 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Knowledge Distribution among Software Development Teams -- Observations from Open-Source and Closed-Source Software Development
Jul 26, 2022


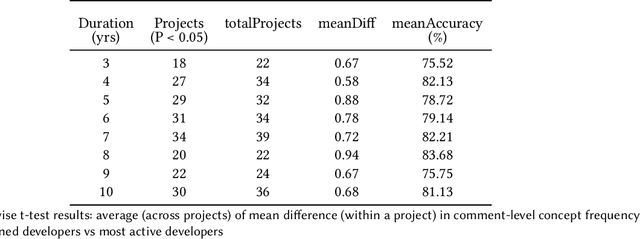
In software development teams, developer turnover is among the primary reasons for project failures as it leads to a great void of knowledge and strain for the newcomers. Unfortunately, no established methods exist to measure how knowledge is distributed among development teams. Knowing how this knowledge evolves and is owned by key developers in a project helps managers reduce risks caused by turnover. To this end, this paper introduces a novel, realistic representation of domain knowledge distribution: the ConceptRealm. To construct the ConceptRealm, we employ a latent Dirichlet allocation model to represent textual features obtained from 300k issues and 1.3M comments from 518 open-source projects. We analyze whether the newly emerged issues and developers share similar concepts or how aligned the developers' concepts are with the team over time. We also investigate the impact of leaving members on the frequency of concepts. Finally, we evaluate the soundness of our approach to closed-source software, thus allowing the validation of the results from a practical standpoint. We find out that the ConceptRealm can represent the high-level domain knowledge within a team and can be utilized to predict the alignment of developers with issues. We also observe that projects exhibit many keepers independent of project maturity and that abruptly leaving keepers harm the team's concept familiarity.
Semantic Clone Detection via Probabilistic Software Modeling
Aug 11, 2020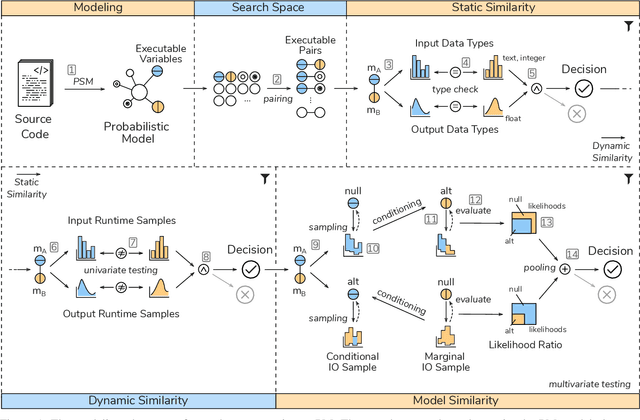
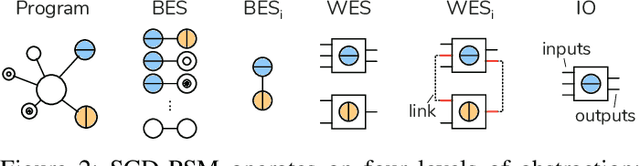
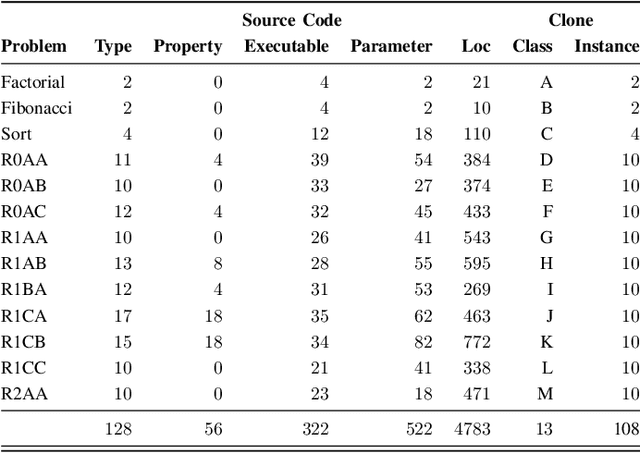
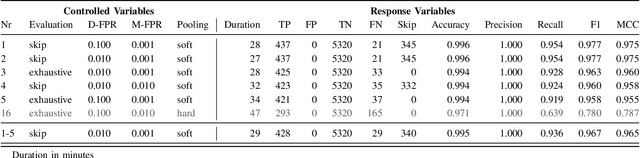
Semantic clone detection is the process of finding program elements with similar or equal runtime behavior. For example, detecting the semantic equality between the recursive and iterative implementation of the factorial computation. Semantic clone detection is the de facto technical boundary of clone detectors. This boundary was tested over the last years with interesting new approaches. This work contributes a semantic clone detection approach that detects clones with 0% syntactic similarity. We present Semantic Clone Detection via Probabilistic Software Modeling (SCD-PSM) as a stable and precise solution to semantic clone detection. PSM builds a probabilistic model of a program that is capable of evaluating