 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Free Reinforcement Learning via Cross-Model Entropy
May 27, 2026Post-training large language models with reinforcement learning is bottlenecked by the reward signal. Existing approaches require either ground-truth verifiable rewards, restricting training to domains with automatic correctness checks (e.g., mathematics, code execution), or human preference labels, which are expensive to collect and prone to reward hacking. Recent label-free methods replace ground-truth verifiers with self-referential signals like majority voting or token entropy over a model's own outputs, but risk reinforcing a model's own errors. In this work we propose Cross-Model Entropy (CME), the mean log-likelihood of a generator's response under a separate verifier model, as a label-free reward signal for RL post-training. CME is continuous, training-free, and grounded in the principle that responses a verifier finds unsurprising are likely correct or high quality. Because the verifier is independent of the generator, the signal cannot be gamed through self-consistency. We integrate CME into GRPO with no other changes to the training loop, extending label-free RL to open-ended instruction following -- a regime where self-referential signals are inapplicable or poorly suited. On open-ended instruction following (UltraFeedback prompts, evaluated on AlpacaEval 2.0), CME rewards beat the untrained base in head-to-head LLM-as-Judge comparisons across four model families (Qwen, Llama, Gemma, OLMo) and three training regimes (pretrained, SFT, and instruction-tuned), with tie-adjusted win rates ranging from 52.5% to 71.4%. Code will be released upon publication.
Cross-Model Disagreement as a Label-Free Correctness Signal
Mar 26, 2026Detecting when a language model is wrong without ground truth labels is a fundamental challenge for safe deployment. Existing approaches rely on a model's own uncertainty -- such as token entropy or confidence scores -- but these signals fail critically on the most dangerous failure mode: confident errors, where a model is wrong but certain. In this work we introduce cross-model disagreement as a correctness indicator -- a simple, training-free signal that can be dropped into existing production systems, routing pipelines, and deployment monitoring infrastructure without modification. Given a model's generated answer, cross-model disagreement computes how surprised or uncertain a second verifier model is when reading that answer via a single forward pass. No generation from the verifying model is required, and no correctness labels are needed. We instantiate this principle as Cross-Model Perplexity (CMP), which measures the verifying model's surprise at the generating model's answer tokens, and Cross-Model Entropy (CME), which measures the verifying model's uncertainty at those positions. Both CMP and CME outperform within-model uncertainty baselines across benchmarks spanning reasoning, retrieval, and mathematical problem solving (MMLU, TriviaQA, and GSM8K). On MMLU, CMP achieves a mean AUROC of 0.75 against a within-model entropy baseline of 0.59. These results establish cross-model disagreement as a practical, training-free approach to label-free correctness estimation, with direct applications in deployment monitoring, model routing, selective prediction, data filtering, and scalable oversight of production language model systems.
Secure Linear Alignment of Large Language Models
Mar 19, 2026Language models increasingly appear to learn similar representations, despite differences in training objectives, architectures, and data modalities. This emerging compatibility between independently trained models introduces new opportunities for cross-model alignment to downstream objectives. Moreover, it unlocks new potential application domains, such as settings where security, privacy, or competitive constraints prohibit direct data or model sharing. In this work, we propose a privacy-preserving framework that exploits representational convergence to enable cross-silo inference between independent language models. The framework learns an affine transformation over a shared public dataset and applies homomorphic encryption to protect client queries during inference. By encrypting only the linear alignment and classification operations, the method achieves sub-second inference latency while maintaining strong security guarantees. We support this framework with an empirical investigation into representational convergence, in which we learn linear transformations between the final hidden states of independent models. We evaluate these cross-model mappings on embedding classification and out-of-distribution detection, observing minimal performance degradation across model pairs. Additionally, we show for the first time that linear alignment sometimes enables text generation across independently trained models.
Tiled Bit Networks: Sub-Bit Neural Network Compression Through Reuse of Learnable Binary Vectors
Jul 16, 2024Binary Neural Networks (BNNs) enable efficient deep learning by saving on storage and computational costs. However, as the size of neural networks continues to grow, meeting computational requirements remains a challenge. In this work, we propose a new form of quantization to tile neural network layers with sequences of bits to achieve sub-bit compression of binary-weighted neural networks. The method learns binary vectors (i.e. tiles) to populate each layer of a model via aggregation and reshaping operations. During inference, the method reuses a single tile per layer to represent the full tensor. We employ the approach to both fully-connected and convolutional layers, which make up the breadth of space in most neural architectures. Empirically, the approach achieves near fullprecision performance on a diverse range of architectures (CNNs, Transformers, MLPs) and tasks (classification, segmentation, and time series forecasting) with up to an 8x reduction in size compared to binary-weighted models. We provide two implementations for Tiled Bit Networks: 1) we deploy the model to a microcontroller to assess its feasibility in resource-constrained environments, and 2) a GPU-compatible inference kernel to facilitate the reuse of a single tile per layer in memory.
