 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy consumption of code small language models serving with runtime engines and execution providers
Dec 19, 2024Background. The rapid growth of Language Models (LMs), particularly in code generation, requires substantial computational resources, raising concerns about energy consumption and environmental impact. Optimizing LMs inference for energy efficiency is crucial, and Small Language Models (SLMs) offer a promising solution to reduce resource demands. Aim. Our goal is to analyze the impact of deep learning runtime engines and execution providers on energy consumption, execution time, and computing-resource utilization from the point of view of software engineers conducting inference in the context of code SLMs. Method. We conducted a technology-oriented, multi-stage experimental pipeline using twelve code generation SLMs to investigate energy consumption, execution time, and computing-resource utilization across the configurations. Results. Significant differences emerged across configurations. CUDA execution provider configurations outperformed CPU execution provider configurations in both energy consumption and execution time. Among the configurations, TORCH paired with CUDA demonstrated the greatest energy efficiency, achieving energy savings from 37.99% up to 89.16% compared to other serving configurations. Similarly, optimized runtime engines like ONNX with the CPU execution provider achieved from 8.98% up to 72.04% energy savings within CPU-based configurations. Also, TORCH paired with CUDA exhibited efficient computing-resource utilization. Conclusions. Serving configuration choice significantly impacts energy efficiency. While further research is needed, we recommend the above configurations best suited to software engineers' requirements for enhancing serving efficiency in energy and performance.
Ten Years of Teaching Empirical Software Engineering in the context of Energy-efficient Software
Jul 08, 2024
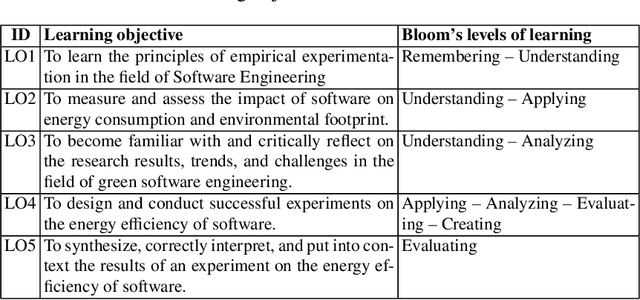
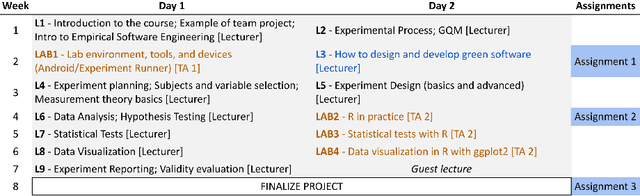
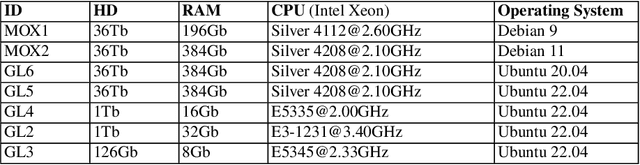
In this chapter we share our experience in running ten editions of the Green Lab course at the Vrije Universiteit Amsterdam, the Netherlands. The course is given in the Software Engineering and Green IT track of the Computer Science Master program of the VU. The course takes place every year over a 2-month period and teaches Computer Science students the fundamentals of Empirical Software Engineering in the context of energy-efficient software. The peculiarity of the course is its research orientation: at the beginning of the course the instructor presents a catalog of scientifically relevant goals, and each team of students signs up for one of them and works together for 2 months on their own experiment for achieving the goal. Each team goes over the classic steps of an empirical study, starting from a precise formulation of the goal and research questions to context definition, selection of experimental subjects and objects, definition of experimental variables, experiment execution, data analysis, and reporting. Over the years, the course became well-known within the Software Engineering community since it led to several scientific studies that have been published at various scientific conferences and journals. Also, students execute their experiments using \textit{open-source tools}, which are developed and maintained by researchers and other students within the program, thus creating a virtuous community of learners where students exchange ideas, help each other, and learn how to collaboratively contribute to open-source projects in a safe environment.
