crossover for two related permutation problems: the Linear Ordering Problem and the Single Machine Total Weighted Tardiness Problem.
Dancing to the State of the Art? How Candidate Lists Influence LKH for Solving the Traveling Salesperson Problem
Jul 04, 2024Solving the Traveling Salesperson Problem (TSP) remains a persistent challenge, despite its fundamental role in numerous generalized applications in modern contexts. Heuristic solvers address the demand for finding high-quality solutions efficiently. Among these solvers, the Lin-Kernighan-Helsgaun (LKH) heuristic stands out, as it complements the performance of genetic algorithms across a diverse range of problem instances. However, frequent timeouts on challenging instances hinder the practical applicability of the solver. Within this work, we investigate a previously overlooked factor contributing to many timeouts: The use of a fixed candidate set based on a tree structure. Our investigations reveal that candidate sets based on Hamiltonian circuits contain more optimal edges. We thus propose to integrate this promising initialization strategy, in the form of POPMUSIC, within an efficient restart version of LKH. As confirmed by our experimental studies, this refined TSP heuristic is much more efficient - causing fewer timeouts and improving the performance (in terms of penalized average runtime) by an order of magnitude - and thereby challenges the state of the art in TSP solving.
NK Hybrid Genetic Algorithm for Clustering
Feb 06, 2024


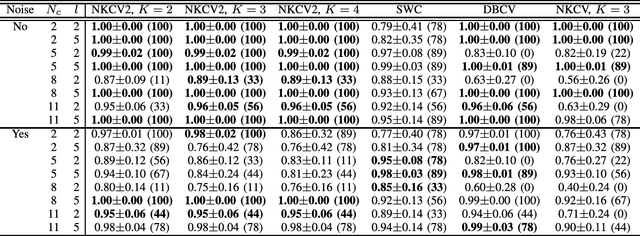
The NK hybrid genetic algorithm for clustering is proposed in this paper. In order to evaluate the solutions, the hybrid algorithm uses the NK clustering validation criterion 2 (NKCV2). NKCV2 uses information about the disposition of $N$ small groups of objects. Each group is composed of $K+1$ objects of the dataset. Experimental results show that density-based regions can be identified by using NKCV2 with fixed small $K$. In NKCV2, the relationship between decision variables is known, which in turn allows us to apply gray box optimization. Mutation operators, a partition crossover, and a local search strategy are proposed, all using information about the relationship between decision variables. In partition crossover, the evaluation function is decomposed into $q$ independent components; partition crossover then deterministically returns the best among $2^q$ possible offspring with computational complexity $O(N)$. The NK hybrid genetic algorithm allows the detection of clusters with arbitrary shapes and the automatic estimation of the number of clusters. In the experiments, the NK hybrid genetic algorithm produced very good results when compared to another genetic algorithm approach and to state-of-art clustering algorithms.
Dynastic Potential Crossover Operator
Feb 06, 2024An optimal recombination operator for two parent solutions provides the best solution among those that take the value for each variable from one of the parents (gene transmission property). If the solutions are bit strings, the offspring of an optimal recombination operator is optimal in the smallest hyperplane containing the two parent solutions. Exploring this hyperplane is computationally costly, in general, requiring exponential time in the worst case. However, when the variable interaction graph of the objective function is sparse, exploration can be done in polynomial time. In this paper, we present a recombination operator, called Dynastic Potential Crossover (DPX), that runs in polynomial time and behaves like an optimal recombination operator for low-epistasis combinatorial problems. We compare this operator, both theoretically and experimentally, with traditional crossover operators, like uniform crossover and network crossover, and with two recently defined efficient recombination operators: partition crossover and articulation points partition crossover. The empirical comparison uses NKQ Landscapes and MAX-SAT instances. DPX outperforms the other crossover operators in terms of quality of the offspring and provides better results included in a trajectory and a population-based metaheuristic, but it requires more time and memory to compute the offspring.
Stochastic Subnetwork Annealing: A Regularization Technique for Fine Tuning Pruned Subnetworks
Jan 16, 2024Pruning methods have recently grown in popularity as an effective way to reduce the size and computational complexity of deep neural networks. Large numbers of parameters can be removed from trained models with little discernible loss in accuracy after a small number of continued training epochs. However, pruning too many parameters at once often causes an initial steep drop in accuracy which can undermine convergence quality. Iterative pruning approaches mitigate this by gradually removing a small number of parameters over multiple epochs. However, this can still lead to subnetworks that overfit local regions of the loss landscape. We introduce a novel and effective approach to tuning subnetworks through a regularization technique we call Stochastic Subnetwork Annealing. Instead of removing parameters in a discrete manner, we instead represent subnetworks with stochastic masks where each parameter has a probabilistic chance of being included or excluded on any given forward pass. We anneal these probabilities over time such that subnetwork structure slowly evolves as mask values become more deterministic, allowing for a smoother and more robust optimization of subnetworks at high levels of sparsity.
