 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecturally Significant MLOps Guidelines for ML Model Integration and Deployment: a Gray Literature Review
Jun 03, 2026Context. Despite the growing adoption of Machine Learning Operations (MLOps), teams often approach MLOps projects in an ad hoc manner due to the lack of consolidated architectural guidance. The community would benefit from a reference that synthesizes knowledge to inform the architectural design of MLOps systems, especially regarding the integration and deployment of ML models. Objective. In response, our goal is to provide a comprehensive overview of architecturally significant guidelines for the integration and deployment of ML models in MLOps systems. Method. We conduct a gray literature review of 103 web sources to analyze state-of-practice knowledge on MLOps model integration and deployment. We then apply thematic analysis to synthesize these practices into recommended guidelines. Results. We contribute a collection of 25 architecturally significant MLOps guidelines for model integration and deployment, organized into five categories, and describe their impact on the overall system architecture. Conclusion. Our results serve as an overview of state-of-practice MLOps guidelines to support researchers and practitioners with the integration and deployment of ML models in their MLOps systems.
Expert-Driven Monitoring of Operational ML Models
Jan 22, 2024We propose Expert Monitoring, an approach that leverages domain expertise to enhance the detection and mitigation of concept drift in machine learning (ML) models. Our approach supports practitioners by consolidating domain expertise related to concept drift-inducing events, making this expertise accessible to on-call personnel, and enabling automatic adaptability with expert oversight.
SUAVE: An Exemplar for Self-Adaptive Underwater Vehicles
Mar 16, 2023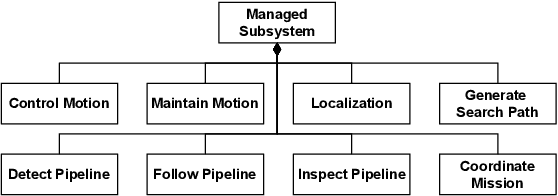
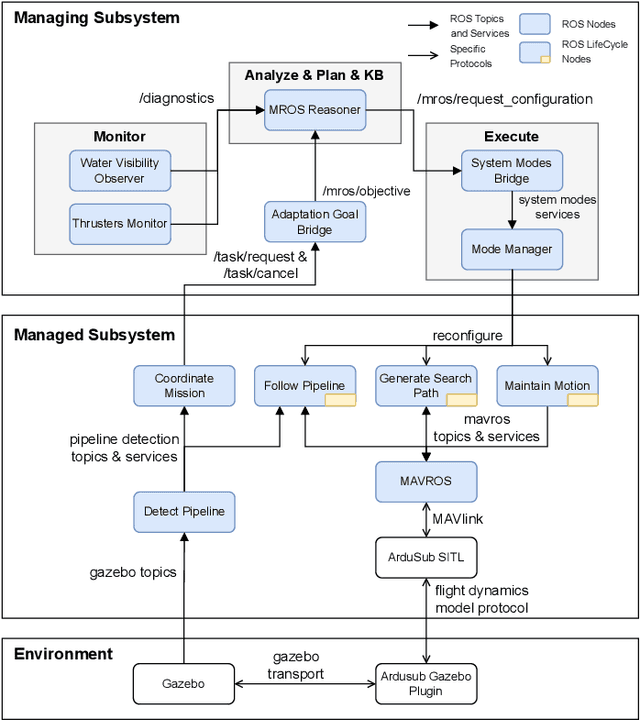


Once deployed in the real world, autonomous underwater vehicles (AUVs) are out of reach for human supervision yet need to take decisions to adapt to unstable and unpredictable environments. To facilitate research on self-adaptive AUVs, this paper presents SUAVE, an exemplar for two-layered system-level adaptation of AUVs, which clearly separates the application and self-adaptation concerns. The exemplar focuses on a mission for underwater pipeline inspection by a single AUV, implemented as a ROS2-based system. This mission must be completed while simultaneously accounting for uncertainties such as thruster failures and unfavorable environmental conditions. The paper discusses how SUAVE can be used with different self-adaptation frameworks, illustrated by an experiment using the Metacontrol framework to compare AUV behavior with and without self-adaptation. The experiment shows that the use of Metacontrol to adapt the AUV during its mission improves its performance when measured by the overall time taken to complete the mission or the length of the inspected pipeline.
