 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatalyst: Out-of-Distribution Detection via Elastic Scaling
Feb 02, 2026Out-of-distribution (OOD) detection is critical for the safe deployment of deep neural networks. State-of-the-art post-hoc methods typically derive OOD scores from the output logits or penultimate feature vector obtained via global average pooling (GAP). We contend that this exclusive reliance on the logit or feature vector discards a rich, complementary signal: the raw channel-wise statistics of the pre-pooling feature map lost in GAP. In this paper, we introduce Catalyst, a post-hoc framework that exploits these under-explored signals. Catalyst computes an input-dependent scaling factor ($γ$) on-the-fly from these raw statistics (e.g., mean, standard deviation, and maximum activation). This $γ$ is then fused with the existing baseline score, multiplicatively modulating it -- an ``elastic scaling'' -- to push the ID and OOD distributions further apart. We demonstrate Catalyst is a generalizable framework: it seamlessly integrates with logit-based methods (e.g., Energy, ReAct, SCALE) and also provides a significant boost to distance-based detectors like KNN. As a result, Catalyst achieves substantial and consistent performance gains, reducing the average False Positive Rate by 32.87 on CIFAR-10 (ResNet-18), 27.94% on CIFAR-100 (ResNet-18), and 22.25% on ImageNet (ResNet-50). Our results highlight the untapped potential of pre-pooling statistics and demonstrate that Catalyst is complementary to existing OOD detection approaches.
DAVIS: OOD Detection via Dominant Activations and Variance for Increased Separation
Jan 30, 2026Detecting out-of-distribution (OOD) inputs is a critical safeguard for deploying machine learning models in the real world. However, most post-hoc detection methods operate on penultimate feature representations derived from global average pooling (GAP) -- a lossy operation that discards valuable distributional statistics from activation maps prior to global average pooling. We contend that these overlooked statistics, particularly channel-wise variance and dominant (maximum) activations, are highly discriminative for OOD detection. We introduce DAVIS, a simple and broadly applicable post-hoc technique that enriches feature vectors by incorporating these crucial statistics, directly addressing the information loss from GAP. Extensive evaluations show DAVIS sets a new benchmark across diverse architectures, including ResNet, DenseNet, and EfficientNet. It achieves significant reductions in the false positive rate (FPR95), with improvements of 48.26\% on CIFAR-10 using ResNet-18, 38.13\% on CIFAR-100 using ResNet-34, and 26.83\% on ImageNet-1k benchmarks using MobileNet-v2. Our analysis reveals the underlying mechanism for this improvement, providing a principled basis for moving beyond the mean in OOD detection.
DoorDet: Semi-Automated Multi-Class Door Detection Dataset via Object Detection and Large Language Models
Aug 11, 2025



Accurate detection and classification of diverse door types in floor plans drawings is critical for multiple applications, such as building compliance checking, and indoor scene understanding. Despite their importance, publicly available datasets specifically designed for fine-grained multi-class door detection remain scarce. In this work, we present a semi-automated pipeline that leverages a state-of-the-art object detector and a large language model (LLM) to construct a multi-class door detection dataset with minimal manual effort. Doors are first detected as a unified category using a deep object detection model. Next, an LLM classifies each detected instance based on its visual and contextual features. Finally, a human-in-the-loop stage ensures high-quality labels and bounding boxes. Our method significantly reduces annotation cost while producing a dataset suitable for benchmarking neural models in floor plan analysis. This work demonstrates the potential of combining deep learning and multimodal reasoning for efficient dataset construction in complex real-world domains.
