 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Localization via Fine-tuning Large Language Models with Mutation Generated Stack Traces
Jan 29, 2025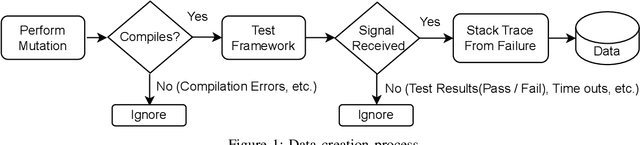
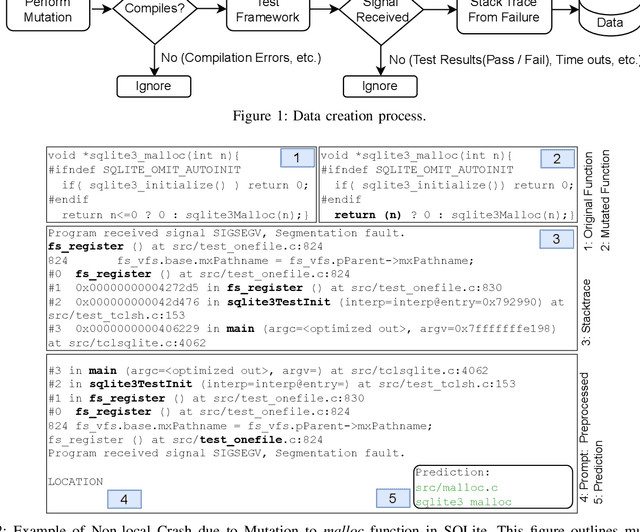
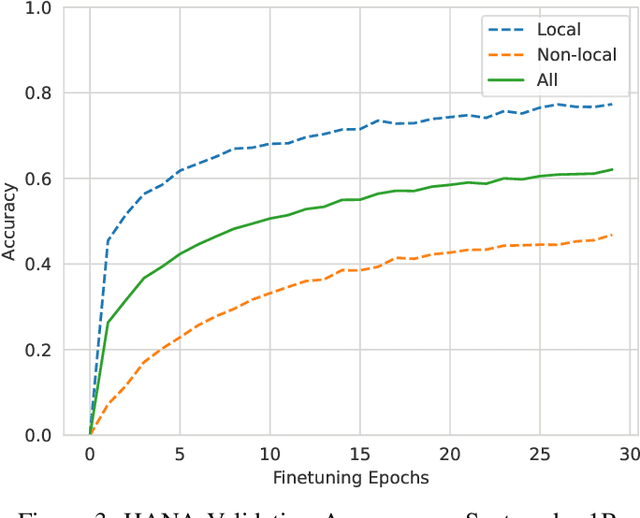
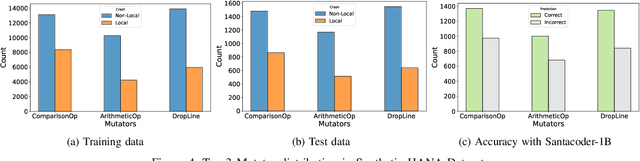
Abrupt and unexpected terminations of software are termed as software crashes. They can be challenging to analyze. Finding the root cause requires extensive manual effort and expertise to connect information sources like stack traces, source code, and logs. Typical approaches to fault localization require either test failures or source code. Crashes occurring in production environments, such as that of SAP HANA, provide solely crash logs and stack traces. We present a novel approach to localize faults based only on the stack trace information and no additional runtime information, by fine-tuning large language models (LLMs). We address complex cases where the root cause of a crash differs from the technical cause, and is not located in the innermost frame of the stack trace. As the number of historic crashes is insufficient to fine-tune LLMs, we augment our dataset by leveraging code mutators to inject synthetic crashes into the code base. By fine-tuning on 64,369 crashes resulting from 4.1 million mutations of the HANA code base, we can correctly predict the root cause location of a crash with an accuracy of 66.9\% while baselines only achieve 12.6% and 10.6%. We substantiate the generalizability of our approach by evaluating on two additional open-source databases, SQLite and DuckDB, achieving accuracies of 63% and 74%, respectively. Across all our experiments, fine-tuning consistently outperformed prompting non-finetuned LLMs for localizing faults in our datasets.
