 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatalyst: Out-of-Distribution Detection via Elastic Scaling
Feb 02, 2026Out-of-distribution (OOD) detection is critical for the safe deployment of deep neural networks. State-of-the-art post-hoc methods typically derive OOD scores from the output logits or penultimate feature vector obtained via global average pooling (GAP). We contend that this exclusive reliance on the logit or feature vector discards a rich, complementary signal: the raw channel-wise statistics of the pre-pooling feature map lost in GAP. In this paper, we introduce Catalyst, a post-hoc framework that exploits these under-explored signals. Catalyst computes an input-dependent scaling factor ($γ$) on-the-fly from these raw statistics (e.g., mean, standard deviation, and maximum activation). This $γ$ is then fused with the existing baseline score, multiplicatively modulating it -- an ``elastic scaling'' -- to push the ID and OOD distributions further apart. We demonstrate Catalyst is a generalizable framework: it seamlessly integrates with logit-based methods (e.g., Energy, ReAct, SCALE) and also provides a significant boost to distance-based detectors like KNN. As a result, Catalyst achieves substantial and consistent performance gains, reducing the average False Positive Rate by 32.87 on CIFAR-10 (ResNet-18), 27.94% on CIFAR-100 (ResNet-18), and 22.25% on ImageNet (ResNet-50). Our results highlight the untapped potential of pre-pooling statistics and demonstrate that Catalyst is complementary to existing OOD detection approaches.
DAVIS: OOD Detection via Dominant Activations and Variance for Increased Separation
Jan 30, 2026Detecting out-of-distribution (OOD) inputs is a critical safeguard for deploying machine learning models in the real world. However, most post-hoc detection methods operate on penultimate feature representations derived from global average pooling (GAP) -- a lossy operation that discards valuable distributional statistics from activation maps prior to global average pooling. We contend that these overlooked statistics, particularly channel-wise variance and dominant (maximum) activations, are highly discriminative for OOD detection. We introduce DAVIS, a simple and broadly applicable post-hoc technique that enriches feature vectors by incorporating these crucial statistics, directly addressing the information loss from GAP. Extensive evaluations show DAVIS sets a new benchmark across diverse architectures, including ResNet, DenseNet, and EfficientNet. It achieves significant reductions in the false positive rate (FPR95), with improvements of 48.26\% on CIFAR-10 using ResNet-18, 38.13\% on CIFAR-100 using ResNet-34, and 26.83\% on ImageNet-1k benchmarks using MobileNet-v2. Our analysis reveals the underlying mechanism for this improvement, providing a principled basis for moving beyond the mean in OOD detection.
Identifying Appropriately-Sized Services with Deep Reinforcement Learning
Dec 23, 2025Service-based architecture (SBA) has gained attention in industry and academia as a means to modernize legacy systems. It refers to a design style that enables systems to be developed as suites of small, loosely coupled, and autonomous components (services) that encapsulate functionality and communicate via language-agnostic APIs. However, defining appropriately sized services that capture cohesive subsets of system functionality remains challenging. Existing work often relies on the availability of documentation, access to project personnel, or a priori knowledge of the target number of services, assumptions that do not hold in many real-world scenarios. Our work addresses these limitations using a deep reinforcement learning-based approach to identify appropriately sized services directly from implementation artifacts. We present Rake, a reinforcement learning-based technique that leverages available system documentation and source code to guide service decomposition at the level of implementation methods. Rake does not require specific documentation or access to project personnel and is language-agnostic. It also supports a customizable objective function that balances modularization quality and business capability alignment, i.e., the degree to which a service covers the targeted business capability. We applied Rake to four open-source legacy projects and compared it with two state-of-the-art techniques. On average, Rake achieved 7-14 percent higher modularization quality and 18-22 percent stronger business capability alignment. Our results further show that optimizing solely for business context can degrade decomposition quality in tightly coupled systems, highlighting the need for balanced objectives.
Improving DNN Modularization via Activation-Driven Training
Nov 01, 2024Deep Neural Networks (DNNs) suffer from significant retraining costs when adapting to evolving requirements. Modularizing DNNs offers the promise of improving their reusability. Previous work has proposed techniques to decompose DNN models into modules both during and after training. However, these strategies yield several shortcomings, including significant weight overlaps and accuracy losses across modules, restricted focus on convolutional layers only, and added complexity and training time by introducing auxiliary masks to control modularity. In this work, we propose MODA, an activation-driven modular training approach. MODA promotes inherent modularity within a DNN model by directly regulating the activation outputs of its layers based on three modular objectives: intra-class affinity, inter-class dispersion, and compactness. MODA is evaluated using three well-known DNN models and three datasets with varying sizes. This evaluation indicates that, compared to the existing state-of-the-art, using MODA yields several advantages: (1) MODA accomplishes modularization with 29% less training time; (2) the resultant modules generated by MODA comprise 2.4x fewer weights and 3.5x less weight overlap while (3) preserving the original model's accuracy without additional fine-tuning; in module replacement scenarios, (4) MODA improves the accuracy of a target class by 12% on average while ensuring minimal impact on the accuracy of other classes.
Balanced Knowledge Distribution among Software Development Teams -- Observations from Open-Source and Closed-Source Software Development
Jul 26, 2022


