 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal computations in Semi Markovian Structural Causal Models using divide and conquer
Nov 17, 2025
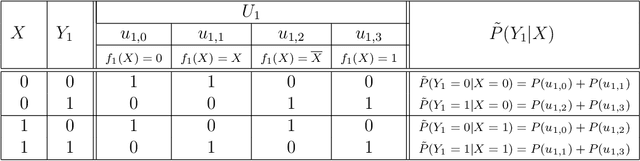


Recently, Bjøru et al. proposed a novel divide-and-conquer algorithm for bounding counterfactual probabilities in structural causal models (SCMs). They assumed that the SCMs were learned from purely observational data, leading to an imprecise characterization of the marginal distributions of exogenous variables. Their method leveraged the canonical representation of structural equations to decompose a general SCM with high-cardinality exogenous variables into a set of sub-models with low-cardinality exogenous variables. These sub-models had precise marginals over the exogenous variables and therefore admitted efficient exact inference. The aggregated results were used to bound counterfactual probabilities in the original model. The approach was developed for Markovian models, where each exogenous variable affects only a single endogenous variable. In this paper, we investigate extending the methodology to \textit{semi-Markovian} SCMs, where exogenous variables may influence multiple endogenous variables. Such models are capable of representing confounding relationships that Markovian models cannot. We illustrate the challenges of this extension using a minimal example, which motivates a set of alternative solution strategies. These strategies are evaluated both theoretically and through a computational study.
How do Machine Learning Models Change?
Nov 14, 2024
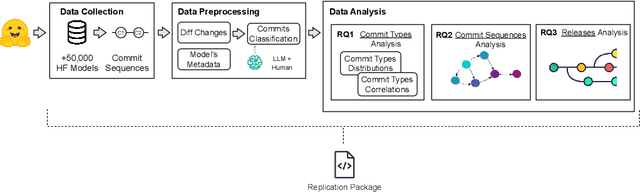
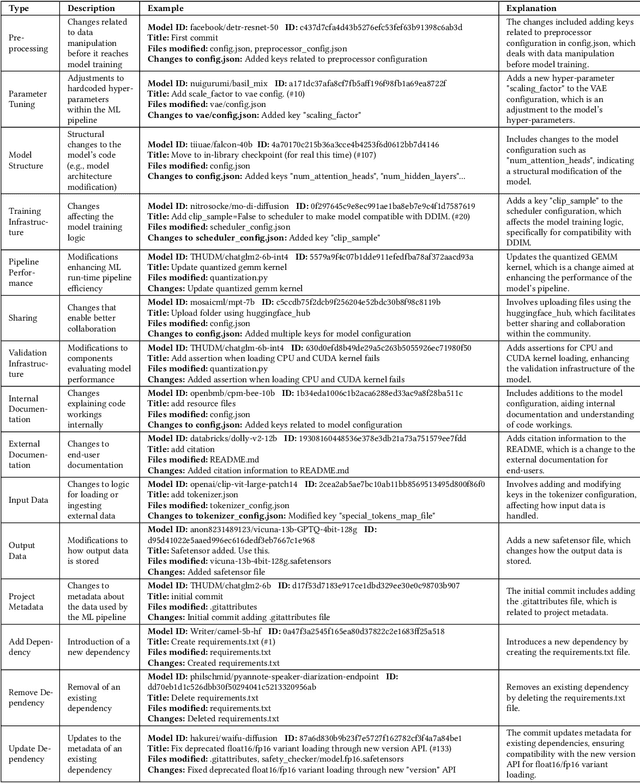
The proliferation of Machine Learning (ML) models and their open-source implementations has transformed Artificial Intelligence research and applications. Platforms like Hugging Face (HF) enable the development, sharing, and deployment of these models, fostering an evolving ecosystem. While previous studies have examined aspects of models hosted on platforms like HF, a comprehensive longitudinal study of how these models change remains underexplored. This study addresses this gap by utilizing both repository mining and longitudinal analysis methods to examine over 200,000 commits and 1,200 releases from over 50,000 models on HF. We replicate and extend an ML change taxonomy for classifying commits and utilize Bayesian networks to uncover patterns in commit and release activities over time. Our findings indicate that commit activities align with established data science methodologies, such as CRISP-DM, emphasizing iterative refinement and continuous improvement. Additionally, release patterns tend to consolidate significant updates, particularly in documentation, distinguishing between granular changes and milestone-based releases. Furthermore, projects with higher popularity prioritize infrastructure enhancements early in their lifecycle, and those with intensive collaboration practices exhibit improved documentation standards. These and other insights enhance the understanding of model changes on community platforms and provide valuable guidance for best practices in model maintenance.