On Enhancing Root Cause Analysis with SQL Summaries for Failures in Database Workload Replays at SAP HANA
Dec 18, 2024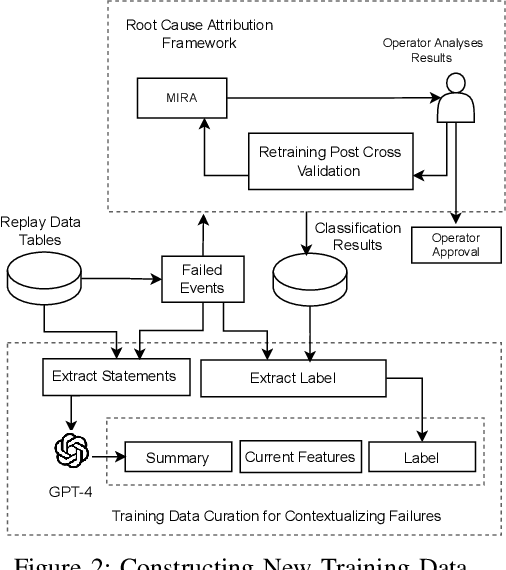
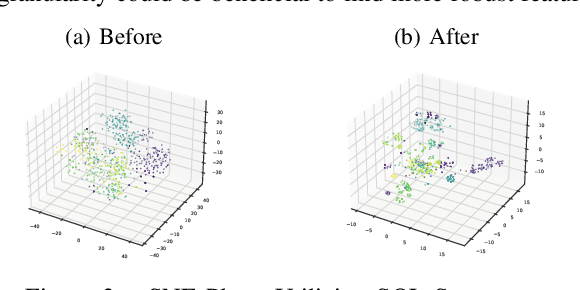
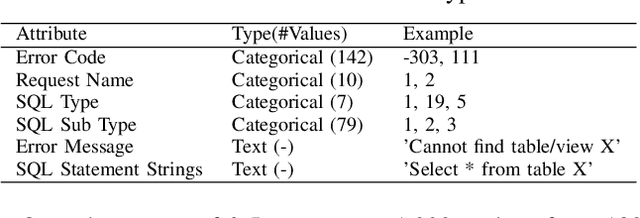
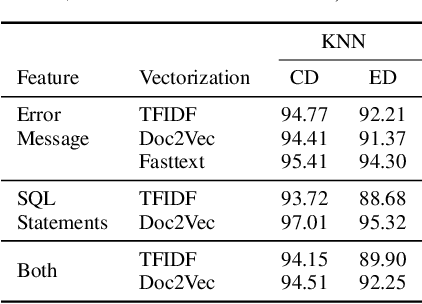
Capturing the workload of a database and replaying this workload for a new version of the database can be an effective approach for regression testing. However, false positive errors caused by many factors such as data privacy limitations, time dependency or non-determinism in multi-threaded environment can negatively impact the effectiveness. Therefore, we employ a machine learning based framework to automate the root cause analysis of failures found during replays. However, handling unseen novel issues not found in the training data is one general challenge of machine learning approaches with respect to generalizability of the learned model. We describe how we continue to address this challenge for more robust long-term solutions. From our experience, retraining with new failures is inadequate due to features overlapping across distinct root causes. Hence, we leverage a large language model (LLM) to analyze failed SQL statements and extract concise failure summaries as an additional feature to enhance the classification process. Our experiments show the F1-Macro score improved by 4.77% for our data. We consider our approach beneficial for providing end users with additional information to gain more insights into the found issues and to improve the assessment of the replay results.