 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating empirical evidence from data strategy studies: a case on model quantization
May 01, 2025



Background: As empirical software engineering evolves, more studies adopt data strategies$-$approaches that investigate digital artifacts such as models, source code, or system logs rather than relying on human subjects. Synthesizing results from such studies introduces new methodological challenges. Aims: This study assesses the effects of model quantization on correctness and resource efficiency in deep learning (DL) systems. Additionally, it explores the methodological implications of aggregating evidence from empirical studies that adopt data strategies. Method: We conducted a research synthesis of six primary studies that empirically evaluate model quantization. We applied the Structured Synthesis Method (SSM) to aggregate the findings, which combines qualitative and quantitative evidence through diagrammatic modeling. A total of 19 evidence models were extracted and aggregated. Results: The aggregated evidence indicates that model quantization weakly negatively affects correctness metrics while consistently improving resource efficiency metrics, including storage size, inference latency, and GPU energy consumption$-$a manageable trade-off for many DL deployment contexts. Evidence across quantization techniques remains fragmented, underscoring the need for more focused empirical studies per technique. Conclusions: Model quantization offers substantial efficiency benefits with minor trade-offs in correctness, making it a suitable optimization strategy for resource-constrained environments. This study also demonstrates the feasibility of using SSM to synthesize findings from data strategy-based research.
Addressing Quality Challenges in Deep Learning: The Role of MLOps and Domain Knowledge
Jan 14, 2025Deep learning (DL) systems present unique challenges in software engineering, especially concerning quality attributes like correctness and resource efficiency. While DL models achieve exceptional performance in specific tasks, engineering DL-based systems is still essential. The effort, cost, and potential diminishing returns of continual improvements must be carefully evaluated, as software engineers often face the critical decision of when to stop refining a system relative to its quality attributes. This experience paper explores the role of MLOps practices -- such as monitoring and experiment tracking -- in creating transparent and reproducible experimentation environments that enable teams to assess and justify the impact of design decisions on quality attributes. Furthermore, we report on experiences addressing the quality challenges by embedding domain knowledge into the design of a DL model and its integration within a larger system. The findings offer actionable insights into not only the benefits of domain knowledge and MLOps but also the strategic consideration of when to limit further optimizations in DL projects to maximize overall system quality and reliability.
Energy consumption of code small language models serving with runtime engines and execution providers
Dec 19, 2024Background. The rapid growth of Language Models (LMs), particularly in code generation, requires substantial computational resources, raising concerns about energy consumption and environmental impact. Optimizing LMs inference for energy efficiency is crucial, and Small Language Models (SLMs) offer a promising solution to reduce resource demands. Aim. Our goal is to analyze the impact of deep learning runtime engines and execution providers on energy consumption, execution time, and computing-resource utilization from the point of view of software engineers conducting inference in the context of code SLMs. Method. We conducted a technology-oriented, multi-stage experimental pipeline using twelve code generation SLMs to investigate energy consumption, execution time, and computing-resource utilization across the configurations. Results. Significant differences emerged across configurations. CUDA execution provider configurations outperformed CPU execution provider configurations in both energy consumption and execution time. Among the configurations, TORCH paired with CUDA demonstrated the greatest energy efficiency, achieving energy savings from 37.99% up to 89.16% compared to other serving configurations. Similarly, optimized runtime engines like ONNX with the CPU execution provider achieved from 8.98% up to 72.04% energy savings within CPU-based configurations. Also, TORCH paired with CUDA exhibited efficient computing-resource utilization. Conclusions. Serving configuration choice significantly impacts energy efficiency. While further research is needed, we recommend the above configurations best suited to software engineers' requirements for enhancing serving efficiency in energy and performance.
How do Machine Learning Models Change?
