 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterated Local Search with Linkage Learning
Oct 02, 2024In pseudo-Boolean optimization, a variable interaction graph represents variables as vertices, and interactions between pairs of variables as edges. In black-box optimization, the variable interaction graph may be at least partially discovered by using empirical linkage learning techniques. These methods never report false variable interactions, but they are computationally expensive. The recently proposed local search with linkage learning discovers the partial variable interaction graph as a side-effect of iterated local search. However, information about the strength of the interactions is not learned by the algorithm. We propose local search with linkage learning 2, which builds a weighted variable interaction graph that stores information about the strength of the interaction between variables. The weighted variable interaction graph can provide new insights about the optimization problem and behavior of optimizers. Experiments with NK landscapes, knapsack problem, and feature selection show that local search with linkage learning 2 is able to efficiently build weighted variable interaction graphs. In particular, experiments with feature selection show that the weighted variable interaction graphs can be used for visualizing the feature interactions in machine learning. Additionally, new transformation operators that exploit the interactions between variables can be designed. We illustrate this ability by proposing a new perturbation operator for iterated local search.
Generalizing and Unifying Gray-box Combinatorial Optimization Operators
Jul 09, 2024Gray-box optimization leverages the information available about the mathematical structure of an optimization problem to design efficient search operators. Efficient hill climbers and crossover operators have been proposed in the domain of pseudo-Boolean optimization and also in some permutation problems. However, there is no general rule on how to design these efficient operators in different representation domains. This paper proposes a general framework that encompasses all known gray-box operators for combinatorial optimization problems. The framework is general enough to shed light on the design of new efficient operators for new problems and representation domains. We also unify the proofs of efficiency for gray-box hill climbers and crossovers and show that the mathematical property explaining the speed-up of gray-box crossover operators, also explains the efficient identification of improving moves in gray-box hill climbers. We illustrate the power of the new framework by proposing an efficient hill climber and crossover for two related permutation problems: the Linear Ordering Problem and the Single Machine Total Weighted Tardiness Problem.
NK Hybrid Genetic Algorithm for Clustering
Feb 06, 2024


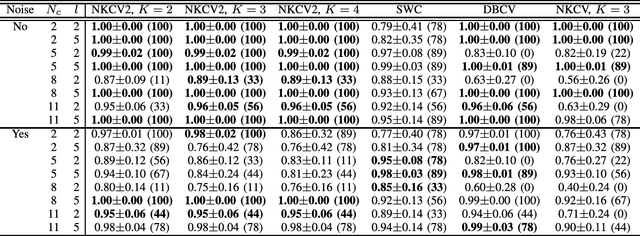
The NK hybrid genetic algorithm for clustering is proposed in this paper. In order to evaluate the solutions, the hybrid algorithm uses the NK clustering validation criterion 2 (NKCV2). NKCV2 uses information about the disposition of $N$ small groups of objects. Each group is composed of $K+1$ objects of the dataset. Experimental results show that density-based regions can be identified by using NKCV2 with fixed small $K$. In NKCV2, the relationship between decision variables is known, which in turn allows us to apply gray box optimization. Mutation operators, a partition crossover, and a local search strategy are proposed, all using information about the relationship between decision variables. In partition crossover, the evaluation function is decomposed into $q$ independent components; partition crossover then deterministically returns the best among $2^q$ possible offspring with computational complexity $O(N)$. The NK hybrid genetic algorithm allows the detection of clusters with arbitrary shapes and the automatic estimation of the number of clusters. In the experiments, the NK hybrid genetic algorithm produced very good results when compared to another genetic algorithm approach and to state-of-art clustering algorithms.