Forming Ensembles at Runtime: A Machine Learning Approach
Apr 30, 2021
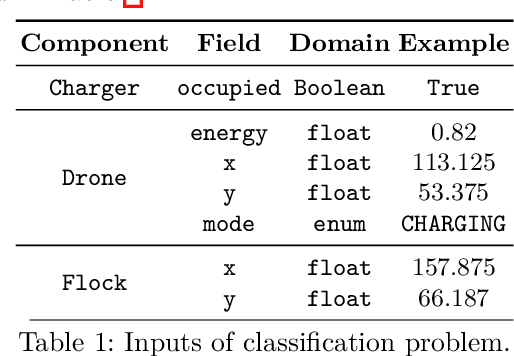
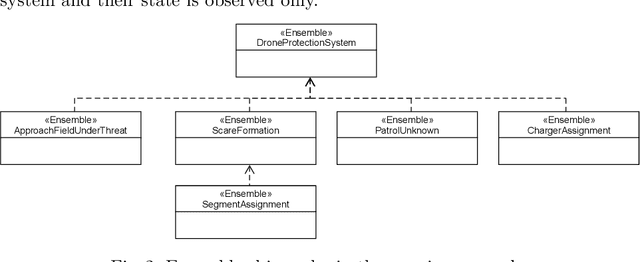
Smart system applications (SSAs) built on top of cyber-physical and socio-technical systems are increasingly composed of components that can work both autonomously and by cooperating with each other. Cooperating robots, fleets of cars and fleets of drones, emergency coordination systems are examples of SSAs. One approach to enable cooperation of SSAs is to form dynamic cooperation groups-ensembles-between components at runtime. Ensembles can be formed based on predefined rules that determine which components should be part of an ensemble based on their current state and the state of the environment (e.g., "group together 3 robots that are closer to the obstacle, their battery is sufficient and they would not be better used in another ensemble"). This is a computationally hard problem since all components are potential members of all possible ensembles at runtime. In our experience working with ensembles in several case studies the past years, using constraint programming to decide which ensembles should be formed does not scale for more than a limited number of components and ensembles. Also, the strict formulation in terms of hard/soft constraints does not easily permit for runtime self-adaptation via learning. This poses a serious limitation to the use of ensembles in large-scale and partially uncertain SSAs. To tackle this problem, in this paper we propose to recast the ensemble formation problem as a classification problem and use machine learning to efficiently form ensembles at scale.
Characterizing Technical Debt and Antipatterns in AI-Based Systems: A Systematic Mapping Study
Mar 17, 2021
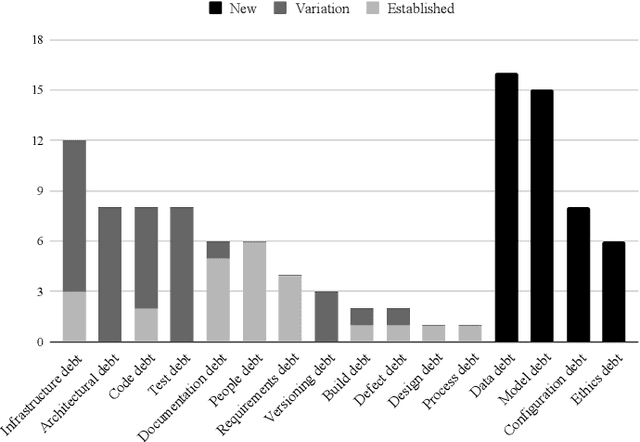
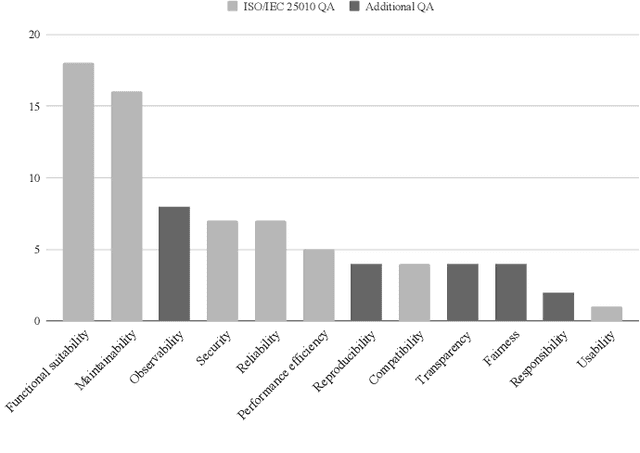
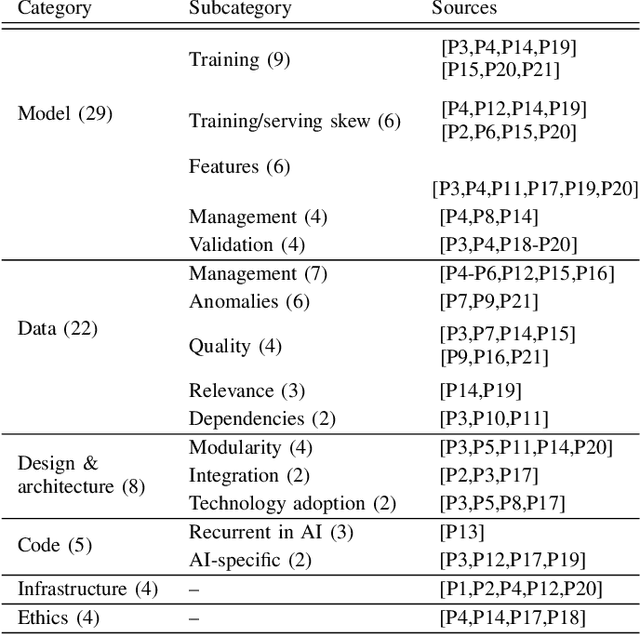
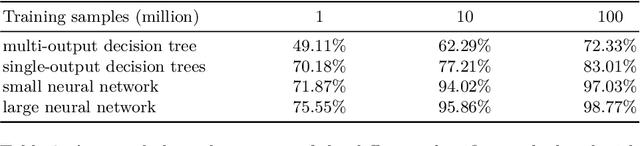
Background: With the rising popularity of Artificial Intelligence (AI), there is a growing need to build large and complex AI-based systems in a cost-effective and manageable way. Like with traditional software, Technical Debt (TD) will emerge naturally over time in these systems, therefore leading to challenges and risks if not managed appropriately. The influence of data science and the stochastic nature of AI-based systems may also lead to new types of TD or antipatterns, which are not yet fully understood by researchers and practitioners. Objective: The goal of our study is to provide a clear overview and characterization