 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Localization via Fine-tuning Large Language Models with Mutation Generated Stack Traces
Jan 29, 2025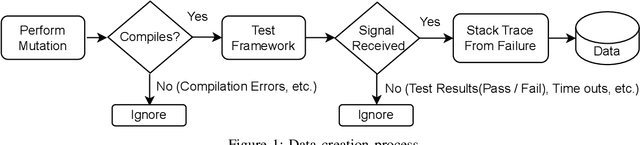
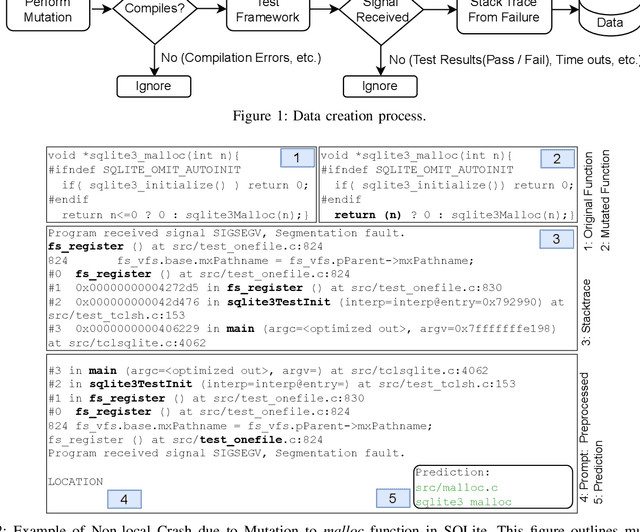
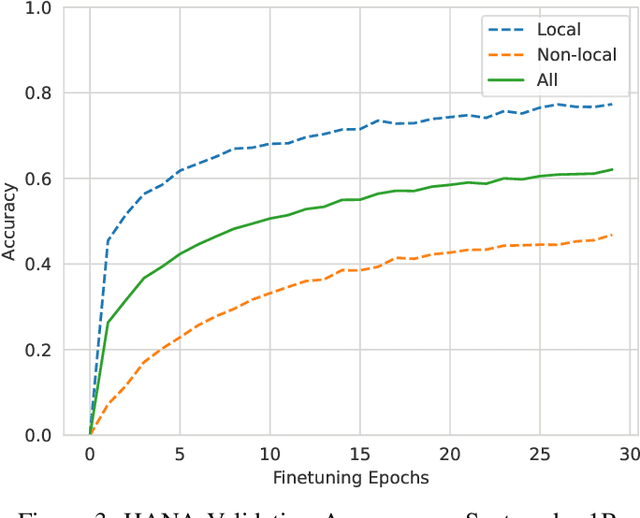
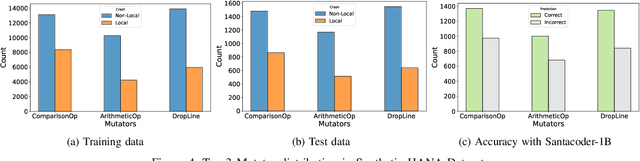
Abrupt and unexpected terminations of software are termed as software crashes. They can be challenging to analyze. Finding the root cause requires extensive manual effort and expertise to connect information sources like stack traces, source code, and logs. Typical approaches to fault localization require either test failures or source code. Crashes occurring in production environments, such as that of SAP HANA, provide solely crash logs and stack traces. We present a novel approach to localize faults based only on the stack trace information and no additional runtime information, by fine-tuning large language models (LLMs). We address complex cases where the root cause of a crash differs from the technical cause, and is not located in the innermost frame of the stack trace. As the number of historic crashes is insufficient to fine-tune LLMs, we augment our dataset by leveraging code mutators to inject synthetic crashes into the code base. By fine-tuning on 64,369 crashes resulting from 4.1 million mutations of the HANA code base, we can correctly predict the root cause location of a crash with an accuracy of 66.9\% while baselines only achieve 12.6% and 10.6%. We substantiate the generalizability of our approach by evaluating on two additional open-source databases, SQLite and DuckDB, achieving accuracies of 63% and 74%, respectively. Across all our experiments, fine-tuning consistently outperformed prompting non-finetuned LLMs for localizing faults in our datasets.