and generating runtime data. SCD-PSM leverages this model and its model elements to finding behaviorally equal model elements. This behavioral equality is then generalized to semantic equality of the original program elements. It uses the likelihood between model elements as a distance metric. Then, it employs the likelihood ratio significance test to decide whether this distance is significant, given a pre-specified and controllable false-positive rate. The output of SCD-PSM are pairs of program elements (i.e., methods), their distance, and a decision whether they are clones or not. SCD-PSM yields excellent results with a Matthews Correlation Coefficient greater 0.9. These results are obtained on classical semantic clone detection problems such as detecting recursive and iterative versions of an algorithm, but also on complex problems used in coding competitions.
Machine Learning for Software Engineering: A Systematic Mapping
May 27, 2020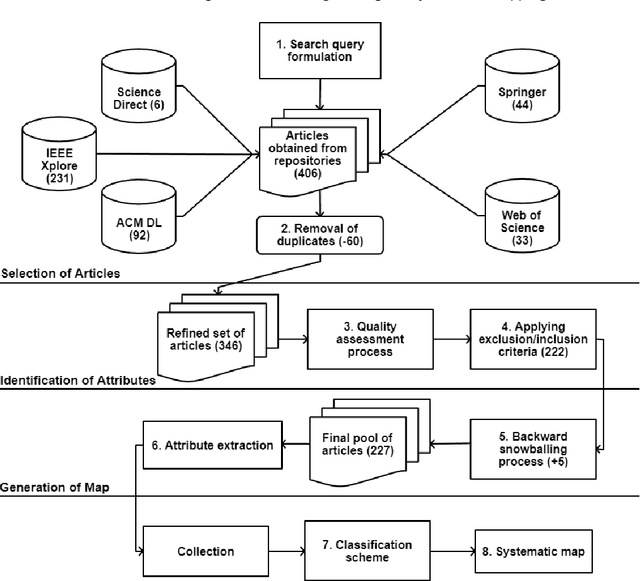

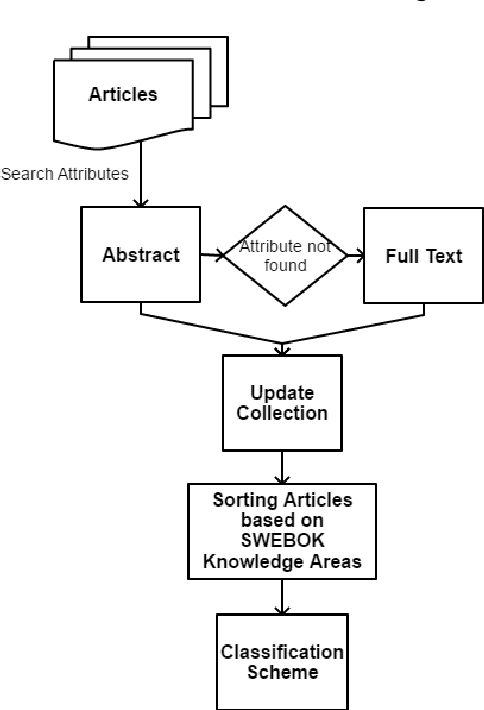

Context: The software development industry is rapidly adopting machine learning for transitioning modern day software systems towards highly intelligent and self-learning systems. However, the full potential of machine learning for improving the software engineering life cycle itself is yet to be discovered, i.e., up to what extent machine learning can help reducing the effort/complexity of software engineering and improving the quality of resulting software systems. To date, no comprehensive study exists that explores the current state-of-the-art on the adoption of machine learning across software engineering life cycle stages. Objective: This article addresses the aforementioned problem and aims to present a state-of-the-art on the growing number of uses of machine learning in software engineering. Method: We conduct a systematic mapping study on applications of machine learning to software engineering following the standard guidelines and principles of empirical software engineering. Results: This study introduces a machine learning for software engineering (MLSE) taxonomy classifying the state-of-the-art machine learning techniques according to their applicability to various software engineering life cycle stages. Overall, 227 articles were rigorously selected and analyzed as a result of this study. Conclusion: From the selected articles, we explore a variety of aspects that should be helpful to academics and practitioners alike in understanding the potential of adopting machine learning techniques during software engineering projects.
