 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multi-Objective Optimization for Bicycle Rebalancing in Shared Mobility Systems
Apr 09, 2026Dock-based bike-sharing systems exhibit spatial imbalances between bicycle supply and user demand, often addressed through overnight truck-based rebalancing. This work studies static overnight rebalancing under demand uncertainty modeled as a tri-objective optimization problem. The objectives minimize total travel distance, expected unmet demand, and a robustness-oriented unmet demand measure over high-demand scenarios. Route plans are evaluated via a recourse simulation that enforces truck loads and station capacity constraints across multiple demand realizations. The robustness objective supports selecting plans that reduce peak-demand service degradation. Trade-off solutions are approximated with Non-dominated Sorting Genetic Algorithm II using a permutation--partition encoding and domain-specific relocation operators, including a biased best-improvement move for station relocation. Experiments on the real Barcelona Bicing system with 460 stations show well-distributed Pareto sets and substantial contributions to the reference non-dominated set. Greedy constructive baselines mainly yield extreme solutions and are often dominated.
Green Optimization: Energy-aware Design of Metaheuristics by Using Machine Learning Surrogates to Cope with Real Problems
Feb 09, 2026Addressing real-world optimization challenges requires not only advanced metaheuristics but also continuous refinement of their internal mechanisms. This paper explores the integration of machine learning in the form of neural surrogate models into metaheuristics through a recent lens: energy consumption. While surrogates are widely used to reduce the computational cost of expensive objective functions, their combined impact on energy efficiency, algorithmic performance, and solution accuracy remains largely unquantified. We provide a critical investigation into this intersection, aiming to advance the design of energy-aware, surrogate-assisted search algorithms. Our experiments reveal substantial benefits: employing a state-of-the-art pre-trained surrogate can reduce energy consumption by up to 98\%, execution time by approximately 98%, and memory usage by around 99\%. Moreover, increasing the training dataset size further enhances these gains by lowering the per-use computational cost, while static pre-training versus continuous (iterative) retraining have relatively different advantages depending on whether we aim at time/energy or accuracy and general cost across problems, respectively. Surrogates also have a negative impact on costs and accuracy at times, and then they cannot be blindly adopted. These findings support a more holistic approach to surrogate-assisted optimization, integrating energy with time and predictive accuracy into performance assessments.
Energy-Aware Metaheuristics
Feb 09, 2026This paper presents a principled framework for designing energy-aware metaheuristics that operate under fixed energy budgets. We introduce a unified operator-level model that quantifies both numerical gain and energy usage, and define a robust Expected Improvement per Joule (EI/J) score that guides adaptive selection among operator variants during the search. The resulting energy-aware solvers dynamically choose between operators to self-control exploration and exploitation, aiming to maximize fitness gain under limited energy. We instantiate this framework with three representative metaheuristics - steady-state GA, PSO, and ILS - each equipped with both lightweight and heavy operator variants. Experiments on three heterogeneous combinatorial problems (Knapsack, NK-landscapes, and Error-Correcting Codes) show that the energy-aware variants consistently reach comparable fitness while requiring substantially less energy than their non-energy-aware baselines. EI/J values stabilize early and yield clear operator-selection patterns, with each solver reliably self-identifying the most improvement-per-Joule - efficient operator across problems.
A Methodology for Effective Surrogate Learning in Complex Optimization
Feb 09, 2026Solving complex problems requires continuous effort in developing theory and practice to cope with larger, more difficult scenarios. Working with surrogates is normal for creating a proxy that realistically models the problem into the computer. Thus, the question of how to best define and characterize such a surrogate model is of the utmost importance. In this paper, we introduce the PTME methodology to study deep learning surrogates by analyzing their Precision, Time, Memory, and Energy consumption. We argue that only a combination of numerical and physical performance can lead to a surrogate that is both a trusted scientific substitute for the real problem and an efficient experimental artifact for scalable studies. Here, we propose different surrogates for a real problem in optimally organizing the network of traffic lights in European cities and perform a PTME study on the surrogates' sampling methods, dataset sizes, and resource consumption. We further use the built surrogates in new optimization metaheuristics for decision-making in real cities. We offer better techniques and conclude that the PTME methodology can be used as a guideline for other applications and solvers.