Nov 14, 2024
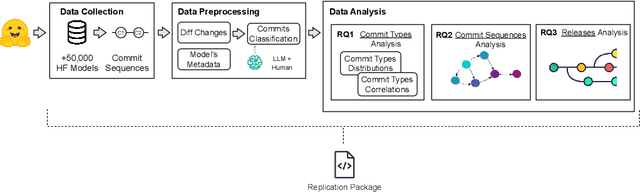
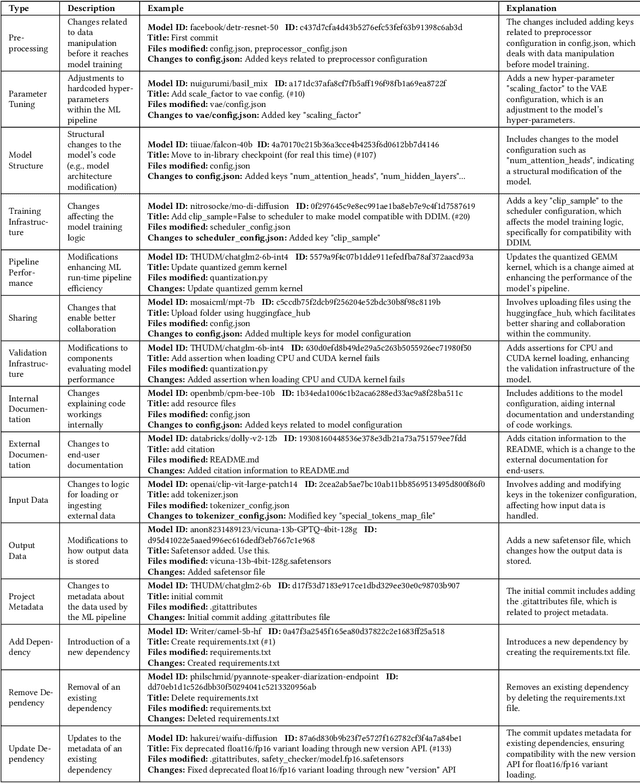
The proliferation of Machine Learning (ML) models and their open-source implementations has transformed Artificial Intelligence research and applications. Platforms like Hugging Face (HF) enable the development, sharing, and deployment of these models, fostering an evolving ecosystem. While previous studies have examined aspects of models hosted on platforms like HF, a comprehensive longitudinal study of how these models change remains underexplored. This study addresses this gap by utilizing both repository mining and longitudinal analysis methods to examine over 200,000 commits and 1,200 releases from over 50,000 models on HF. We replicate and extend an ML change taxonomy for classifying commits and utilize Bayesian networks to uncover patterns in commit and release activities over time. Our findings indicate that commit activities align with established data science methodologies, such as CRISP-DM, emphasizing iterative refinement and continuous improvement. Additionally, release patterns tend to consolidate significant updates, particularly in documentation, distinguishing between granular changes and milestone-based releases. Furthermore, projects with higher popularity prioritize infrastructure enhancements early in their lifecycle, and those with intensive collaboration practices exhibit improved documentation standards. These and other insights enhance the understanding of model changes on community platforms and provide valuable guidance for best practices in model maintenance.
Towards a Classification of Open-Source ML Models and Datasets for Software Engineering
Nov 14, 2024



Background: Open-Source Pre-Trained Models (PTMs) and datasets provide extensive resources for various Machine Learning (ML) tasks, yet these resources lack a classification tailored to Software Engineering (SE) needs. Aims: We apply an SE-oriented classification to PTMs and datasets on a popular open-source ML repository, Hugging Face (HF), and analyze the evolution of PTMs over time. Method: We conducted a repository mining study. We started with a systematically gathered database of PTMs and datasets from the HF API. Our selection was refined by analyzing model and dataset cards and metadata, such as tags, and confirming SE relevance using Gemini 1.5 Pro. All analyses are replicable, with a publicly accessible replication package. Results: The most common SE task among PTMs and datasets is code generation, with a primary focus on software development and limited attention to software management. Popular PTMs and datasets mainly target software development. Among ML tasks, text generation is the most common in SE PTMs and datasets. There has been a marked increase in PTMs for SE since 2023 Q2. Conclusions: This study underscores the need for broader task coverage to enhance the integration of ML within SE practices.
The More the Merrier? Navigating Accuracy vs. Energy Efficiency Design Trade-Offs in Ensemble Learning Systems
Jul 03, 2024Background: Machine learning (ML) model composition is a popular technique to mitigate shortcomings of a single ML model and to design more effective ML-enabled systems. While ensemble learning, i.e., forwarding the same request to several models and fusing their predictions, has been studied extensively for accuracy, we have insufficient knowledge about how to design energy-efficient ensembles. Objective: We therefore analyzed three types of design decisions for ensemble learning regarding a potential trade-off between accuracy and energy consumption: a) ensemble size, i.e., the number of models in the ensemble, b) fusion methods (majority voting vs. a meta-model), and c) partitioning methods (whole-dataset vs. subset-based training). Methods: By combining four popular ML algorithms for classification in different ensembles, we conducted a full factorial experiment with 11 ensembles x 4 datasets x 2 fusion methods x 2 partitioning methods (176 combinations). For each combination, we measured accuracy (F1-score) and energy consumption in J (for both training and inference). Results: While a larger ensemble size significantly increased energy consumption (size 2 ensembles consumed 37.49% less energy than size 3 ensembles, which in turn consumed 26.96% less energy than the size 4 ensembles), it did not significantly increase accuracy. Furthermore, majority voting outperformed meta-model fusion both in terms of accuracy (Cohen's d of 0.38) and energy consumption (Cohen's d of 0.92). Lastly, subset-based training led to significantly lower energy consumption (Cohen's d of 0.91), while training on the whole dataset did not increase accuracy significantly. Conclusions: From a Green AI perspective, we recommend designing ensembles of small size (2 or maximum 3 models), using subset-based training, majority voting, and energy-efficient ML algorithms like decision trees, Naive Bayes, or KNN.
Innovating for Tomorrow: The Convergence of SE and Green AI
Jun 26, 2024
The latest advancements in machine learning, specifically in foundation models, are revolutionizing the frontiers of existing software engineering (SE) processes. This is a bi-directional phenomona, where 1) software systems are now challenged to provide AI-enabled features to their users, and 2) AI is used to automate tasks within the software development lifecycle. In an era where sustainability is a pressing societal concern, our community needs to adopt a long-term plan enabling a conscious transformation that aligns with environmental sustainability values. In this paper, we reflect on the impact of adopting environmentally friendly practices to create AI-enabled software systems and make considerations on the environmental impact of using foundation models for software development.