Counterfactual Reasoning with Probabilistic Graphical Models for Analyzing Socioecological Systems
Jan 18, 2024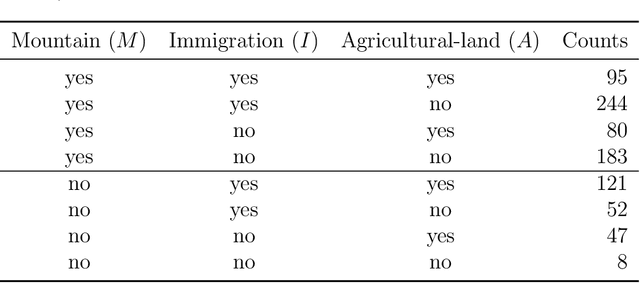
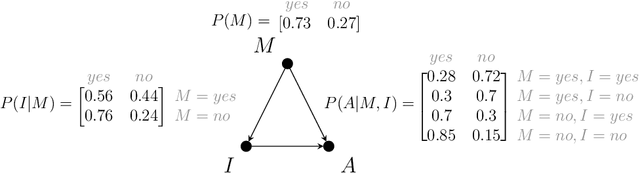
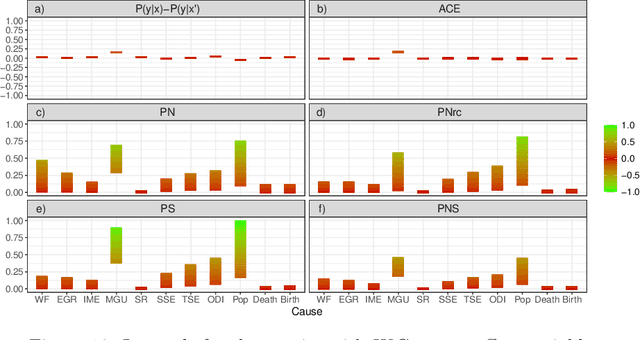

Causal and counterfactual reasoning are emerging directions in data science that allow us to reason about hypothetical scenarios. This is particularly useful in domains where experimental data are usually not available. In the context of environmental and ecological sciences, causality enables us, for example, to predict how an ecosystem would respond to hypothetical interventions. A structural causal model is a class of probabilistic graphical models for causality, which, due to its intuitive nature, can be easily understood by experts in multiple fields. However, certain queries, called unidentifiable, cannot be calculated in an exact and precise manner. This paper proposes applying a novel and recent technique for bounding unidentifiable queries within the domain of socioecological systems. Our findings indicate that traditional statistical analysis, including probabilistic graphical models, can identify the influence between variables. However, such methods do not offer insights into the nature of the relationship, specifically whether it involves necessity or sufficiency. This is where counterfactual reasoning becomes valuable.
InferPy: Probabilistic Modeling with Deep Neural Networks Made Easy
Sep 04, 2019


InferPy is a Python package for probabilistic modeling with deep neural networks. InferPy defines a user-friendly API which trades-off model complexity with ease of use, unlike other libraries whose focus is on dealing with very general probabilistic models at the cost of having a more complex API. In particular, InferPy allows to define, learn and evaluate general hierarchical probabilistic models containing deep neural networks in a compact and simple way. InferPy is built on top of Tensorflow, Edward2 and Keras.
Probabilistic Models with Deep Neural Networks
Aug 09, 2019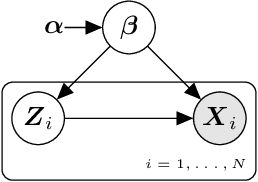
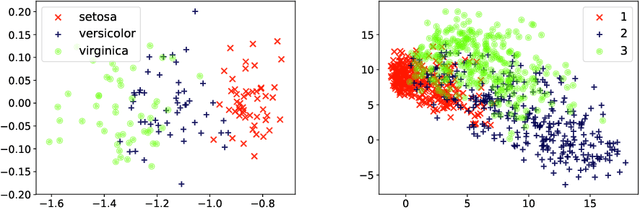
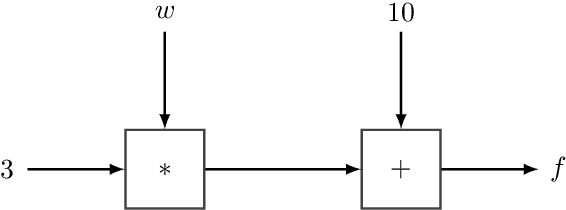
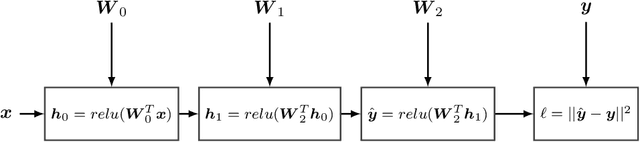
Recent advances in statistical inference have significantly expanded the toolbox of probabilistic modeling. Historically, probabilistic modeling has been constrained to (i) very restricted model classes where exact or approximate probabilistic inference were feasible, and (ii) small or medium-sized data sets which fit within the main memory of the computer. However, developments in variational inference, a general form of approximate probabilistic inference originated in statistical physics, are allowing probabilistic modeling to overcome these restrictions: (i) Approximate probabilistic inference is now possible over a broad class of probabilistic models containing a large number of parameters, and (ii) scalable inference methods based on stochastic gradient descent and distributed computation engines allow to apply probabilistic modeling over massive data sets. One important practical consequence of these advances is the possibility to include deep neural networks within a probabilistic model to capture complex non-linear stochastic relationships between random variables. These advances in conjunction with the release of novel probabilistic modeling toolboxes have greatly expanded the scope of application of probabilistic models, and allow these models to take advantage of the recent strides made by the deep learning community. In this paper we review the main concepts, methods and tools needed to use deep neural networks within a probabilistic modeling framework.