The More the Merrier? Navigating Accuracy vs. Energy Efficiency Design Trade-Offs in Ensemble Learning Systems
Jul 03, 2024Background: Machine learning (ML) model composition is a popular technique to mitigate shortcomings of a single ML model and to design more effective ML-enabled systems. While ensemble learning, i.e., forwarding the same request to several models and fusing their predictions, has been studied extensively for accuracy, we have insufficient knowledge about how to design energy-efficient ensembles. Objective: We therefore analyzed three types of design decisions for ensemble learning regarding a potential trade-off between accuracy and energy consumption: a) ensemble size, i.e., the number of models in the ensemble, b) fusion methods (majority voting vs. a meta-model), and c) partitioning methods (whole-dataset vs. subset-based training). Methods: By combining four popular ML algorithms for classification in different ensembles, we conducted a full factorial experiment with 11 ensembles x 4 datasets x 2 fusion methods x 2 partitioning methods (176 combinations). For each combination, we measured accuracy (F1-score) and energy consumption in J (for both training and inference). Results: While a larger ensemble size significantly increased energy consumption (size 2 ensembles consumed 37.49% less energy than size 3 ensembles, which in turn consumed 26.96% less energy than the size 4 ensembles), it did not significantly increase accuracy. Furthermore, majority voting outperformed meta-model fusion both in terms of accuracy (Cohen's d of 0.38) and energy consumption (Cohen's d of 0.92). Lastly, subset-based training led to significantly lower energy consumption (Cohen's d of 0.91), while training on the whole dataset did not increase accuracy significantly. Conclusions: From a Green AI perspective, we recommend designing ensembles of small size (2 or maximum 3 models), using subset-based training, majority voting, and energy-efficient ML algorithms like decision trees, Naive Bayes, or KNN.
How to Sustainably Monitor ML-Enabled Systems? Accuracy and Energy Efficiency Tradeoffs in Concept Drift Detection
Apr 30, 2024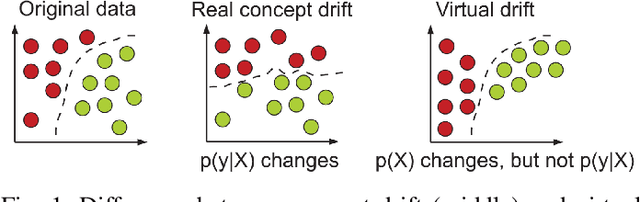
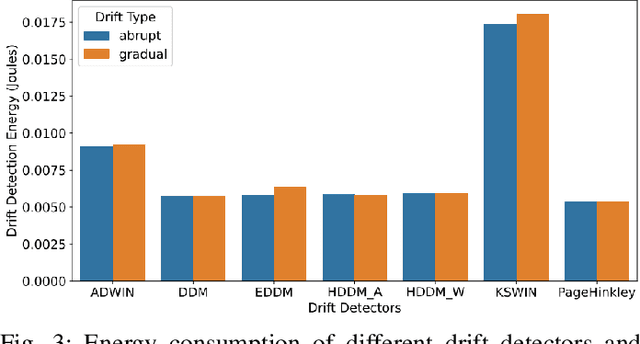
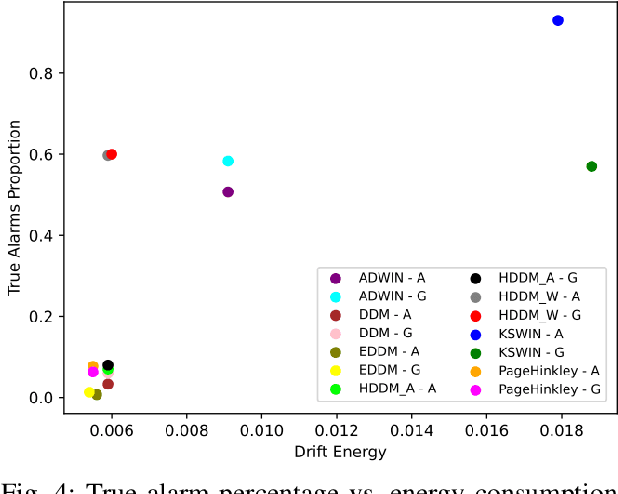