On Enhancing Root Cause Analysis with SQL Summaries for Failures in Database Workload Replays at SAP HANA
Dec 18, 2024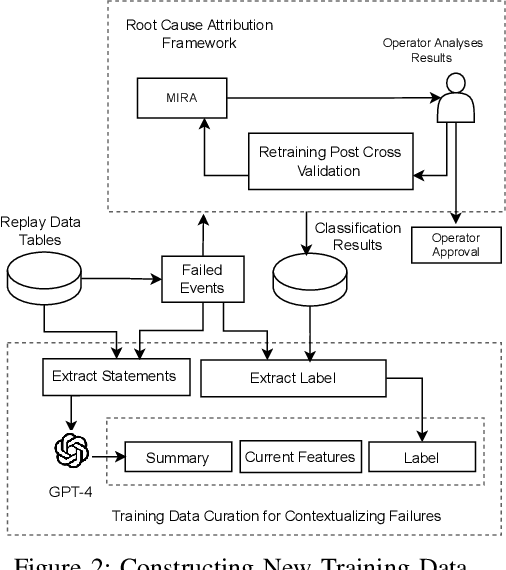
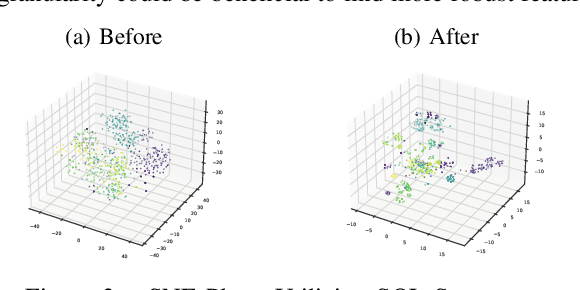
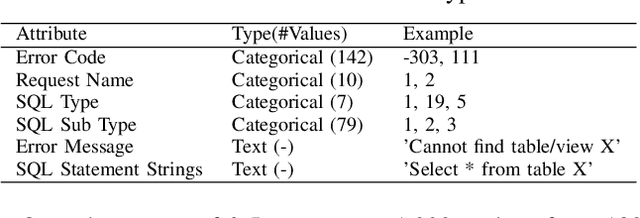
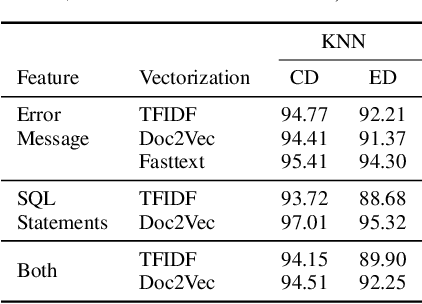
Capturing the workload of a database and replaying this workload for a new version of the database can be an effective approach for regression testing. However, false positive errors caused by many factors such as data privacy limitations, time dependency or non-determinism in multi-threaded environment can negatively impact the effectiveness. Therefore, we employ a machine learning based framework to automate the root cause analysis of failures found during replays. However, handling unseen novel issues not found in the training data is one general challenge of machine learning approaches with respect to generalizability of the learned model. We describe how we continue to address this challenge for more robust long-term solutions. From our experience, retraining with new failures is inadequate due to features overlapping across distinct root causes. Hence, we leverage a large language model (LLM) to analyze failed SQL statements and extract concise failure summaries as an additional feature to enhance the classification process. Our experiments show the F1-Macro score improved by 4.77% for our data. We consider our approach beneficial for providing end users with additional information to gain more insights into the found issues and to improve the assessment of the replay results.