Probabilistic Software Modeling: A Data-driven Paradigm for Software Analysis
Dec 18, 2019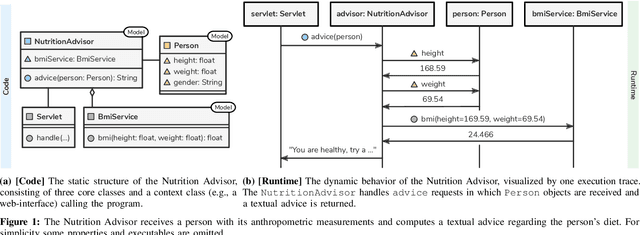
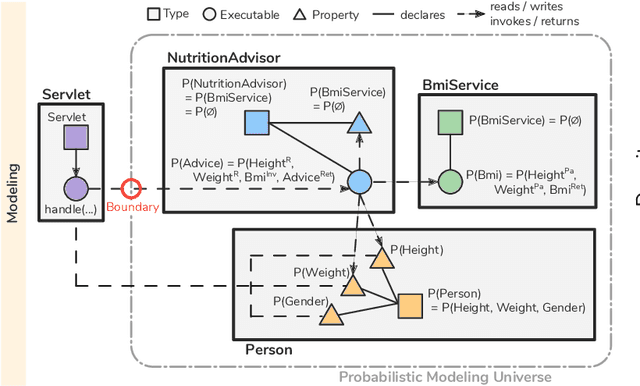
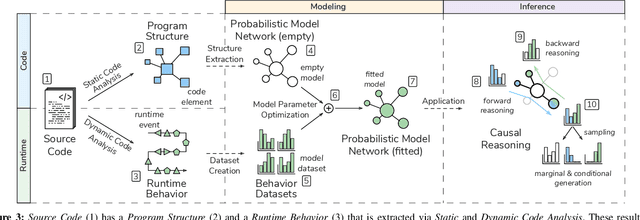
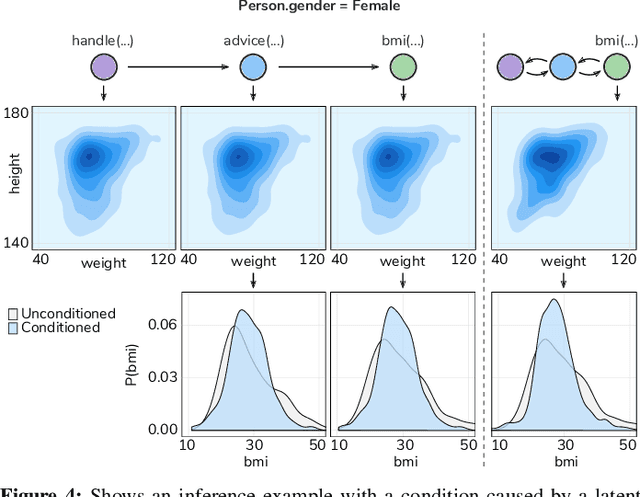
Software systems are complex, and behavioral comprehension with the increasing amount of AI components challenges traditional testing and maintenance strategies.The lack of tools and methodologies for behavioral software comprehension leaves developers to testing and debugging that work in the boundaries of known scenarios. We present Probabilistic Software Modeling (PSM), a data-driven modeling paradigm for predictive and generative methods in software engineering. PSM analyzes a program and synthesizes a network of probabilistic models that can simulate and quantify the original program's behavior. The approach extracts the type, executable, and property structure of a program and copies its topology. Each model is then optimized towards the observed runtime leading to a network that reflects the system's structure and behavior. The resulting network allows for the full spectrum of statistical inferential analysis with which rich predictive and generative applications can be built. Applications range from the visualization of states, inferential queries, test case generation, and anomaly detection up to the stochastic execution of the modeled system. In this work, we present the modeling methodologies, an empirical study of the runtime behavior of software systems, and a comprehensive study on PSM modeled systems. Results indicate that PSM is a solid foundation for structural and behavioral software comprehension applications.