ML-enabled systems that are deployed in a production environment typically suffer from decaying model prediction quality through concept drift, i.e., a gradual change in the statistical characteristics of a certain real-world domain. To combat this, a simple solution is to periodically retrain ML models, which unfortunately can consume a lot of energy. One recommended tactic to improve energy efficiency is therefore to systematically monitor the level of concept drift and only retrain when it becomes unavoidable. Different methods are available to do this, but we know very little about their concrete impact on the tradeoff between accuracy and energy efficiency, as these methods also consume energy themselves. To address this, we therefore conducted a controlled experiment to study the accuracy vs. energy efficiency tradeoff of seven common methods for concept drift detection. We used five synthetic datasets, each in a version with abrupt and one with gradual drift, and trained six different ML models as base classifiers. Based on a full factorial design, we tested 420 combinations (7 drift detectors * 5 datasets * 2 types of drift * 6 base classifiers) and compared energy consumption and drift detection accuracy. Our results indicate that there are three types of detectors: a) detectors that sacrifice energy efficiency for detection accuracy (KSWIN), b) balanced detectors that consume low to medium energy with good accuracy (HDDM_W, ADWIN), and c) detectors that consume very little energy but are unusable in practice due to very poor accuracy (HDDM_A, PageHinkley, DDM, EDDM). By providing rich evidence for this energy efficiency tactic, our findings support ML practitioners in choosing the best suited method of concept drift detection for their ML-enabled systems.
Balancing Progress and Responsibility: A Synthesis of Sustainability Trade-Offs of AI-Based Systems
Apr 05, 2024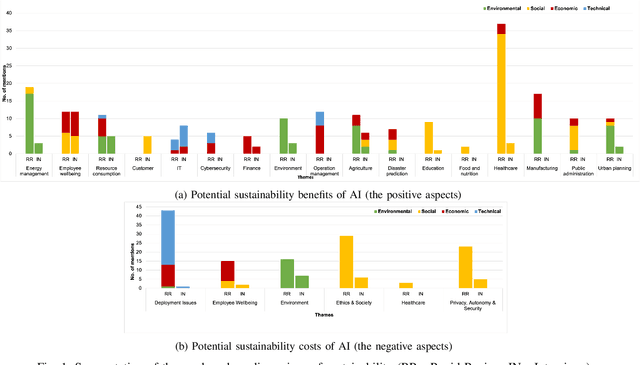
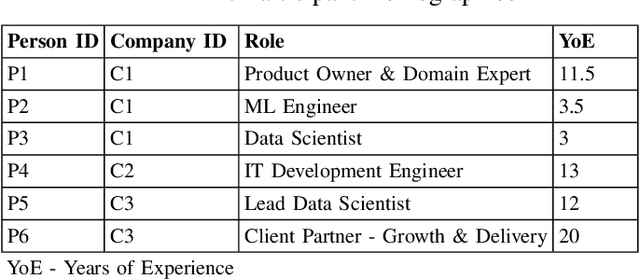
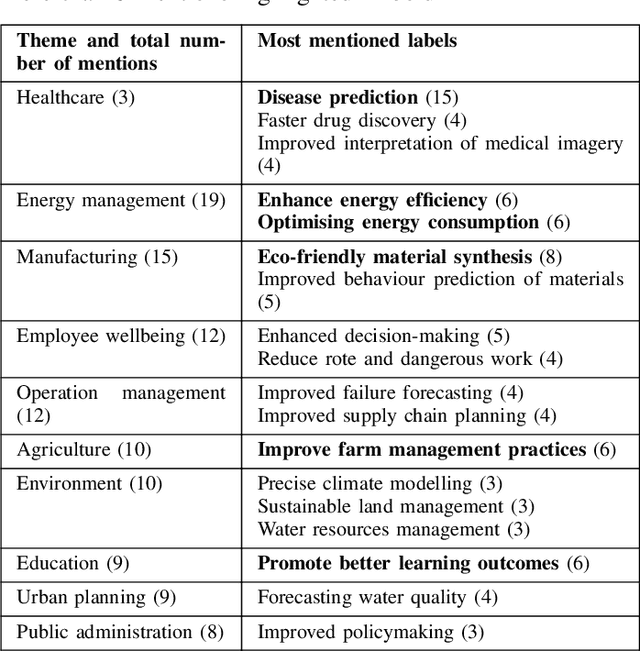
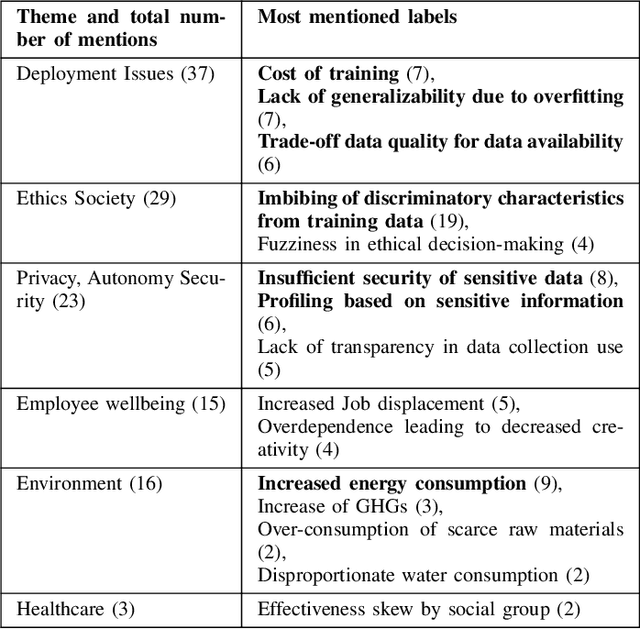
Recent advances in artificial intelligence (AI) capabilities have increased the eagerness of companies to integrate AI into software systems. While AI can be used to have a positive impact on several dimensions of sustainability, this is often overshadowed by its potential negative influence. While many studies have explored sustainability factors in isolation, there is insufficient holistic coverage