 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Integer Linear Programming approach for Automatic Software Cognitive Complexity Reduction
Jan 29, 2026Clear and concise code is necessary to ensure maintainability, so it is crucial that the software is as simple as possible to understand, to avoid bugs and, above all, vulnerabilities. There are many ways to enhance software without changing its functionality, considering the extract method refactoring the primary process to reduce the effort required for code comprehension. The cognitive complexity measure employed in this work is the one defined by SonarSource, which is a company that develops well-known applications for static code analysis. This extraction problem can be modeled as a combinatorial optimization problem. The main difficulty arises from the existence of different criteria for evaluating the solutions obtained, requiring the formulation of the code extraction problem as a multi-objective optimization problem using alternative methods. We propose a multi-objective integer linear programming model to obtain a set of solutions that reduce the cognitive complexity of a given piece of code, such as balancing the number of lines of code and its cognitive complexity. In addition, several algorithms have been developed to validate the model. These algorithms have been integrated into a tool that enables the parameterised resolution of the problem of reducing software cognitive complexity.
Generate more than one child in your co-evolutionary semi-supervised learning GAN
Apr 29, 2025Generative Adversarial Networks (GANs) are very useful methods to address semi-supervised learning (SSL) datasets, thanks to their ability to generate samples similar to real data. This approach, called SSL-GAN has attracted many researchers in the last decade. Evolutionary algorithms have been used to guide the evolution and training of SSL-GANs with great success. In particular, several co-evolutionary approaches have been applied where the two networks of a GAN (the generator and the discriminator) are evolved in separate populations. The co-evolutionary approaches published to date assume some spatial structure of the populations, based on the ideas of cellular evolutionary algorithms. They also create one single individual per generation and follow a generational replacement strategy in the evolution. In this paper, we re-consider those algorithmic design decisions and propose a new co-evolutionary approach, called Co-evolutionary Elitist SSL-GAN (CE-SSLGAN), with panmictic population, elitist replacement, and more than one individual in the offspring. We evaluate the performance of our proposed method using three standard benchmark datasets. The results show that creating more than one offspring per population and using elitism improves the results in comparison with a classical SSL-GAN.
Iterated Local Search with Linkage Learning
Oct 02, 2024In pseudo-Boolean optimization, a variable interaction graph represents variables as vertices, and interactions between pairs of variables as edges. In black-box optimization, the variable interaction graph may be at least partially discovered by using empirical linkage learning techniques. These methods never report false variable interactions, but they are computationally expensive. The recently proposed local search with linkage learning discovers the partial variable interaction graph as a side-effect of iterated local search. However, information about the strength of the interactions is not learned by the algorithm. We propose local search with linkage learning 2, which builds a weighted variable interaction graph that stores information about the strength of the interaction between variables. The weighted variable interaction graph can provide new insights about the optimization problem and behavior of optimizers. Experiments with NK landscapes, knapsack problem, and feature selection show that local search with linkage learning 2 is able to efficiently build weighted variable interaction graphs. In particular, experiments with feature selection show that the weighted variable interaction graphs can be used for visualizing the feature interactions in machine learning. Additionally, new transformation operators that exploit the interactions between variables can be designed. We illustrate this ability by proposing a new perturbation operator for iterated local search.
Generalizing and Unifying Gray-box Combinatorial Optimization Operators
Jul 09, 2024Gray-box optimization leverages the information available about the mathematical structure of an optimization problem to design efficient search operators. Efficient hill climbers and crossover operators have been proposed in the domain of pseudo-Boolean optimization and also in some permutation problems. However, there is no general rule on how to design these efficient operators in different representation domains. This paper proposes a general framework that encompasses all known gray-box operators for combinatorial optimization problems. The framework is general enough to shed light on the design of new efficient operators for new problems and representation domains. We also unify the proofs of efficiency for gray-box hill climbers and crossovers and show that the mathematical property explaining the speed-up of gray-box crossover operators, also explains the efficient identification of improving moves in gray-box hill climbers. We illustrate the power of the new framework by proposing an efficient hill climber and crossover for two related permutation problems: the Linear Ordering Problem and the Single Machine Total Weighted Tardiness Problem.
CMSA algorithm for solving the prioritized pairwise test data generation problem in software product lines
Feb 07, 2024In Software Product Lines (SPLs) it may be difficult or even impossible to test all the products of the family because of the large number of valid feature combinations that may exist. Thus, we want to find a minimal subset of the product family that allows us to test all these possible combinations (pairwise). Furthermore, when testing a single product is a great effort, it is desirable to first test products composed of a set of priority features. This problem is called Prioritized Pairwise Test Data Generation Problem. State-of-the-art algorithms based on Integer Linear Programming for this problema are faster enough for small and medium instances. However, there exists some real instances that are too large to be computed with these algorithms in a reasonable time because of the exponential growth of the number of candidate solutions. Also, these heuristics not always lead us to the best solutions. In this work we propose a new approach based on a hybrid metaheuristic algorithm called Construct, Merge, Solve & Adapt. We compare this matheuristic with four algorithms: a Hybrid algorithm based on Integer Linear Programming ((HILP), a Hybrid algorithm based on Integer Nonlinear Programming (HINLP), the Parallel Prioritized Genetic Solver (PPGS), and a greedy algorithm called prioritized-ICPL. The analysis reveals that CMSA results in statistically significantly better quality solutions in most instances and for most levels of weighted coverage, although it requires more execution time.