A Parallel Ensemble of Metaheuristic Solvers for the Traveling Salesman Problem
Aug 13, 2023The travelling salesman problem (TSP) is one of the well-studied NP-hard problems in the literature. The state-of-the art inexact TSP solvers are the Lin-Kernighan-Helsgaun (LKH) heuristic and Edge Assembly crossover (EAX). A recent study suggests that EAX with restart mechanisms perform well on a wide range of TSP instances. However, this study is limited to 2,000 city problems. We study for problems ranging from 2,000 to 85,900. We see that the performance of the solver varies with the type of the problem. However, combining these solvers in an ensemble setup, we are able to outperform the individual solver's performance. We see the ensemble setup as an efficient way to make use of the abundance of compute resources. In addition to EAX and LKH, we use several versions of the hybrid of EAX and Mixing Genetic Algorithm (MGA). A hybrid of MGA and EAX is known to solve some hard problems. We see that the ensemble of the hybrid version outperforms the state-of-the-art solvers on problems larger than 10,000 cities.
Randomly Initialized Subnetworks with Iterative Weight Recycling
Mar 28, 2023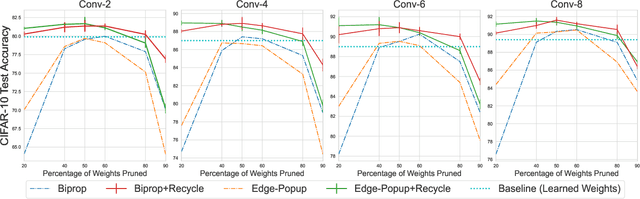
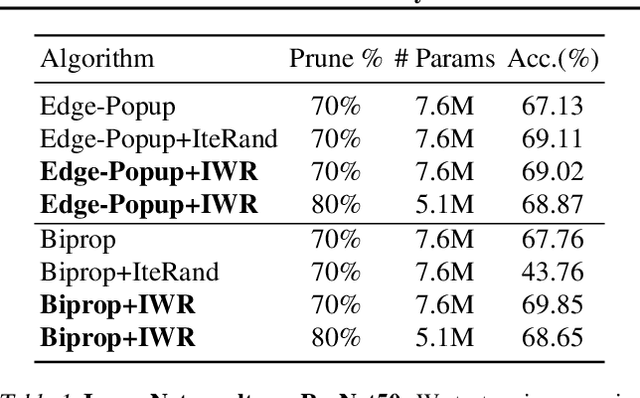
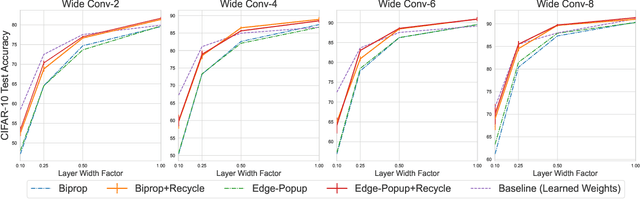
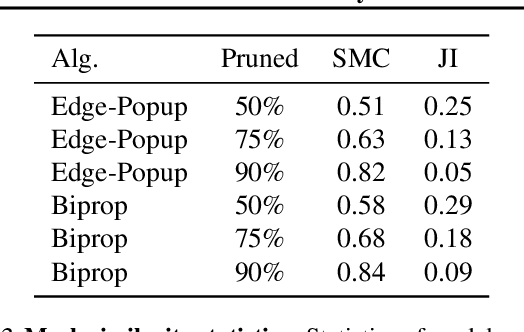
The Multi-Prize Lottery Ticket Hypothesis posits that randomly initialized neural networks contain several subnetworks that achieve comparable accuracy to fully trained models of the same architecture. However, current methods require that the network is sufficiently overparameterized. In this work, we propose a modification to two state-of-the-art algorithms (Edge-Popup and Biprop) that finds high-accuracy subnetworks with no additional storage cost or scaling. The algorithm, Iterative Weight Recycling, identifies subsets of important weights within a randomly initialized network for intra-layer reuse. Empirically we show improvements on smaller network architectures and higher prune rates, finding that model sparsity can be increased through the "recycling" of existing weights. In addition to Iterative Weight Recycling, we complement the Multi-Prize Lottery Ticket Hypothesis with a reciprocal finding: high-accuracy, randomly initialized subnetwork's produce diverse masks, despite being generated with the same hyperparameter's and pruning strategy. We explore the landscapes of these masks, which show high variability.
Interpretable Diversity Analysis: Visualizing Feature Representations In Low-Cost Ensembles
Feb 12, 2023



Diversity is an important consideration in the construction of robust neural network ensembles. A collection of well trained models will generalize better if they are diverse in the patterns they respond to and the predictions they make. Diversity is especially important for low-cost ensemble methods because members often share network structure in order to avoid training several independent models from scratch. Diversity is traditionally analyzed by measuring differences between the outputs of models. However, this gives little insight into how knowledge representations differ between ensemble members. This paper introduces several interpretability methods that can be used to qualitatively analyze diversity. We demonstrate these techniques by comparing the diversity of feature representations between child networks using two low-cost ensemble algorithms, Snapshot Ensembles and Prune and Tune Ensembles. We use the same pre-trained parent network as a starting point for both methods which allows us to explore how feature representations evolve over time. This approach to diversity analysis can lead to valuable insights and new perspectives for how we measure and promote diversity in ensemble methods.