 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do Machine Learning Models Change?
Nov 14, 2024
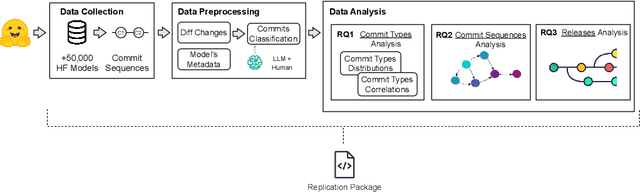
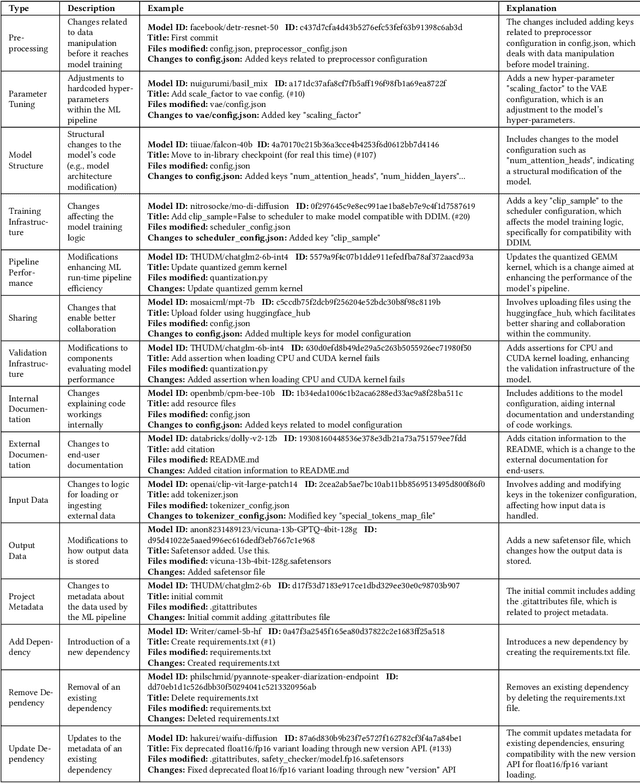
The proliferation of Machine Learning (ML) models and their open-source implementations has transformed Artificial Intelligence research and applications. Platforms like Hugging Face (HF) enable the development, sharing, and deployment of these models, fostering an evolving ecosystem. While previous studies have examined aspects of models hosted on platforms like HF, a comprehensive longitudinal study of how these models change remains underexplored. This study addresses this gap by utilizing both repository mining and longitudinal analysis methods to examine over 200,000 commits and 1,200 releases from over 50,000 models on HF. We replicate and extend an ML change taxonomy for classifying commits and utilize Bayesian networks to uncover patterns in commit and release activities over time. Our findings indicate that commit activities align with established data science methodologies, such as CRISP-DM, emphasizing iterative refinement and continuous improvement. Additionally, release patterns tend to consolidate significant updates, particularly in documentation, distinguishing between granular changes and milestone-based releases. Furthermore, projects with higher popularity prioritize infrastructure enhancements early in their lifecycle, and those with intensive collaboration practices exhibit improved documentation standards. These and other insights enhance the understanding of model changes on community platforms and provide valuable guidance for best practices in model maintenance.
Lessons Learned from Mining the Hugging Face Repository
Feb 11, 2024The rapidly evolving fields of Machine Learning (ML) and Artificial Intelligence have witnessed the emergence of platforms like Hugging Face (HF) as central hubs for model development and sharing. This experience report synthesizes insights from two comprehensive studies conducted on HF, focusing on carbon emissions and the evolutionary and maintenance aspects of ML models. Our objective is to provide a practical guide for future researchers embarking on mining software repository studies within the HF ecosystem to enhance the quality of these studies. We delve into the intricacies of the replication package used in our studies, highlighting the pivotal tools and methodologies that facilitated our analysis. Furthermore, we propose a nuanced stratified sampling strategy tailored for the diverse HF Hub dataset, ensuring a representative and comprehensive analytical approach. The report also introduces preliminary guidelines, transitioning from repository mining to cohort studies, to establish causality in repository mining studies, particularly within the ML model of HF context. This transition is inspired by existing frameworks and is adapted to suit the unique characteristics of the HF model ecosystem. Our report serves as a guiding framework for researchers, contributing to the responsible and sustainable advancement of ML, and fostering a deeper understanding of the broader implications of ML models.
Exploring the Carbon Footprint of Hugging Face's ML Models: A Repository Mining Study
May 18, 2023



The rise of machine learning (ML) systems has exacerbated their carbon footprint due to increased capabilities and model sizes. However, there is scarce knowledge on how the carbon footprint of ML models is actually measured, reported, and evaluated. In light of this, the paper aims to analyze the measurement of the carbon footprint of 1,417 ML models and associated datasets on Hugging Face, which is the most popular repository for pretrained ML models. The goal is to provide insights and recommendations on how to report and optimize the carbon efficiency of ML models. The study includes the first repository mining study on the Hugging Face Hub API on carbon emissions. This study seeks to answer two research questions: (1) how do ML model creators measure and report carbon emissions on Hugging Face Hub?, and (2) what aspects impact the carbon emissions of training ML models? The study yielded several key findings. These include a decreasing proportion of carbon emissions-reporting models, a slight decrease in reported carbon footprint on Hugging Face over the past 2 years, and a continued dominance of NLP as the main application domain. Furthermore, the study uncovers correlations between carbon emissions and various attributes such as model size, dataset size, and ML application domains. These results highlight the need for software measurements to improve energy reporting practices and promote carbon-efficient model development within the Hugging Face community. In response to this issue, two classifications are proposed: one for categorizing models based on their carbon emission reporting practices and another for their carbon efficiency. The aim of these classification proposals is to foster transparency and sustainable model development within the ML community.