 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Sense of AI Agents Hype: Adoption, Architectures, and Takeaways from Practitioners
Mar 31, 2026To support practitioners in understanding how agentic systems are designed in real-world industrial practice, we present a review of practitioner conference talks on AI agents. We analyzed 138 recorded talks to examine how companies adopt agent-based architectures (Objective 1), identify recurring architectural strategies and patterns (Objective 2), and analyze application domains and technologies used to implement and operate LLM-driven agentic systems (Objective 3).
The More the Merrier? Navigating Accuracy vs. Energy Efficiency Design Trade-Offs in Ensemble Learning Systems
Jul 03, 2024Background: Machine learning (ML) model composition is a popular technique to mitigate shortcomings of a single ML model and to design more effective ML-enabled systems. While ensemble learning, i.e., forwarding the same request to several models and fusing their predictions, has been studied extensively for accuracy, we have insufficient knowledge about how to design energy-efficient ensembles. Objective: We therefore analyzed three types of design decisions for ensemble learning regarding a potential trade-off between accuracy and energy consumption: a) ensemble size, i.e., the number of models in the ensemble, b) fusion methods (majority voting vs. a meta-model), and c) partitioning methods (whole-dataset vs. subset-based training). Methods: By combining four popular ML algorithms for classification in different ensembles, we conducted a full factorial experiment with 11 ensembles x 4 datasets x 2 fusion methods x 2 partitioning methods (176 combinations). For each combination, we measured accuracy (F1-score) and energy consumption in J (for both training and inference). Results: While a larger ensemble size significantly increased energy consumption (size 2 ensembles consumed 37.49% less energy than size 3 ensembles, which in turn consumed 26.96% less energy than the size 4 ensembles), it did not significantly increase accuracy. Furthermore, majority voting outperformed meta-model fusion both in terms of accuracy (Cohen's d of 0.38) and energy consumption (Cohen's d of 0.92). Lastly, subset-based training led to significantly lower energy consumption (Cohen's d of 0.91), while training on the whole dataset did not increase accuracy significantly. Conclusions: From a Green AI perspective, we recommend designing ensembles of small size (2 or maximum 3 models), using subset-based training, majority voting, and energy-efficient ML algorithms like decision trees, Naive Bayes, or KNN.
How to Sustainably Monitor ML-Enabled Systems? Accuracy and Energy Efficiency Tradeoffs in Concept Drift Detection
Apr 30, 2024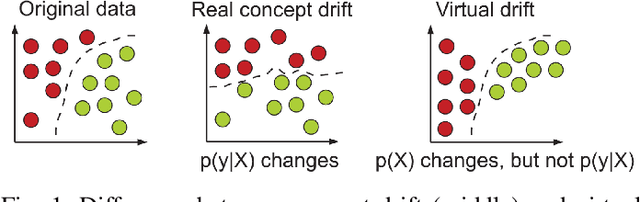
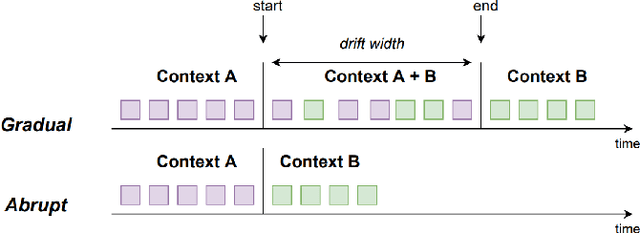
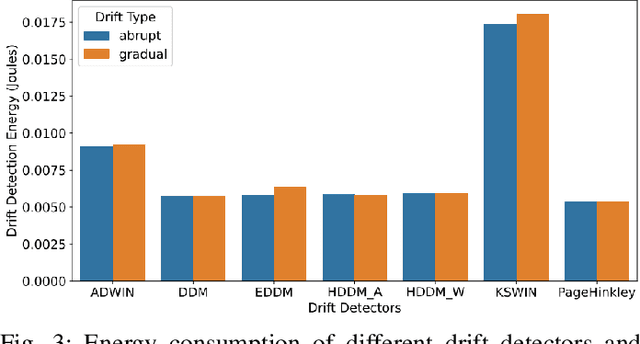
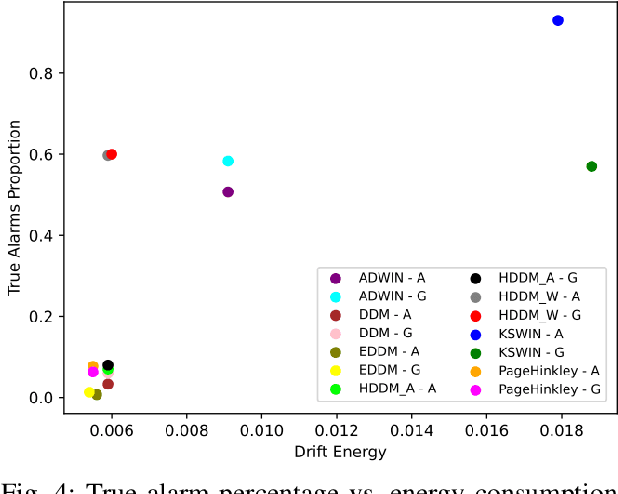
ML-enabled systems that are deployed in a production environment typically suffer from decaying model prediction quality through concept drift, i.e., a gradual change in the statistical characteristics of a certain real-world domain. To combat this, a simple solution is to periodically retrain ML models, which unfortunately can consume a lot of energy. One recommended tactic to improve energy efficiency is therefore to systematically monitor the level of concept drift and only retrain when it becomes unavoidable. Different methods are available to do this, but we know very little about their concrete impact on the tradeoff between accuracy and energy efficiency, as these methods also consume energy themselves. To address this, we therefore conducted a controlled experiment to study the accuracy vs. energy efficiency tradeoff of seven common methods for concept drift detection. We used five synthetic datasets, each in a version with abrupt and one with gradual drift, and trained six different ML models as base classifiers. Based on a full factorial design, we tested 420 combinations (7 drift detectors * 5 datasets * 2 types of drift * 6 base classifiers) and compared energy consumption and drift detection accuracy. Our results indicate that there are three types of detectors: a) detectors that sacrifice energy efficiency for detection accuracy (KSWIN), b) balanced detectors that consume low to medium energy with good accuracy (HDDM_W, ADWIN), and c) detectors that consume very little energy but are unusable in practice due to very poor accuracy (HDDM_A, PageHinkley, DDM, EDDM). By providing rich evidence for this energy efficiency tactic, our findings support ML practitioners in choosing the best suited method of concept drift detection for their ML-enabled systems.