Cross-Silo Federated Learning Across Divergent Domains with Iterative Parameter Alignment
Nov 14, 2023Learning from the collective knowledge of data dispersed across private sources can provide neural networks with enhanced generalization capabilities. Federated learning, a method for collaboratively training a machine learning model across remote clients, achieves this by combining client models via the orchestration of a central server. However, current approaches face two critical limitations: i) they struggle to converge when client domains are sufficiently different, and ii) current aggregation techniques produce an identical global model for each client. In this work, we address these issues by reformulating the typical federated learning setup: rather than learning a single global model, we learn N models each optimized for a common objective. To achieve this, we apply a weighted distance minimization to model parameters shared in a peer-to-peer topology. The resulting framework, Iterative Parameter Alignment, applies naturally to the cross-silo setting, and has the following properties: (i) a unique solution for each participant, with the option to globally converge each model in the federation, and (ii) an optional early-stopping mechanism to elicit fairness among peers in collaborative learning settings. These characteristics jointly provide a flexible new framework for iteratively learning from peer models trained on disparate datasets. We find that the technique achieves competitive results on a variety of data partitions compared to state-of-the-art approaches. Further, we show that the method is robust to divergent domains (i.e. disjoint classes across peers) where existing approaches struggle.
Sparse Binary Transformers for Multivariate Time Series Modeling
Aug 09, 2023Compressed Neural Networks have the potential to enable deep learning across new applications and smaller computational environments. However, understanding the range of learning tasks in which such models can succeed is not well studied. In this work, we apply sparse and binary-weighted Transformers to multivariate time series problems, showing that the lightweight models achieve accuracy comparable to that of dense floating-point Transformers of the same structure. Our model achieves favorable results across three time series learning tasks: classification, anomaly detection, and single-step forecasting. Additionally, to reduce the