Streamlining Attack Tree Generation: A Fragment-Based Approach
Oct 01, 2023



Attack graphs are a tool for analyzing security vulnerabilities that capture different and prospective attacks on a system. As a threat modeling tool, it shows possible paths that an attacker can exploit to achieve a particular goal. However, due to the large number of vulnerabilities that are published on a daily basis, they have the potential to rapidly expand in size. Consequently, this necessitates a significant amount of resources to generate attack graphs. In addition, generating composited attack models for complex systems such as self-adaptive or AI is very difficult due to their nature to continuously change. In this paper, we present a novel fragment-based attack graph generation approach that utilizes information from publicly available information security databases. Furthermore, we also propose a domain-specific language for attack modeling, which we employ in the proposed attack graph generation approach. Finally, we present a demonstrator example showcasing the attack generator's capability to replicate a verified attack chain, as previously confirmed by security experts.
Towards Model Co-evolution Across Self-Adaptation Steps for Combined Safety and Security Analysis
Sep 18, 2023
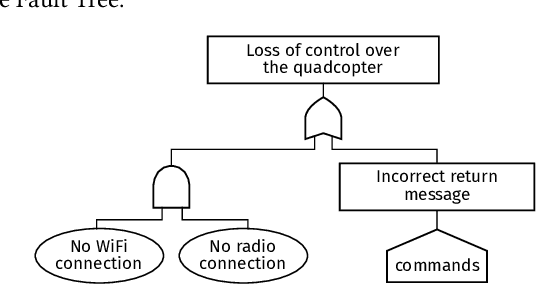
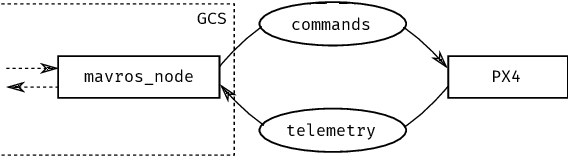
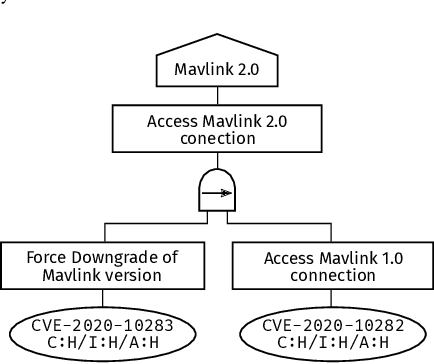
Self-adaptive systems offer several attack surfaces due to the communication via different channels and the different sensors required to observe the environment. Often, attacks cause safety to be compromised as well, making it necessary to consider these two aspects together. Furthermore, the approaches currently used for safety and security analysis do not sufficiently take into account the intermediate steps of an adaptation. Current work in this area ignores the fact that a self-adaptive system also reveals possible vulnerabilities (even if only temporarily) during the adaptation. To address this issue, we propose a modeling approach that takes into account the different relevant aspects of a system, its adaptation process, as well as safety hazards and security attacks. We present several models that describe different aspects of a self-adaptive system and we outline our idea of how these models can then be combined into an Attack-Fault Tree. This allows modeling aspects of the system on different levels of abstraction and co-evolve the models using transformations according to the adaptation of the system. Finally, analyses can then be performed as usual on the resulting Attack-Fault Tree.
VULNERLIZER: Cross-analysis Between Vulnerabilities and Software Libraries
Sep 18, 2023



The identification of vulnerabilities is a continuous challenge in software projects. This is due to the evolution of methods that attackers employ as well as the constant updates to the software, which reveal additional issues. As a result, new and innovative approaches for the identification of vulnerable software are needed. In this paper, we present VULNERLIZER, which is a novel framework for cross-analysis between vulnerabilities and software libraries. It uses CVE and software library data together with clustering algorithms to generate links between vulnerabilities and libraries. In addition, the training of the model is conducted in order to reevaluate the generated associations. This is achieved by updating the assigned weights. Finally, the approach is then evaluated by making the predictions using the CVE data from the test set. The results show that the VULNERLIZER has a great potential in being able to predict future vulnerable libraries based on an initial input CVE entry or a software library. The trained model reaches a prediction accuracy of 75% or higher.