of the types of TD (both established and new ones) that appear in AI-based systems, as well as the antipatterns and related solutions that have been proposed. Method: Following the process of a systematic mapping study, 21 primary studies are identified and analyzed. Results: Our results show that (i) established TD types, variations of them, and four new TD types (data, model, configuration, and ethics debt) are present in AI-based systems, (ii) 72 antipatterns are discussed in the literature, the majority related to data and model deficiencies, and (iii) 46 solutions have been proposed, either to address specific TD types, antipatterns, or TD in general. Conclusions: Our results can support AI professionals with reasoning about and communicating aspects of TD present in their systems. Additionally, they can serve as a foundation for future research to further our understanding of TD in AI-based systems.
Decentralized Optimization of Vehicle Route Planning -- A Cross-City Comparative Study
Jan 10, 2020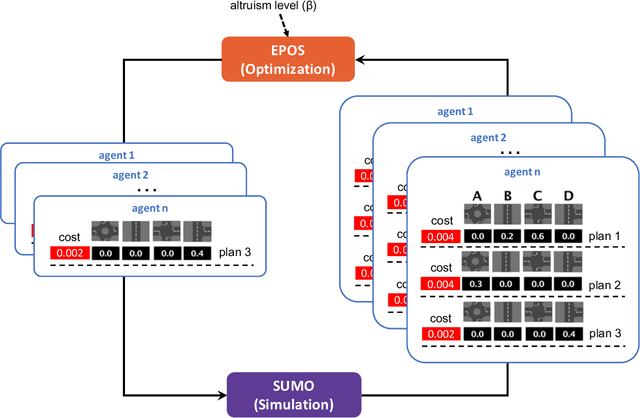
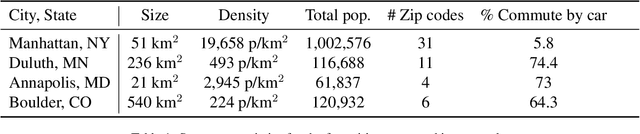

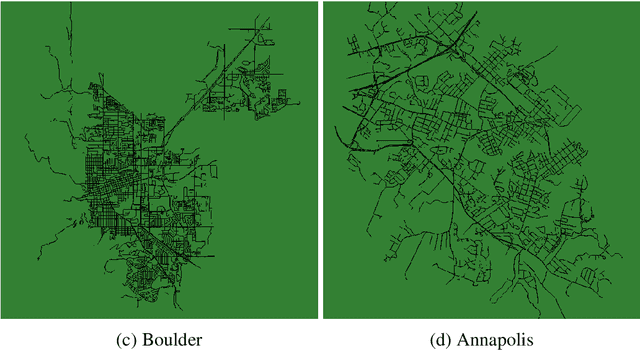
New mobility concepts are at the forefront of research and innovation in smart cities. The introduction of connected and autonomous vehicles enables new possibilities in vehicle routing. Specifically, knowing the origin and destination of each agent in the network can allow for real-time routing of the vehicles to optimize network performance. However, this relies on individual vehicles being "altruistic" i.e., being willing to accept an alternative non-preferred route in order to achieve a network-level performance goal. In this work, we conduct a study to compare different levels of agent altruism and the resulting effect on the network-level traffic performance. Specifically, this study compares the effects of different underlying urban structures on the overall network performance, and investigates which characteristics of the network make it possible to realize routing improvements using a decentralized optimization router. The main finding is that, with increased vehicle altruism, it is possible to balance traffic flow among the links of the network. We show evidence that the decentralized optimization router is more effective with networks of high load while we study the influence of cities characteristics, in particular: networks with a higher number of nodes (intersections) or edges (roads) per unit area allow for more possible alternate routes, and thus higher potential to improve network performance.