* Preprint of the submitted version of the article in Journal of Heuristics
Using metaheuristics for the location of bicycle stations
Feb 06, 2024In this work, we solve the problem of finding the best locations to place stations for depositing/collecting shared bicycles. To do this, we model the problem as the p-median problem, that is a major existing localization problem in optimization. The p-median problem seeks to place a set of facilities (bicycle stations) in a way that minimizes the distance between a set of clients (citizens) and their closest facility (bike station). We have used a genetic algorithm, iterated local search, particle swarm optimization, simulated annealing, and variable neighbourhood search, to find the best locations for the bicycle stations and study their comparative advantages. We use irace to parameterize each algorithm automatically, to contribute with a methodology to fine-tune algorithms automatically. We have also studied different real data (distance and weights) from diverse open data sources from a real city, Malaga (Spain), hopefully leading to a final smart city application. We have compared our results with the implemented solution in Malaga. Finally, we have analyzed how we can use our proposal to improve the existing system in the city by adding more stations.
NK Hybrid Genetic Algorithm for Clustering
Feb 06, 2024


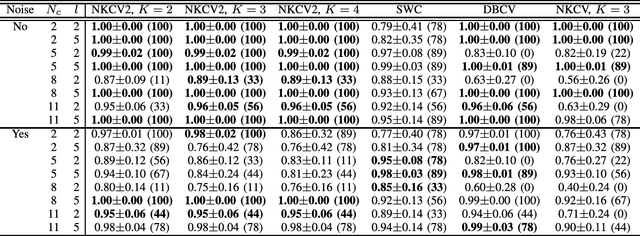
The NK hybrid genetic algorithm for clustering is proposed in this paper. In order to evaluate the solutions, the hybrid algorithm uses the NK clustering validation criterion 2 (NKCV2). NKCV2 uses information about the disposition of $N$ small groups of objects. Each group is composed of $K+1$ objects of the dataset. Experimental results show that density-based regions can be identified by using NKCV2 with fixed small $K$. In NKCV2, the relationship between decision variables is known, which in turn allows us to apply gray box optimization. Mutation operators, a partition crossover, and a local search strategy are proposed, all using information about the relationship between decision variables. In partition crossover, the evaluation function is decomposed into $q$ independent components; partition crossover then deterministically returns the best among $2^q$ possible offspring with computational complexity $O(N)$. The NK hybrid genetic algorithm allows the detection of clusters with arbitrary shapes and the automatic estimation of the number of clusters. In the experiments, the NK hybrid genetic algorithm produced very good results when compared to another genetic algorithm approach and to state-of-art clustering algorithms.
Dynastic Potential Crossover Operator
Feb 06, 2024An optimal recombination operator for two parent solutions provides the best solution among those that take the value for each variable from one of the parents (gene transmission property). If the solutions are bit strings, the offspring of an optimal recombination operator is optimal in the smallest hyperplane containing the two parent solutions. Exploring this hyperplane is computationally costly, in general, requiring exponential time in the worst case. However, when the variable interaction graph of the objective function is sparse, exploration can be done in polynomial time. In this paper, we present a recombination operator, called Dynastic Potential Crossover (DPX), that runs in polynomial time and behaves like an optimal recombination operator for low-epistasis combinatorial problems. We compare this operator, both theoretically and experimentally, with traditional crossover operators, like uniform crossover and network crossover, and with two recently defined efficient recombination operators: partition crossover and articulation points partition crossover. The empirical comparison uses NKQ Landscapes and MAX-SAT instances. DPX outperforms the other crossover operators in terms of quality of the offspring and provides better results included in a trajectory and a population-based metaheuristic, but it requires more time and memory to compute the offspring.