Dynastic Potential Crossover Operator
Feb 06, 2024An optimal recombination operator for two parent solutions provides the best solution among those that take the value for each variable from one of the parents (gene transmission property). If the solutions are bit strings, the offspring of an optimal recombination operator is optimal in the smallest hyperplane containing the two parent solutions. Exploring this hyperplane is computationally costly, in general, requiring exponential time in the worst case. However, when the variable interaction graph of the objective function is sparse, exploration can be done in polynomial time. In this paper, we present a recombination operator, called Dynastic Potential Crossover (DPX), that runs in polynomial time and behaves like an optimal recombination operator for low-epistasis combinatorial problems. We compare this operator, both theoretically and experimentally, with traditional crossover operators, like uniform crossover and network crossover, and with two recently defined efficient recombination operators: partition crossover and articulation points partition crossover. The empirical comparison uses NKQ Landscapes and MAX-SAT instances. DPX outperforms the other crossover operators in terms of quality of the offspring and provides better results included in a trajectory and a population-based metaheuristic, but it requires more time and memory to compute the offspring.
Feature learning in feature-sample networks using multi-objective optimization
Oct 25, 2017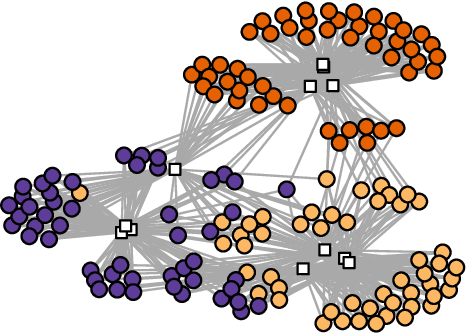
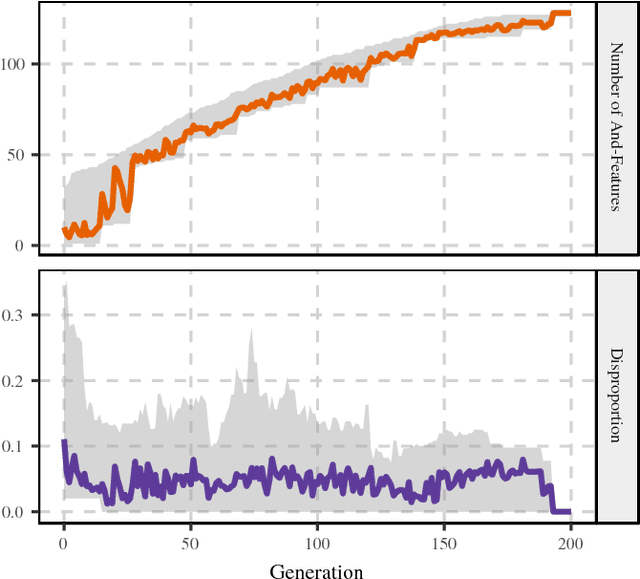

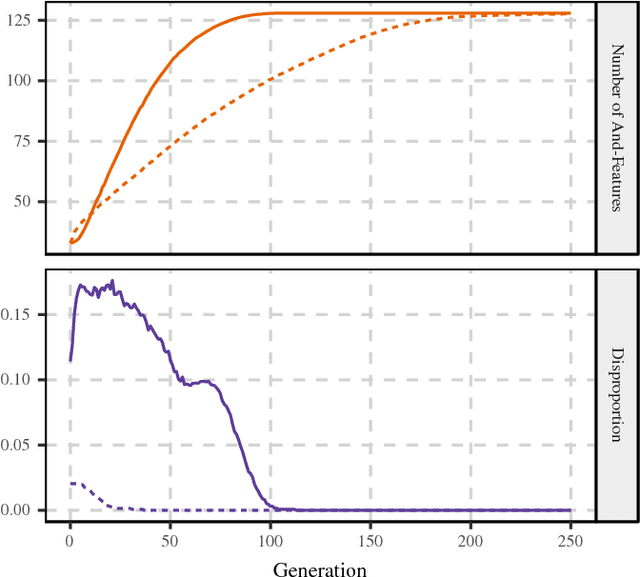
Data and knowledge representation are fundamental concepts in machine learning. The quality of the representation impacts the performance of the learning model directly. Feature learning transforms or enhances raw data to structures that are effectively exploited by those models. In recent years, several works have been using complex networks for data representation and analysis. However, no feature learning method has been proposed for such category of techniques. Here, we present an unsupervised feature learning mechanism that works on datasets with binary features. First, the dataset is mapped into a feature--sample network. Then, a multi-objective optimization process selects a set of new vertices to produce an enhanced version of the network. The new features depend on a nonlinear function of a combination of preexisting features. Effectively, the process projects the input data into a higher-dimensional space. To solve the optimization problem, we design two metaheuristics based on the lexicographic genetic algorithm and the improved strength Pareto evolutionary algorithm (SPEA2). We show that the enhanced network contains more information and can be exploited to improve the performance of machine learning methods. The advantages and disadvantages of each optimization strategy are discussed.