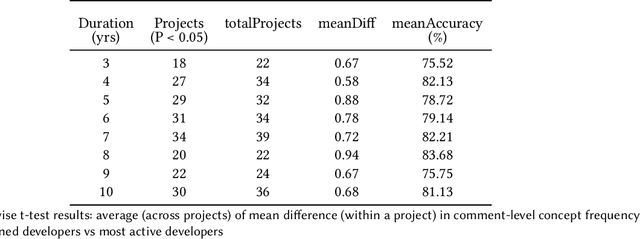
In software development teams, developer turnover is among the primary reasons for project failures as it leads to a great void of knowledge and strain for the newcomers. Unfortunately, no established methods exist to measure how knowledge is distributed among development teams. Knowing how this knowledge evolves and is owned by key developers in a project helps managers reduce risks caused by turnover. To this end, this paper introduces a novel, realistic representation of domain knowledge distribution: the ConceptRealm. To construct the ConceptRealm, we employ a latent Dirichlet allocation model to represent textual features obtained from 300k issues and 1.3M comments from 518 open-source projects. We analyze whether the newly emerged issues and developers share similar concepts or how aligned the developers' concepts are with the team over time. We also investigate the impact of leaving members on the frequency of concepts. Finally, we evaluate the soundness of our approach to closed-source software, thus allowing the validation of the results from a practical standpoint. We find out that the ConceptRealm can represent the high-level domain knowledge within a team and can be utilized to predict the alignment of developers with issues. We also observe that projects exhibit many keepers independent of project maturity and that abruptly leaving keepers harm the team's concept familiarity.
Machine Learning for Software Engineering: A Systematic Mapping
May 27, 2020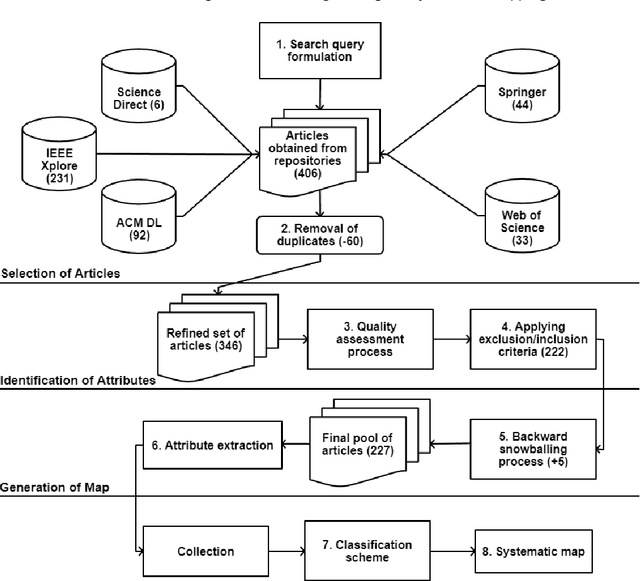

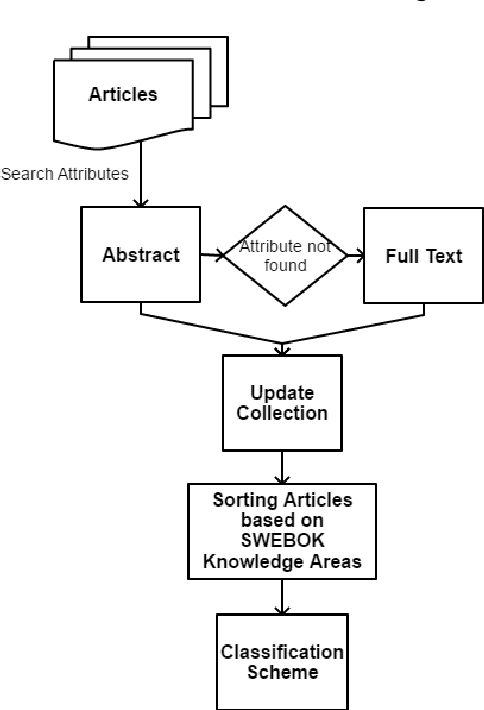

Context: The software development industry is rapidly adopting machine learning for transitioning modern day software systems towards highly intelligent and self-learning systems. However, the full potential of machine learning for improving the software engineering life cycle itself is yet to be discovered, i.e., up to what extent machine learning can help reducing the effort/complexity of software engineering and improving the quality of resulting software systems. To date, no comprehensive study exists that explores the current state-of-the-art on the adoption of machine learning across software engineering life cycle stages. Objective: This article addresses the aforementioned problem and aims to present a state-of-the-art on the growing number of uses of machine learning in software engineering. Method: We conduct a systematic mapping study on applications of machine learning to software engineering following the standard guidelines and principles of empirical software engineering. Results: This study introduces a machine learning for software engineering (MLSE) taxonomy classifying the state-of-the-art machine learning techniques according to their applicability to various software engineering life cycle stages. Overall, 227 articles were rigorously selected and analyzed as a result of this study. Conclusion: From the selected articles, we explore a variety of aspects that should be helpful to academics and practitioners alike in understanding the potential of adopting machine learning techniques during software engineering projects.