 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy consumption of code small language models serving with runtime engines and execution providers
Dec 19, 2024Background. The rapid growth of Language Models (LMs), particularly in code generation, requires substantial computational resources, raising concerns about energy consumption and environmental impact. Optimizing LMs inference for energy efficiency is crucial, and Small Language Models (SLMs) offer a promising solution to reduce resource demands. Aim. Our goal is to analyze the impact of deep learning runtime engines and execution providers on energy consumption, execution time, and computing-resource utilization from the point of view of software engineers conducting inference in the context of code SLMs. Method. We conducted a technology-oriented, multi-stage experimental pipeline using twelve code generation SLMs to investigate energy consumption, execution time, and computing-resource utilization across the configurations. Results. Significant differences emerged across configurations. CUDA execution provider configurations outperformed CPU execution provider configurations in both energy consumption and execution time. Among the configurations, TORCH paired with CUDA demonstrated the greatest energy efficiency, achieving energy savings from 37.99% up to 89.16% compared to other serving configurations. Similarly, optimized runtime engines like ONNX with the CPU execution provider achieved from 8.98% up to 72.04% energy savings within CPU-based configurations. Also, TORCH paired with CUDA exhibited efficient computing-resource utilization. Conclusions. Serving configuration choice significantly impacts energy efficiency. While further research is needed, we recommend the above configurations best suited to software engineers' requirements for enhancing serving efficiency in energy and performance.
Identifying architectural design decisions for achieving green ML serving
Feb 12, 2024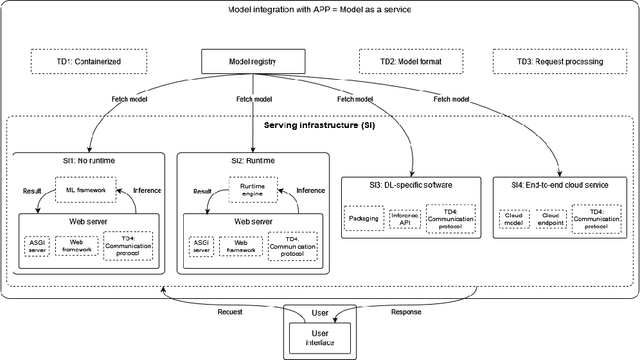
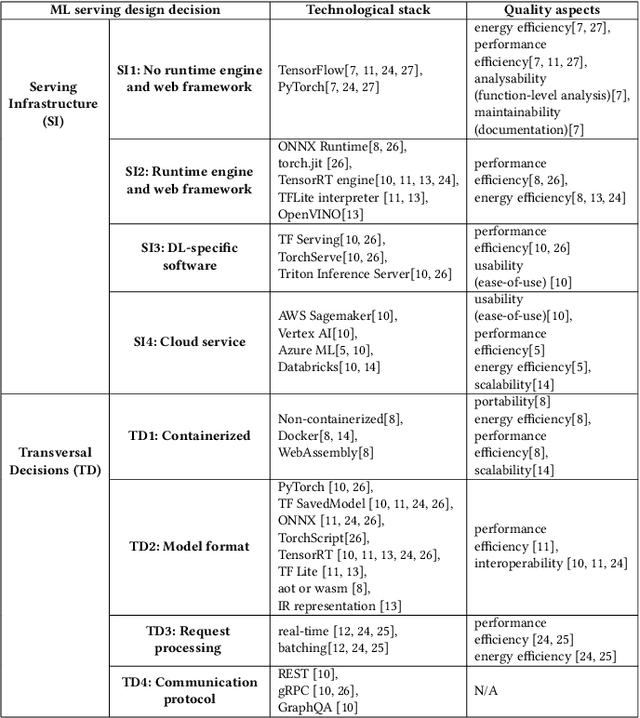
The growing use of large machine learning models highlights concerns about their increasing computational demands. While the energy consumption of their training phase has received attention, fewer works have considered the inference phase. For ML inference, the binding of ML models to the ML system for user access, known as ML serving, is a critical yet understudied step for achieving efficiency in ML applications. We examine the literature in ML architectural design decisions and Green AI, with a special focus on ML serving. The aim is to analyze ML serving architectural design decisions for the purpose of understanding and identifying them with respect to quality characteristics from the point of view of researchers and practitioners in the context of ML serving literature. Our results (i) identify ML serving architectural design decisions along with their corresponding components and associated technological stack, and (ii) provide an overview of the quality characteristics studied in the literature, including energy efficiency. This preliminary study is the first step in our goal to achieve green ML serving. Our analysis may aid ML researchers and practitioners in making green-aware architecture design decisions when serving their models.
Towards green AI-based software systems: an architecture-centric approach
Jul 19, 2023

Nowadays, AI-based systems have achieved outstanding results and have outperformed humans in different domains. However, the processes of training AI models and inferring from them require high computational resources, which pose a significant challenge in the current energy efficiency societal demand. To cope with this challenge, this research project paper describes the main vision, goals, and expected outcomes of the GAISSA project. The GAISSA project aims at providing data scientists and software engineers tool-supported, architecture-centric methods for the modelling and development of green AI-based systems. Although the project is in an initial stage, we describe the current research results, which illustrate the potential to achieve GAISSA objectives.