A Hitchhiker's Guide to Search-Based Software Engineering for Software Product Lines
Jun 11, 2014

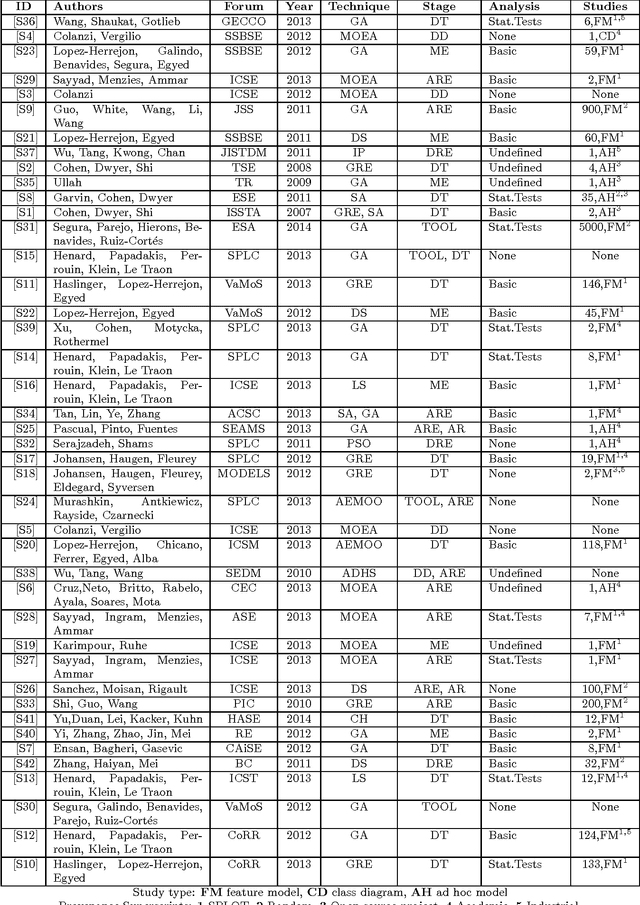
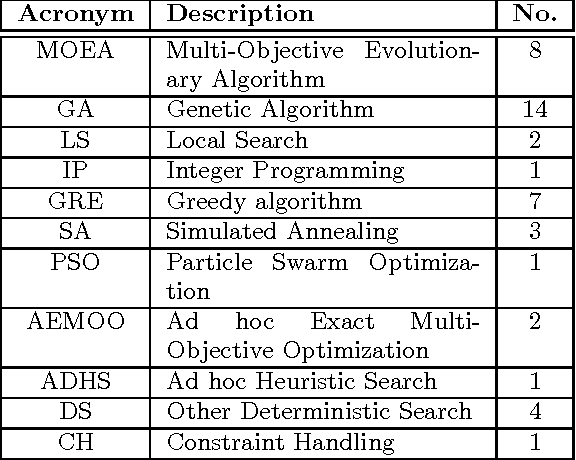
Search Based Software Engineering (SBSE) is an emerging discipline that focuses on the application of search-based optimization techniques to software engineering problems. The capacity of SBSE techniques to tackle problems involving large search spaces make their application attractive for Software Product Lines (SPLs). In recent years, several publications have appeared that apply SBSE techniques to SPL problems. In this paper, we present the results of a systematic mapping study of such publications. We identified the stages of the SPL life cycle where SBSE techniques have been used, what case studies have been employed and how they have been analysed. This mapping study revealed potential venues for further research as well as common misunderstanding and pitfalls when applying SBSE techniques that we address by providing a guideline for researchers and practitioners interested in exploiting these techniques.