Optimising Communication Overhead in Federated Learning Using NSGA-II
Apr 01, 2022

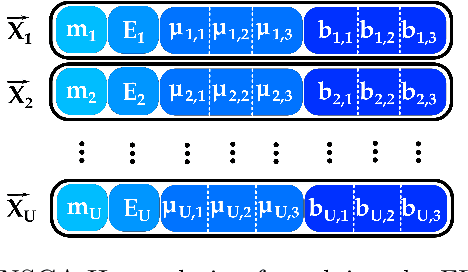
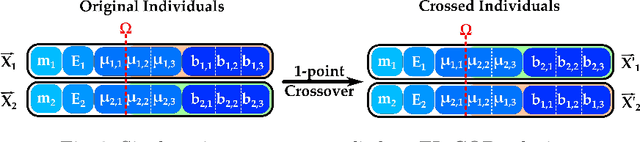
Federated learning is a training paradigm according to which a server-based model is cooperatively trained using local models running on edge devices and ensuring data privacy. These devices exchange information that induces a substantial communication load, which jeopardises the functioning efficiency. The difficulty of reducing this overhead stands in achieving this without decreasing the model's efficiency (contradictory relation). To do so, many works investigated the compression of the pre/mid/post-trained models and the communication rounds, separately, although they jointly contribute to the communication overload. Our work aims at optimising communication overhead in federated learning by (I) modelling it as a multi-objective problem and (II) applying a multi-objective optimization algorithm (NSGA-II) to solve it. To the best of the author's knowledge, this is the first work that \texttt{(I)} explores the add-in that evolutionary computation could bring for solving such a problem, and \texttt{(II)} considers both the neuron and devices features together. We perform the experimentation by simulating a server/client architecture with 4 slaves. We investigate both convolutional and fully-connected neural networks with 12 and 3 layers, 887,530 and 33,400 weights, respectively. We conducted the validation on the \texttt{MNIST} dataset containing 70,000 images. The experiments have shown that our proposal could reduce communication by 99% and maintain an accuracy equal to the one obtained by the FedAvg Algorithm that uses 100% of communications.
Efficient Hill-Climber for Multi-Objective Pseudo-Boolean Optimization
Jan 27, 2016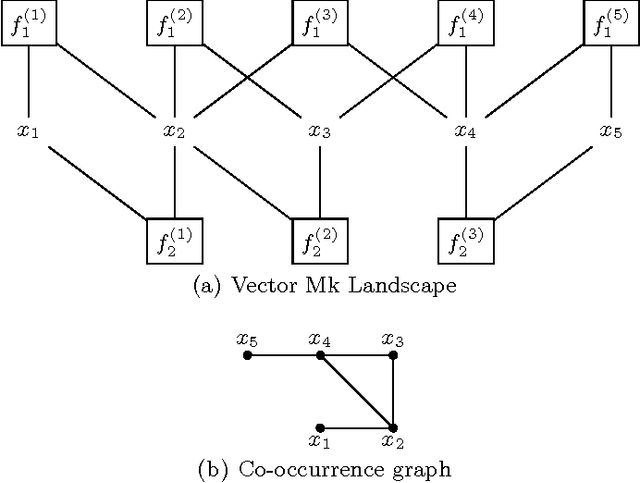
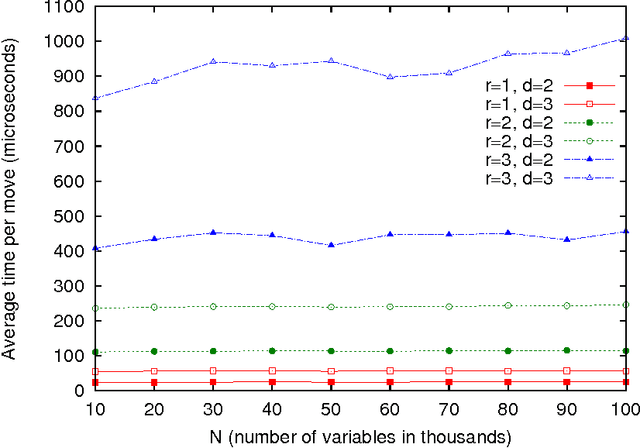
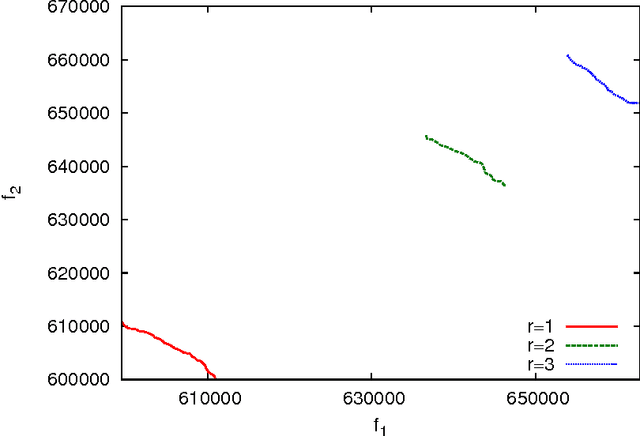
Local search algorithms and iterated local search algorithms are a basic technique. Local search can be a stand along search methods, but it can also be hybridized with evolutionary algorithms. Recently, it has been shown that it is possible to identify improving moves in Hamming neighborhoods for k-bounded pseudo-Boolean optimization problems in constant time. This means that local search does not need to enumerate neighborhoods to find improving moves. It also means that evolutionary algorithms do not need to use random mutation as a operator, except perhaps as a way to escape local optima. In this paper, we show how improving moves can be identified in constant time for multiobjective problems that are expressed as k-bounded pseudo-Boolean functions. In particular, multiobjective forms of NK Landscapes and Mk Landscapes are considered.