of potential sustainability benefits or costs that practitioners need to consider during decision-making for AI adoption. We therefore aim to synthesize trade-offs related to sustainability in the context of integrating AI into software systems. We want to make the sustainability benefits and costs of integrating AI more transparent and accessible for practitioners. The study was conducted in collaboration with a Dutch financial organization. We first performed a rapid review that led to the inclusion of 151 research papers. Afterward, we conducted six semi-structured interviews to enrich the data with industry perspectives. The combined results showcase the potential sustainability benefits and costs of integrating AI. The labels synthesized from the review regarding potential sustainability benefits were clustered into 16 themes, with "energy management" being the most frequently mentioned one. 11 themes were identified in the interviews, with the top mentioned theme being "employee wellbeing". Regarding sustainability costs, the review discovered seven themes, with "deployment issues" being the most popular one, followed by "ethics & society". "Environmental issues" was the top theme from the interviews. Our results provide valuable insights to organizations and practitioners for understanding the potential sustainability implications of adopting AI.
Identifying architectural design decisions for achieving green ML serving
Feb 12, 2024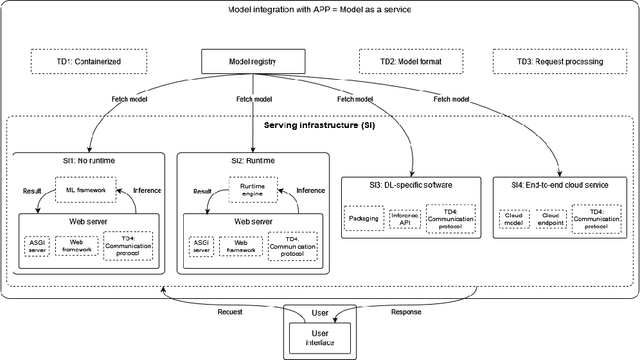
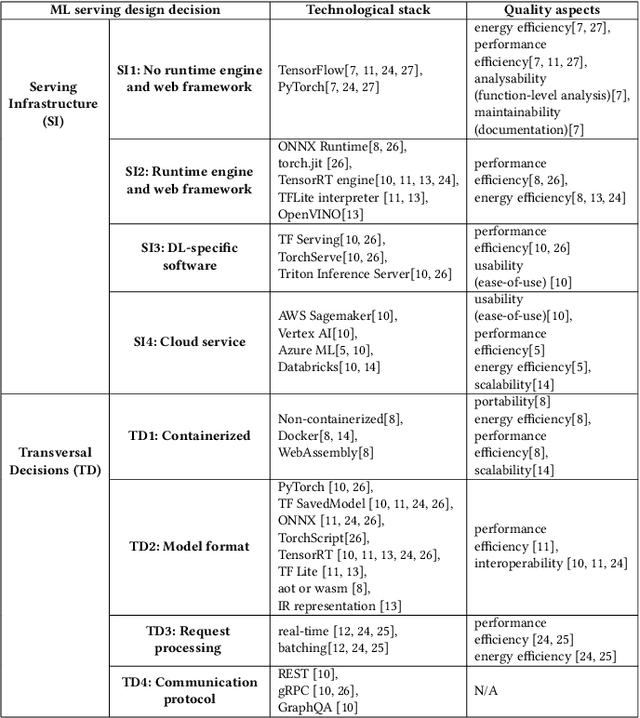
The growing use of large machine learning models highlights concerns about their increasing computational demands. While the energy consumption of their training phase has received attention, fewer works have considered the inference phase. For ML inference, the binding of ML models to the ML system for user access, known as ML serving, is a critical yet understudied step for achieving efficiency in ML applications. We examine the literature in ML architectural design decisions and Green AI, with a special focus on ML serving. The aim is to analyze ML serving architectural design decisions for the purpose of understanding and identifying them with respect to quality characteristics from the point of view of researchers and practitioners in the context of ML serving literature. Our results (i) identify ML serving architectural