Large Language Models for Computer-Aided Design: A Survey
May 13, 2025Large Language Models (LLMs) have seen rapid advancements in recent years, with models like ChatGPT and DeepSeek, showcasing their remarkable capabilities across diverse domains. While substantial research has been conducted on LLMs in various fields, a comprehensive review focusing on their integration with Computer-Aided Design (CAD) remains notably absent. CAD is the industry standard for 3D modeling and plays a vital role in the design and development of products across different industries. As the complexity of modern designs increases, the potential for LLMs to enhance and streamline CAD workflows presents an exciting frontier. This article presents the first systematic survey exploring the intersection of LLMs and CAD. We begin by outlining the industrial significance of CAD, highlighting the need for AI-driven innovation. Next, we provide a detailed overview of the foundation of LLMs. We also examine both closed-source LLMs as well as publicly available models. The core of this review focuses on the various applications of LLMs in CAD, providing a taxonomy of six key areas where these models are making considerable impact. Finally, we propose several promising future directions for further advancements, which offer vast opportunities for innovation and are poised to shape the future of CAD technology. Github: https://github.com/lichengzhanguom/LLMs-CAD-Survey-Taxonomy
Improving DNN Modularization via Activation-Driven Training
Nov 01, 2024Deep Neural Networks (DNNs) suffer from significant retraining costs when adapting to evolving requirements. Modularizing DNNs offers the promise of improving their reusability. Previous work has proposed techniques to decompose DNN models into modules both during and after training. However, these strategies yield several shortcomings, including significant weight overlaps and accuracy losses across modules, restricted focus on convolutional layers only, and added complexity and training time by introducing auxiliary masks to control modularity. In this work, we propose MODA, an activation-driven modular training approach. MODA promotes inherent modularity within a DNN model by directly regulating the activation outputs of its layers based on three modular objectives: intra-class affinity, inter-class dispersion, and compactness. MODA is evaluated using three well-known DNN models and three datasets with varying sizes. This evaluation indicates that, compared to the existing state-of-the-art, using MODA yields several advantages: (1) MODA accomplishes modularization with 29% less training time; (2) the resultant modules generated by MODA comprise 2.4x fewer weights and 3.5x less weight overlap while (3) preserving the original model's accuracy without additional fine-tuning; in module replacement scenarios, (4) MODA improves the accuracy of a target class by 12% on average while ensuring minimal impact on the accuracy of other classes.
Geodesic-Former: a Geodesic-Guided Few-shot 3D Point Cloud Instance Segmenter
Aug 06, 2022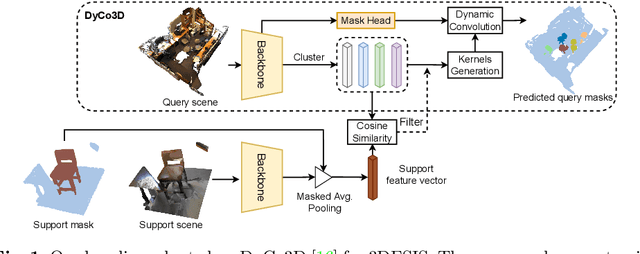


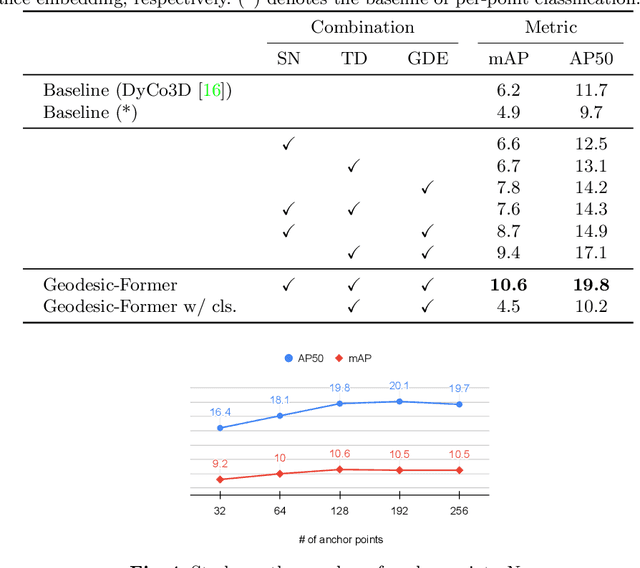
This paper introduces a new problem in 3D point cloud: few-shot instance segmentation. Given a few annotated point clouds exemplified a target class, our goal is to segment all instances of this target class in a query point cloud. This problem has a wide range of practical applications where point-wise instance segmentation annotation is prohibitively expensive to collect. To address this problem, we present Geodesic-Former -- the first geodesic-guided transformer for 3D point cloud instance segmentation. The key idea is to leverage the geodesic distance to tackle the density imbalance of LiDAR 3D point clouds. The LiDAR 3D point clouds are dense near the object surface and sparse or empty elsewhere making the Euclidean distance less effective to distinguish different objects. The geodesic distance, on the other hand, is more suitable since it encodes the scene's geometry which can be used as a guiding signal for the attention mechanism in a transformer decoder to generate kernels representing distinct features of instances. These kernels are then used in a dynamic convolution to obtain the final instance masks. To evaluate Geodesic-Former on the new task, we propose new splits of the two common 3D point cloud instance segmentation datasets: ScannetV2 and S3DIS. Geodesic-Former consistently outperforms strong baselines adapted from state-of-the-art 3D point cloud instance segmentation approaches with a significant margin. Code is available at https://github.com/VinAIResearch/GeoFormer.