Optimal Neuron Selection: NK Echo State Networks for Reinforcement Learning
May 07, 2015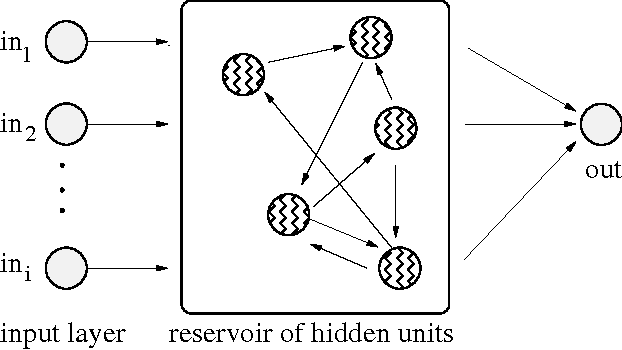
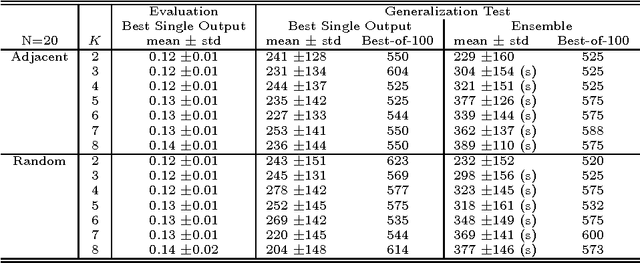
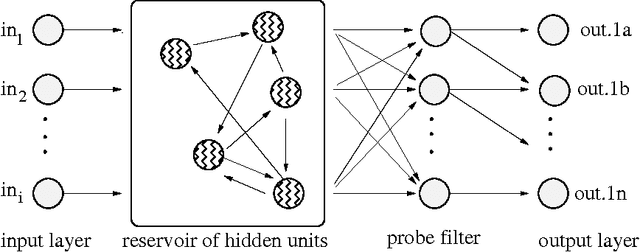
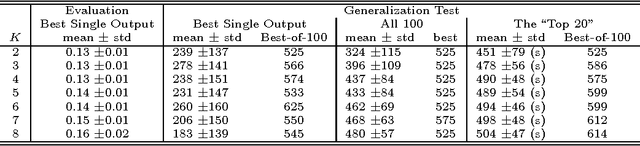
This paper introduces the NK Echo State Network. The problem of learning in the NK Echo State Network is reduced to the problem of optimizing a special form of a Spin Glass Problem known as an NK Landscape. No weight adjustment is used; all learning is accomplished by spinning up (turning on) or spinning down (turning off) neurons in order to find a combination of neurons that work together to achieve the desired computation. For special types of NK Landscapes, an exact global solution can be obtained in polynomial time using dynamic programming. The NK Echo State Network is applied to a reinforcement learning problem requiring a recurrent network: balancing two poles on a cart given no velocity information. Empirical results shows that the NK Echo State Network learns very rapidly and yields very good generalization.