 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding the retraining of convolutional neural networks against adversarial inputs
Jul 12, 2022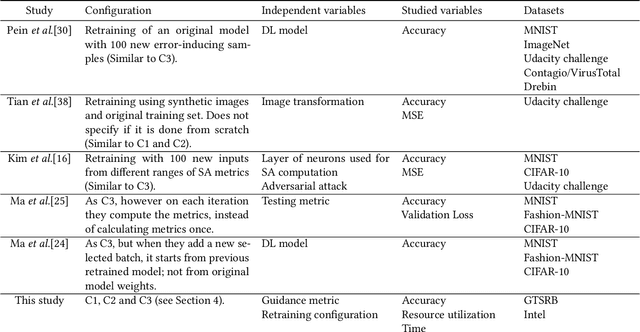
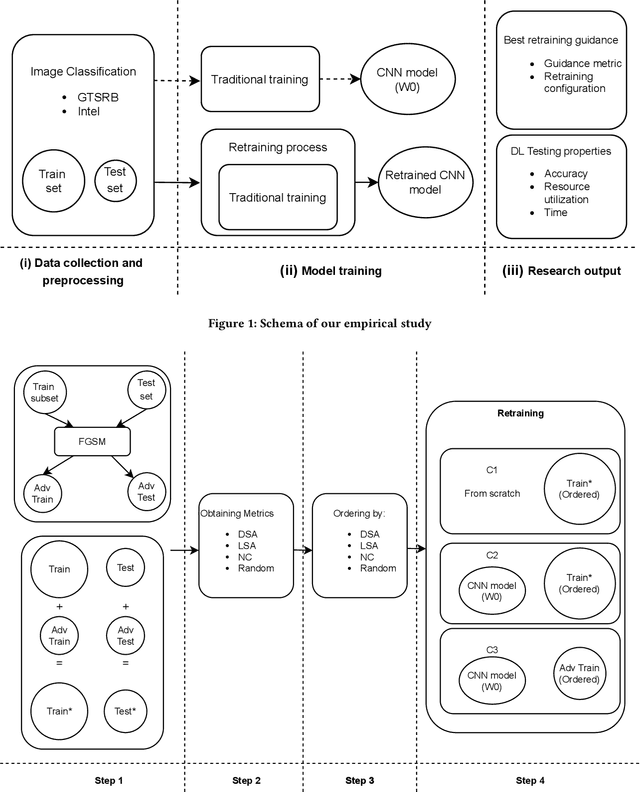

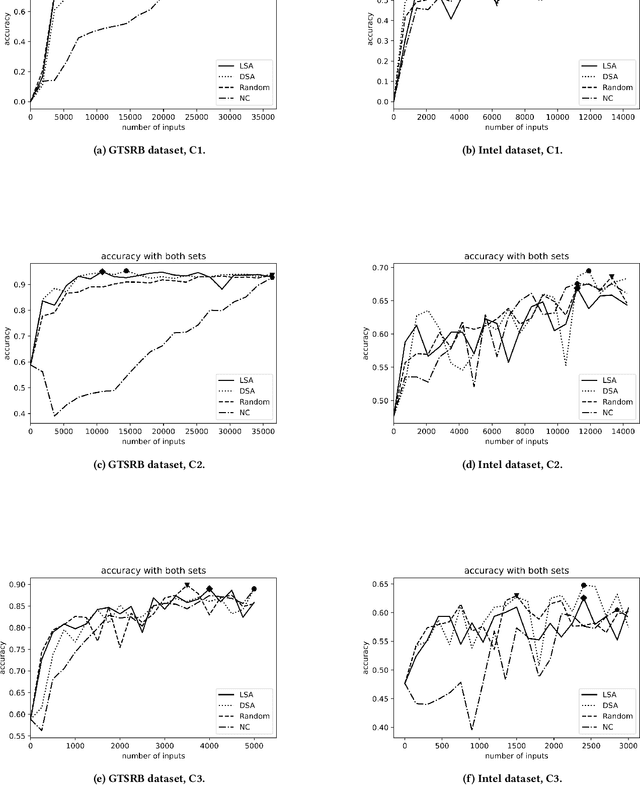
Background: When using deep learning models, there are many possible vulnerabilities and some of the most worrying are the adversarial inputs, which can cause wrong decisions with minor perturbations. Therefore, it becomes necessary to retrain these models against adversarial inputs, as part of the software testing process addressing the vulnerability to these inputs. Furthermore, for an energy efficient testing and retraining, data scientists need support on which are the best guidance metrics and optimal dataset configurations. Aims: We examined four guidance metrics for retraining convolutional neural networks and three retraining configurations. Our goal is to improve the models against adversarial inputs regarding accuracy, resource utilization and time from the point of view of a data scientist in the context of image classification. Method: We conducted an empirical study in two datasets for image classification. We explore: (a) the accuracy, resource utilization and time of retraining convolutional neural networks by ordering new training set by four different guidance metrics (neuron coverage, likelihood-based surprise adequacy, distance-based surprise adequacy and random), (b) the accuracy and resource utilization of retraining convolutional neural networks with three different configurations (from scratch and augmented dataset, using weights and augmented dataset, and using weights and only adversarial inputs). Results: We reveal that retraining with adversarial inputs from original weights and by ordering with surprise adequacy metrics gives the best model w.r.t. the used metrics. Conclusions: Although more studies are necessary, we recommend data scientists to use the above configuration and metrics to deal with the vulnerability to adversarial inputs of deep learning models, as they can improve their models against adversarial inputs without using many inputs.