Energy and Quality of Surrogate-Assisted Search Algorithms: a First Analysis
Aug 11, 2025Solving complex real problems often demands advanced algorithms, and then continuous improvements in the internal operations of a search technique are needed. Hybrid algorithms, parallel techniques, theoretical advances, and much more are needed to transform a general search algorithm into an efficient, useful one in practice. In this paper, we study how surrogates are helping metaheuristics from an important and understudied point of view: their energy profile. Even if surrogates are a great idea for substituting a time-demanding complex fitness function, the energy profile, general efficiency, and accuracy of the resulting surrogate-assisted metaheuristic still need considerable research. In this work, we make a first step in analyzing particle swarm optimization in different versions (including pre-trained and retrained neural networks as surrogates) for its energy profile (for both processor and memory), plus a further study on the surrogate accuracy to properly drive the search towards an acceptable solution. Our conclusions shed new light on this topic and could be understood as the first step towards a methodology for assessing surrogate-assisted algorithms not only accounting for time or numerical efficiency but also for energy and surrogate accuracy for a better, more holistic characterization of optimization and learning techniques.
* 8 pages, 8 figures, 2024 IEEE Congress on Evolutionary Computation (CEC)
Optimising Communication Overhead in Federated Learning Using NSGA-II
Apr 01, 2022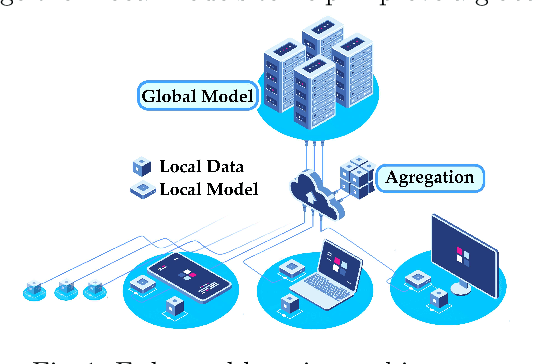

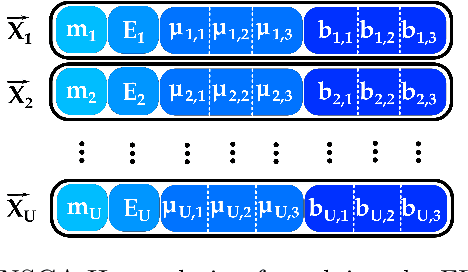
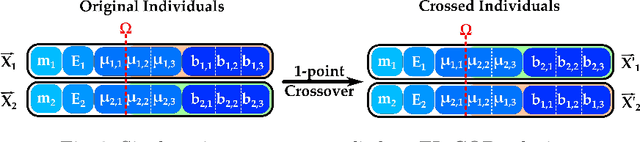
Federated learning is a training paradigm according to which a server-based model is cooperatively trained using local models running on edge devices and ensuring data privacy. These devices exchange information that induces a substantial communication load, which jeopardises the functioning efficiency. The difficulty of reducing this overhead stands in achieving this without decreasing the model's efficiency (contradictory relation). To do so, many works investigated the compression of the pre/mid/post-trained models and the communication rounds, separately, although they jointly contribute to the communication overload. Our work aims at optimising communication overhead in federated learning by (I) modelling it as a multi-objective problem and (II) applying a multi-objective optimization algorithm (NSGA-II) to solve it. To the best of the author's knowledge, this is the first work that \texttt{(I)} explores the add-in that evolutionary computation could bring for solving such a problem, and \texttt{(II)} considers both the neuron and devices features together. We perform the experimentation by simulating a server/client architecture with 4 slaves. We investigate both convolutional and fully-connected neural networks with 12 and 3 layers, 887,530 and 33,400 weights, respectively. We conducted the validation on the \texttt{MNIST} dataset containing 70,000 images. The experiments have shown that our proposal could reduce communication by 99% and maintain an accuracy equal to the one obtained by the FedAvg Algorithm that uses 100% of communications.