Simulation of Sensor Spoofing Attacks on Unmanned Aerial Vehicles Using the Gazebo Simulator
Sep 18, 2023



Conducting safety simulations in various simulators, such as the Gazebo simulator, became a very popular means of testing vehicles against potential safety risks (i.e. crashes). However, this was not the case with security testing. Performing security testing in a simulator is very difficult because security attacks are performed on a different abstraction level. In addition, the attacks themselves are becoming more sophisticated, which directly contributes to the difficulty of executing them in a simulator. In this paper, we attempt to tackle the aforementioned gap by investigating possible attacks that can be simulated, and then performing their simulations. The presented approach shows that attacks targeting the LiDAR and GPS components of unmanned aerial vehicles can be simulated. This is achieved by exploiting vulnerabilities of the ROS and MAVLink protocol and injecting malicious processes into an application. As a result, messages with arbitrary values can be spoofed to the corresponding topics, which allows attackers to update relevant parameters and cause a potential crash of a vehicle. This was tested in multiple scenarios, thereby proving that it is indeed possible to simulate certain attack types, such as spoofing and jamming.
The Pipeline for the Continuous Development of Artificial Intelligence Models -- Current State of Research and Practice
Jan 21, 2023Companies struggle to continuously develop and deploy AI models to complex production systems due to AI characteristics while assuring quality. To ease the development process, continuous pipelines for AI have become an active research area where consolidated and in-depth analysis regarding the terminology, triggers, tasks, and challenges is required. This paper includes a Multivocal Literature Review where we consolidated 151 relevant formal and informal sources. In addition, nine-semi structured interviews with participants from academia and industry verified and extended the obtained information. Based on these sources, this paper provides and compares terminologies for DevOps and CI/CD for AI, MLOps, (end-to-end) lifecycle management, and CD4ML. Furthermore, the paper provides an aggregated list of potential triggers for reiterating the pipeline, such as alert systems or schedules. In addition, this work uses a taxonomy creation strategy to present a consolidated pipeline comprising tasks regarding the continuous development of AI. This pipeline consists of four stages: Data Handling, Model Learning, Software Development and System Operations. Moreover, we map challenges regarding pipeline implementation, adaption, and usage for the continuous development of AI to these four stages.
Metamorphic Testing in Autonomous System Simulations
Sep 22, 2022

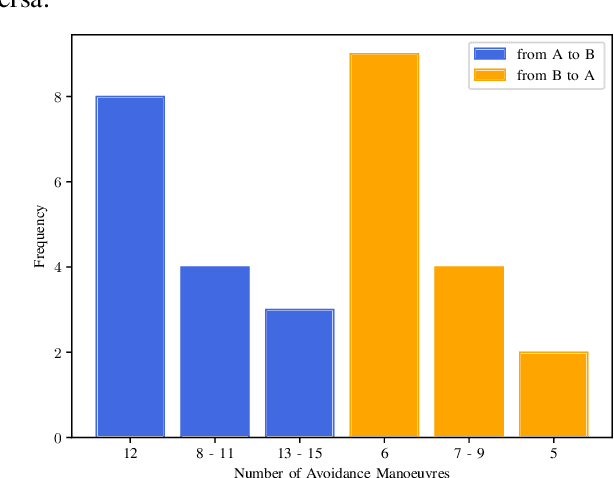
Metamorphic testing has proven to be effective for test case generation and fault detection in many domains. It is a software testing strategy that uses certain relations between input-output pairs of a program, referred to as metamorphic relations. This approach is relevant in the autonomous systems domain since it helps in cases where the outcome of a given test input may be difficult to determine. In this paper therefore, we provide an overview of metamorphic testing as well as an implementation in the autonomous systems domain. We implement an obstacle detection and avoidance task in autonomous drones utilising the GNC API alongside a simulation in Gazebo. Particularly, we describe properties and best practices that are crucial for the development of effective metamorphic relations. We also demonstrate two metamorphic relations for metamorphic testing of single and more than one drones, respectively. Our relations reveal several properties and some weak spots of both the implementation and the avoidance algorithm in the light of metamorphic testing. The results indicate that metamorphic testing has great potential in the autonomous systems domain and should be considered for quality assurance in this field.