design decisions along with their corresponding components and associated technological stack, and (ii) provide an overview of the quality characteristics studied in the literature, including energy efficiency. This preliminary study is the first step in our goal to achieve green ML serving. Our analysis may aid ML researchers and practitioners in making green-aware architecture design decisions when serving their models.
Expert-Driven Monitoring of Operational ML Models
Jan 22, 2024We propose Expert Monitoring, an approach that leverages domain expertise to enhance the detection and mitigation of concept drift in machine learning (ML) models. Our approach supports practitioners by consolidating domain expertise related to concept drift-inducing events, making this expertise accessible to on-call personnel, and enabling automatic adaptability with expert oversight.
A Synthesis of Green Architectural Tactics for ML-Enabled Systems
Dec 15, 2023The rapid adoption of artificial intelligence (AI) and machine learning (ML) has generated growing interest in understanding their environmental impact and the challenges associated with designing environmentally friendly ML-enabled systems. While Green AI research, i.e., research that tries to minimize the energy footprint of AI, is receiving increasing attention, very few concrete guidelines are available on how ML-enabled systems can be designed to be more environmentally sustainable. In this paper, we provide a catalog of 30 green architectural tactics for ML-enabled systems to fill this gap. An architectural tactic is a high-level design technique to improve software quality, in our case environmental sustainability. We derived the tactics from the analysis of 51 peer-reviewed publications that primarily explore Green AI, and validated them using a focus group approach with three experts. The 30 tactics we identified are aimed to serve as an initial reference guide for further exploration into Green AI from a software engineering perspective, and assist in designing sustainable ML-enabled systems. To enhance transparency and facilitate their widespread use and extension, we make the tactics available online in easily consumable formats. Wide-spread adoption of these tactics has the potential to substantially reduce the societal impact of ML-enabled systems regarding their energy and carbon footprint.