A Fresh Approach to Evaluate Performance in Distributed Parallel Genetic Algorithms
Jun 18, 2021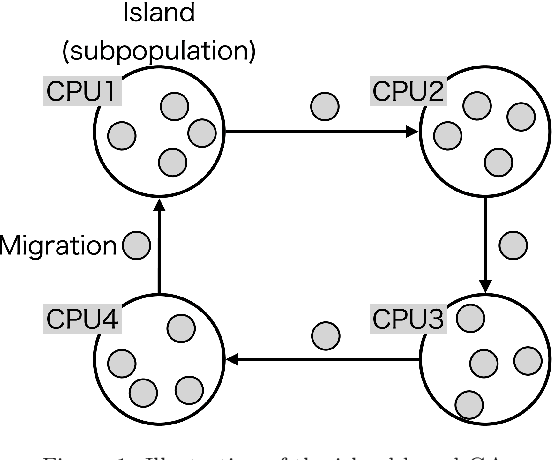


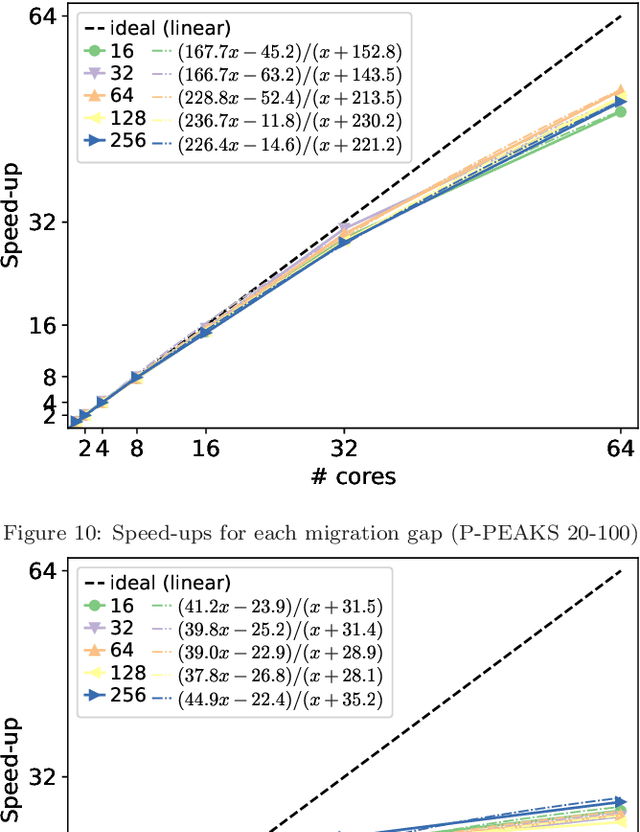
This work proposes a novel approach to evaluate and analyze the behavior of multi-population parallel genetic algorithms (PGAs) when running on a cluster of multi-core processors. In particular, we deeply study their numerical and computational behavior by proposing a mathematical model representing the observed performance curves. In them, we discuss the emerging mathematical descriptions of PGA performance instead of, e.g., individual isolated results subject to visual inspection, for a better understanding of the effects of the number of cores used (scalability), their migration policy (the migration gap, in this paper), and the features of the solved problem (type of encoding and problem size). The conclusions based on the real figures and the numerical models fitting them represent a fresh way of understanding their speed-up, running time, and numerical effort, allowing a comparison based on a few meaningful numeric parameters. This represents a set of conclusions beyond the usual textual lessons found in past works on PGAs. It can be used as an estimation tool for the future performance of the algorithms and a way of finding out their limitations.