 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pipeline for the Continuous Development of Artificial Intelligence Models -- Current State of Research and Practice
Jan 21, 2023Companies struggle to continuously develop and deploy AI models to complex production systems due to AI characteristics while assuring quality. To ease the development process, continuous pipelines for AI have become an active research area where consolidated and in-depth analysis regarding the terminology, triggers, tasks, and challenges is required. This paper includes a Multivocal Literature Review where we consolidated 151 relevant formal and informal sources. In addition, nine-semi structured interviews with participants from academia and industry verified and extended the obtained information. Based on these sources, this paper provides and compares terminologies for DevOps and CI/CD for AI, MLOps, (end-to-end) lifecycle management, and CD4ML. Furthermore, the paper provides an aggregated list of potential triggers for reiterating the pipeline, such as alert systems or schedules. In addition, this work uses a taxonomy creation strategy to present a consolidated pipeline comprising tasks regarding the continuous development of AI. This pipeline consists of four stages: Data Handling, Model Learning, Software Development and System Operations. Moreover, we map challenges regarding pipeline implementation, adaption, and usage for the continuous development of AI to these four stages.
Data Smells: Categories, Causes and Consequences, and Detection of Suspicious Data in AI-based Systems
Mar 28, 2022High data quality is fundamental for today's AI-based systems. However, although data quality has been an object of research for decades, there is a clear lack of research on potential data quality issues (e.g., ambiguous, extraneous values). These kinds of issues are latent in nature and thus often not obvious. Nevertheless, they can be associated with an increased risk of future problems in AI-based systems (e.g., technical debt, data-induced faults). As a counterpart to code smells in software engineering, we refer to such issues as Data Smells. This article conceptualizes data smells and elaborates on their causes, consequences, detection, and use in the context of AI-based systems. In addition, a catalogue of 36 data smells divided into three categories (i.e., Believability Smells, Understandability Smells, Consistency Smells) is presented. Moreover, the article outlines tool support for detecting data smells and presents the result of an initial smell detection on more than 240 real-world datasets.
Probabilistic Software Modeling: A Data-driven Paradigm for Software Analysis
Dec 18, 2019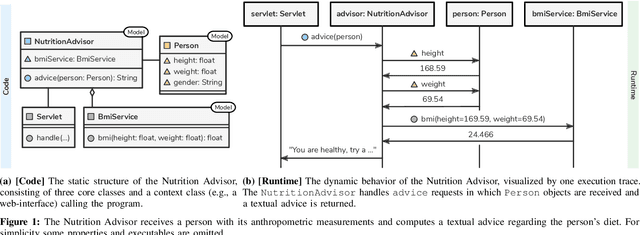
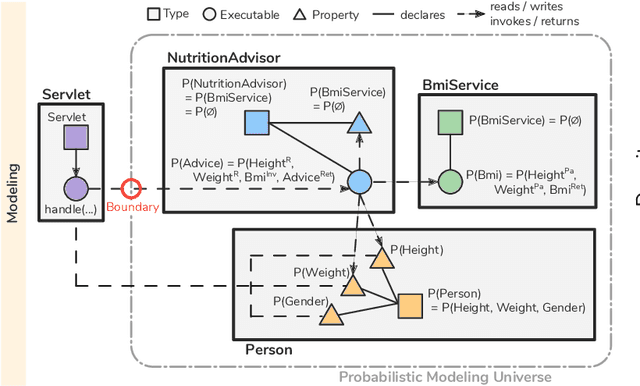
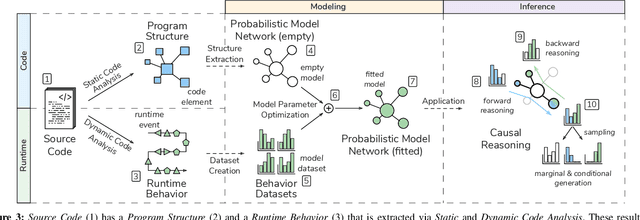
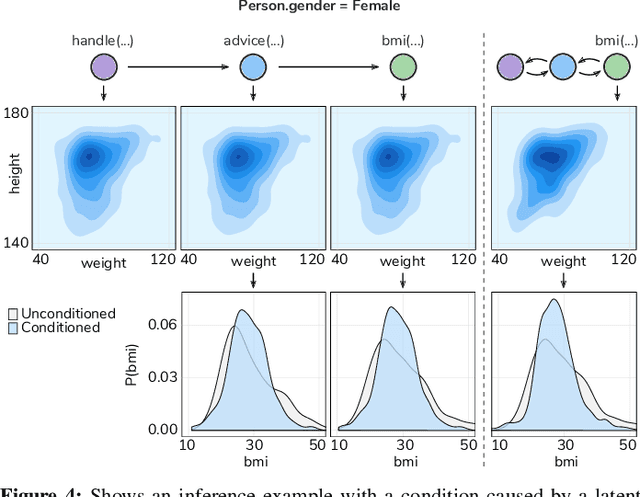
Software systems are complex, and behavioral comprehension with the increasing amount of AI components challenges traditional testing and maintenance strategies.The lack of tools and methodologies for behavioral software comprehension leaves developers to testing and debugging that work in the boundaries of known scenarios. We present Probabilistic Software Modeling (PSM), a data-driven modeling paradigm for predictive and generative methods in software engineering. PSM analyzes a program and synthesizes a network of probabilistic models that can simulate and quantify the original program's behavior. The approach extracts the type, executable, and property structure of a program and copies its topology. Each model is then optimized towards the observed runtime leading to a network that reflects the system's structure and behavior. The resulting network allows for the full spectrum of statistical inferential analysis with which rich predictive and generative applications can be built. Applications range from the visualization of states, inferential queries, test case generation, and anomaly detection up to the stochastic execution of the modeled system. In this work, we present the modeling methodologies, an empirical study of the runtime behavior of software systems, and a comprehensive study on PSM modeled systems. Results indicate that PSM is a solid foundation for structural and behavioral software comprehension applications.