Mining Energy-Related Practices in Robotics Software
Mar 25, 2021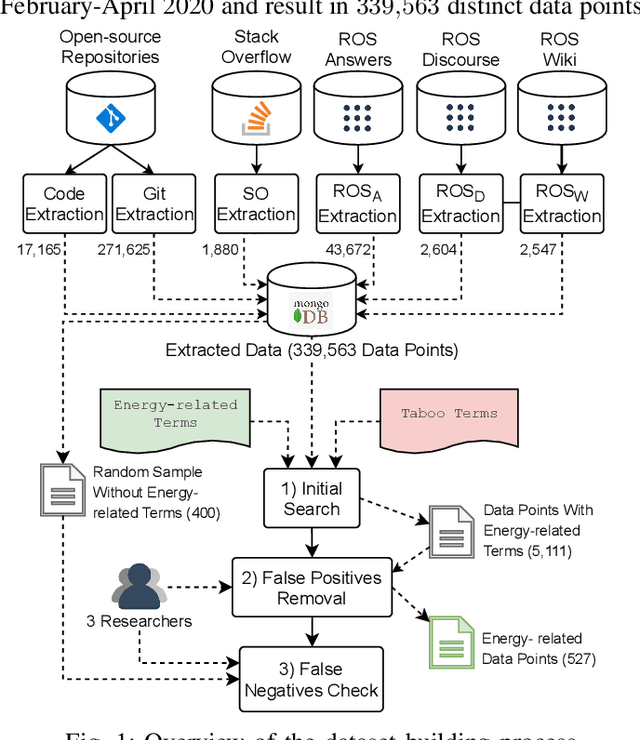
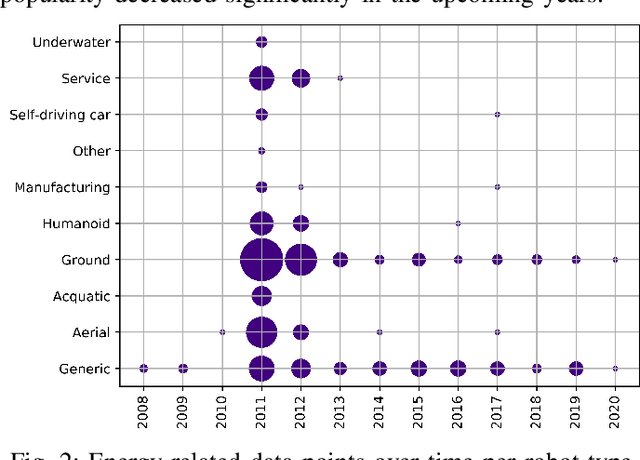
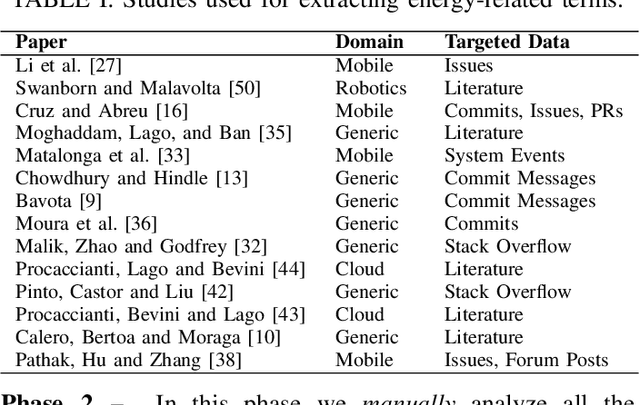
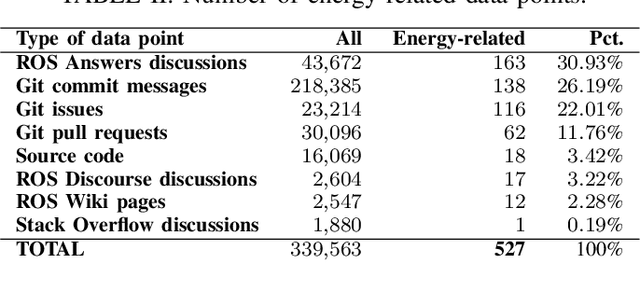
Robots are becoming more and more commonplace in many industry settings. This successful adoption can be partly attributed to (1) their increasingly affordable cost and (2) the possibility of developing intelligent, software-driven robots. Unfortunately, robotics software consumes significant amounts of energy. Moreover, robots are often battery-driven, meaning that even a small energy improvement can help reduce its energy footprint and increase its autonomy and user experience. In this paper, we study the Robot Operating System (ROS) ecosystem, the de-facto standard for developing and prototyping robotics software. We analyze 527 energy-related data points (including commits, pull-requests, and issues on ROS-related repositories, ROS-related questions on StackOverflow, ROS Discourse, ROS Answers, and the official ROS Wiki). Our results include a quantification of the interest of roboticists on software energy efficiency, 10 recurrent causes, and 14 solutions of energy-related issues, and their implied trade-offs with respect to other quality attributes. Those contributions support roboticists and researchers towards having energy-efficient software in future robotics projects.
* 11 pages