Guiding the retraining of convolutional neural networks against adversarial inputs
Jul 12, 2022
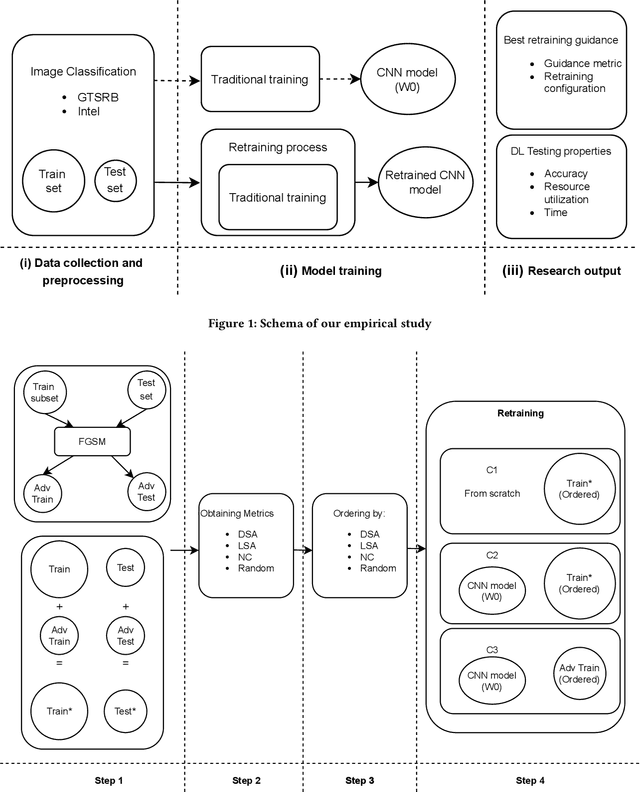

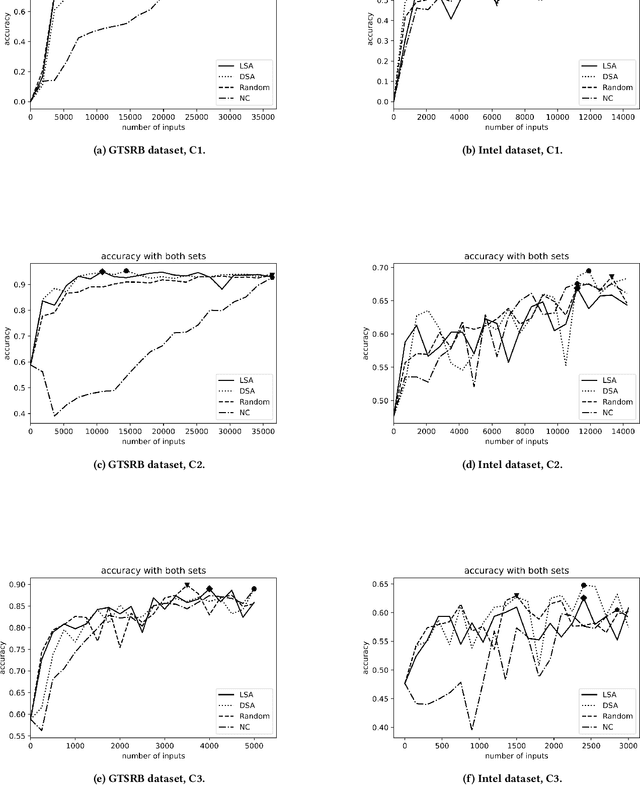
Background: When using deep learning models, there are many possible vulnerabilities and some of the most worrying are the adversarial inputs, which can cause wrong decisions with minor perturbations. Therefore, it becomes necessary to retrain these models against adversarial inputs, as part of the software testing process addressing the vulnerability to these inputs. Furthermore, for an energy efficient testing and retraining, data scientists need support on which are the best guidance metrics and optimal dataset configurations. Aims: We examined four guidance metrics for retraining convolutional neural networks and three retraining configurations. Our goal is to improve the models against adversarial inputs regarding accuracy, resource utilization and time from the point of view of a data scientist in the context of image classification. Method: We conducted an empirical study in two datasets for image classification. We explore: (a) the accuracy, resource utilization and time of retraining convolutional neural networks by ordering new training set by four different guidance metrics (neuron coverage, likelihood-based surprise adequacy, distance-based surprise adequacy and random), (b) the accuracy and resource utilization of retraining convolutional neural networks with three different configurations (from scratch and augmented dataset, using weights and augmented