Identifying architectural design decisions for achieving green ML serving
Feb 12, 2024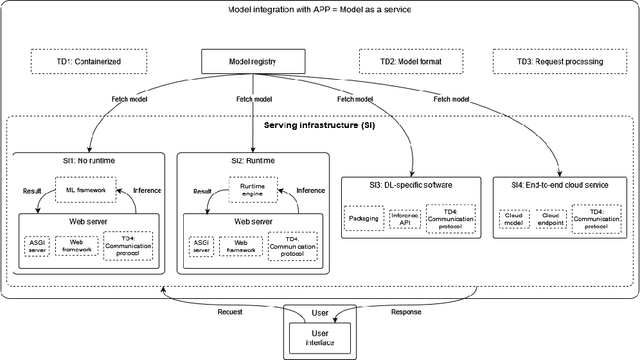
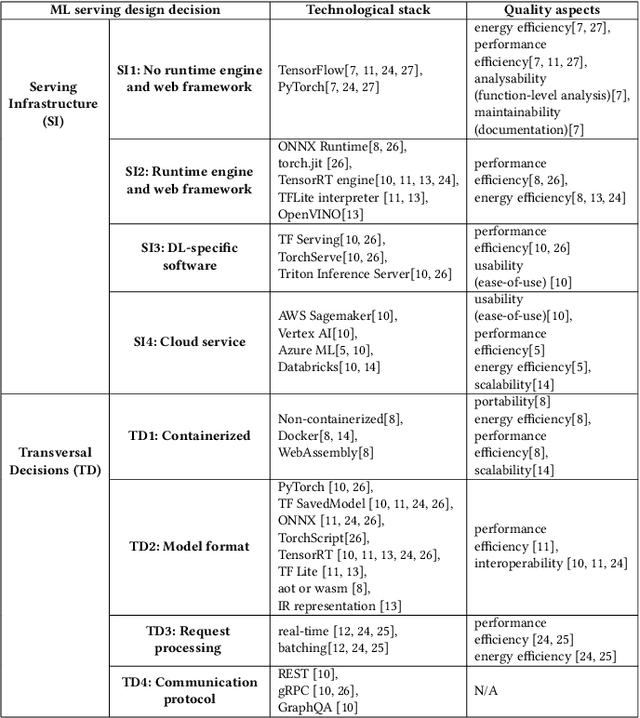
The growing use of large machine learning models highlights concerns about their increasing computational demands. While the energy consumption of their training phase has received attention, fewer works have considered the inference phase. For ML inference, the binding of ML models to the ML system for user access, known as ML serving, is a critical yet understudied step for achieving efficiency in ML applications. We examine the literature in ML architectural design decisions and Green AI, with a special focus on ML serving. The aim is to analyze ML serving architectural design decisions for the purpose of understanding and identifying them with respect to quality characteristics from the point of view of researchers and practitioners in the context of ML serving literature. Our results (i) identify ML serving architectural design decisions along with their corresponding components and associated technological stack, and (ii) provide an overview of the quality characteristics studied in the literature, including energy efficiency. This preliminary study is the first step in our goal to achieve green ML serving. Our analysis may aid ML researchers and practitioners in making green-aware architecture design decisions when serving their models.
Lessons Learned from Mining the Hugging Face Repository
Feb 11, 2024The rapidly evolving fields of Machine Learning (ML) and Artificial Intelligence have witnessed the emergence of platforms like Hugging Face (HF) as central hubs for model development and sharing. This experience report synthesizes insights from two comprehensive studies conducted on HF, focusing on carbon emissions and the evolutionary and maintenance aspects of ML models. Our objective is to provide a practical guide for future researchers embarking on mining software repository studies within the HF ecosystem to enhance the quality of these studies. We delve into the intricacies of the replication package used in our studies, highlighting the pivotal tools and methodologies that facilitated our analysis. Furthermore, we propose a nuanced stratified sampling strategy tailored for the diverse HF Hub dataset, ensuring a representative and comprehensive analytical approach. The report also introduces preliminary guidelines, transitioning from repository mining to cohort studies, to establish causality in repository mining studies, particularly within the ML model of HF context. This transition is inspired by existing frameworks and is adapted to suit the unique characteristics of the HF model ecosystem. Our report serves as a guiding framework for researchers, contributing to the responsible and sustainable advancement of ML, and fostering a deeper understanding of the broader implications of ML models.
Towards green AI-based software systems: an architecture-centric approach
Jul 19, 2023

Nowadays, AI-based systems have achieved outstanding results and have outperformed humans in different domains. However, the processes of training AI models and inferring from them require high computational resources, which pose a significant challenge in the current energy efficiency societal demand. To cope with this challenge, this research project paper describes the main vision, goals, and expected outcomes of the GAISSA project. The GAISSA project aims at providing data scientists and software engineers tool-supported, architecture-centric methods for the modelling and development of green AI-based systems. Although the project is in an initial stage, we describe the current research results, which illustrate the potential to achieve GAISSA objectives.