AMIDST: a Java Toolbox for Scalable Probabilistic Machine Learning
Apr 04, 2017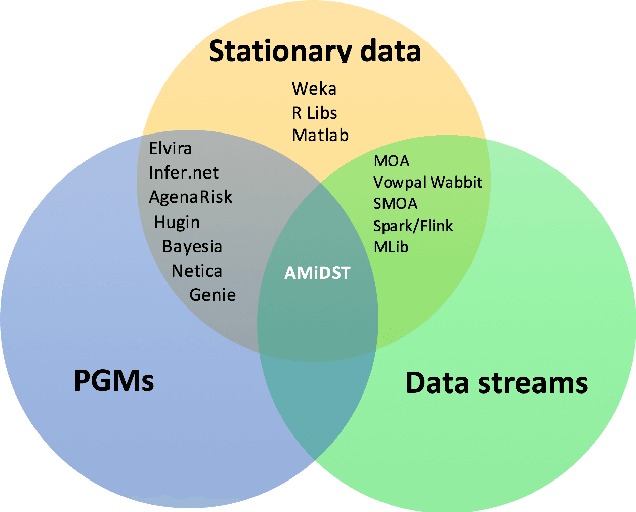
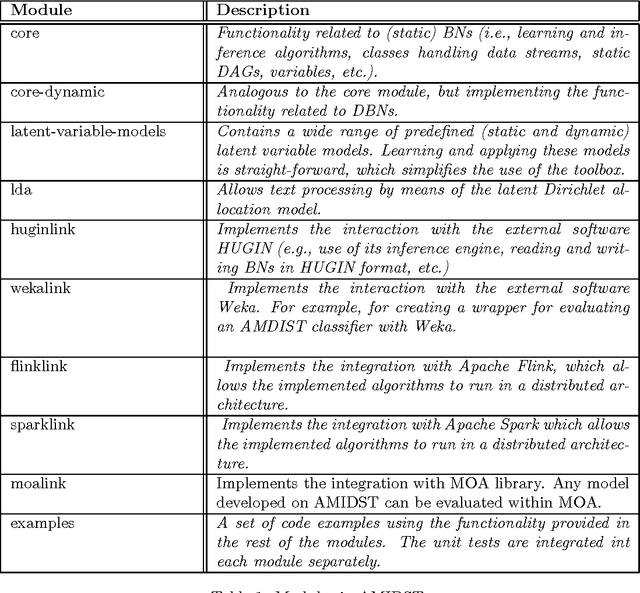
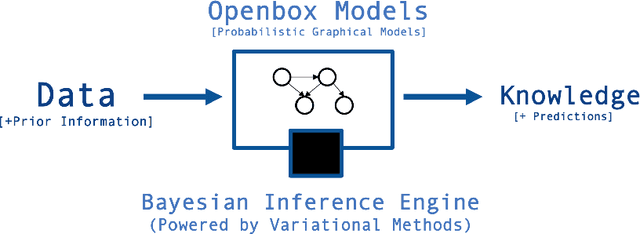

The AMIDST Toolbox is a software for scalable probabilistic machine learning with a spe- cial focus on (massive) streaming data. The toolbox supports a flexible modeling language based on probabilistic graphical models with latent variables and temporal dependencies. The specified models can be learnt from large data sets using parallel or distributed implementa- tions of Bayesian learning algorithms for either streaming or batch data. These algorithms are based on a flexible variational message passing scheme, which supports discrete and continu- ous variables from a wide range of probability distributions. AMIDST also leverages existing functionality and algorithms by interfacing to software tools such as Flink, Spark, MOA, Weka, R and HUGIN. AMIDST is an open source toolbox written in Java and available at http://www.amidsttoolbox.com under the Apache Software License version 2.0.