dataset, and using weights and only adversarial inputs). Results: We reveal that retraining with adversarial inputs from original weights and by ordering with surprise adequacy metrics gives the best model w.r.t. the used metrics. Conclusions: Although more studies are necessary, we recommend data scientists to use the above configuration and metrics to deal with the vulnerability to adversarial inputs of deep learning models, as they can improve their models against adversarial inputs without using many inputs.
Automatic Error Classification and Root Cause Determination while Replaying Recorded Workload Data at SAP HANA
May 16, 2022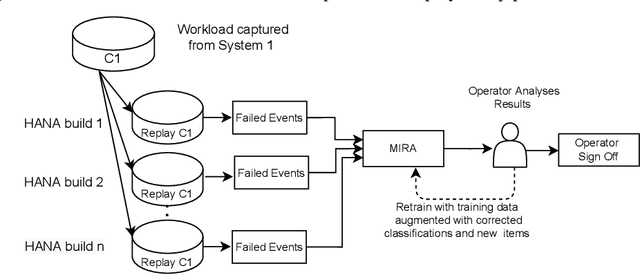
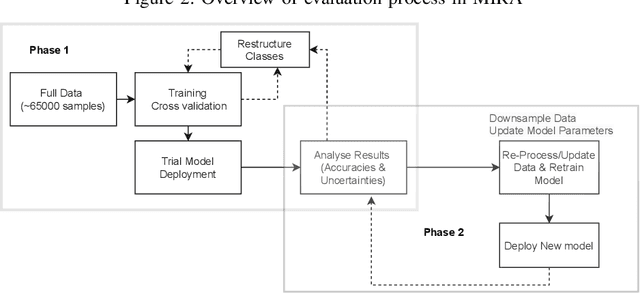

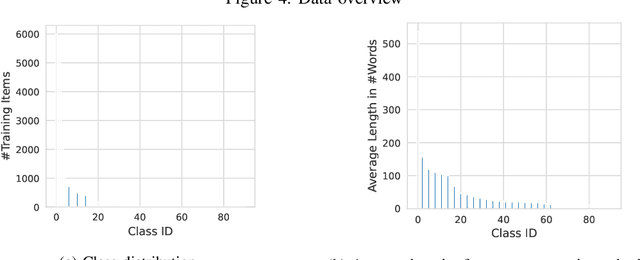
Capturing customer workloads of database systems to replay these workloads during internal testing can be beneficial for software quality assurance. However, we experienced that such replays can produce a large amount of false positive alerts that make the results unreliable or time consuming to analyze. Therefore, we design a machine learning based approach that attributes root causes to the alerts. This provides several benefits for quality assurance and allows for example to classify whether an alert is true positive or false positive. Our approach considerably reduces manual effort and improves the overall quality assurance for the database system SAP HANA. We discuss the problem, the design and result of our approach, and we present practical limitations that may require further research.