computational complexity of the attention mechanism, we apply two modifications, which show little to no decline in model performance: 1) in the classification task, we apply a fixed mask to the query, key, and value activations, and 2) for forecasting and anomaly detection, which rely on predicting outputs at a single point in time, we propose an attention mask to allow computation only at the current time step. Together, each compression technique and attention modification substantially reduces the number of non-zero operations necessary in the Transformer. We measure the computational savings of our approach over a range of metrics including parameter count, bit size, and floating point operation (FLOPs) count, showing up to a 53x reduction in storage size and up to 10.5x reduction in FLOPs.
Randomly Initialized Subnetworks with Iterative Weight Recycling
Mar 28, 2023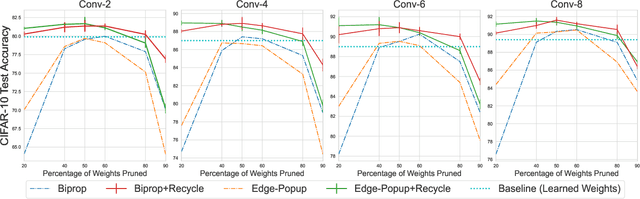
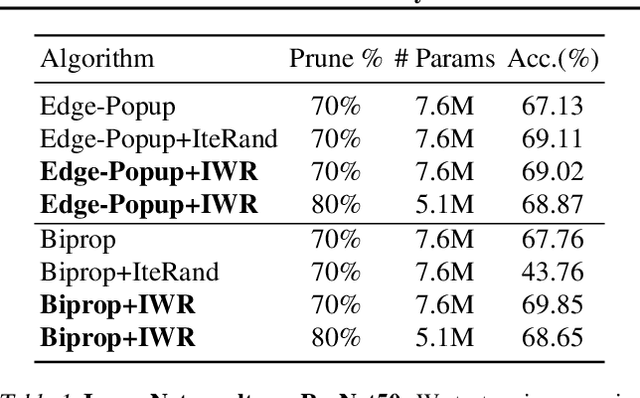
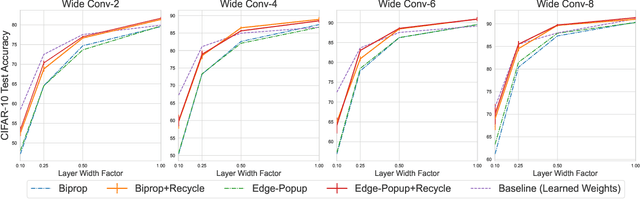
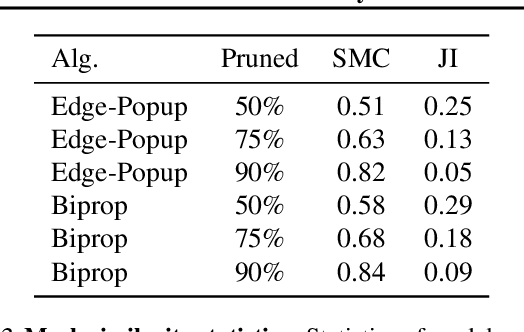
The Multi-Prize Lottery Ticket Hypothesis posits that randomly initialized neural networks contain several subnetworks that achieve comparable accuracy to fully trained models of the same architecture. However, current methods require that the network is sufficiently overparameterized. In this work, we propose a modification to two state-of-the-art algorithms (Edge-Popup and Biprop) that finds high-accuracy subnetworks with no additional storage cost or scaling. The algorithm, Iterative Weight Recycling, identifies subsets of important weights within a randomly initialized network for intra-layer reuse. Empirically we show improvements on smaller network architectures and higher prune rates, finding that model sparsity can be increased through the "recycling" of existing weights. In addition to Iterative Weight Recycling, we complement the Multi-Prize Lottery Ticket Hypothesis with a reciprocal finding: high-accuracy, randomly initialized subnetwork's produce diverse masks, despite being generated with the same hyperparameter's and pruning strategy. We explore the landscapes of these masks, which show high variability.
Utilizing Network Properties to Detect Erroneous Inputs
Feb 28, 2020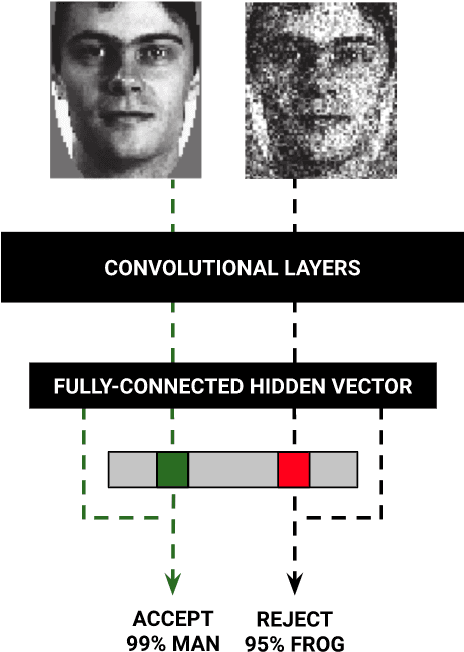
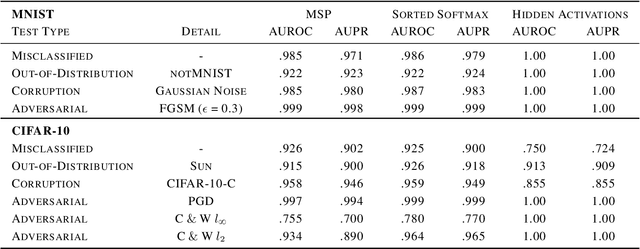
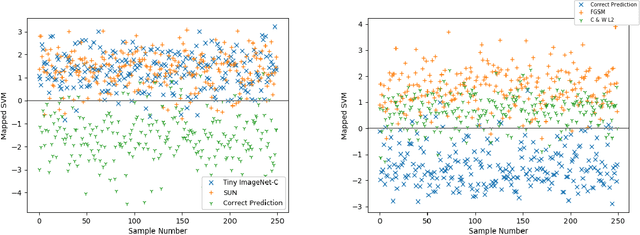
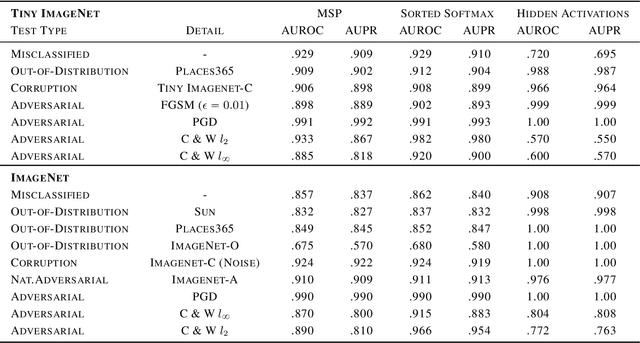
Neural networks are vulnerable to a wide range of erroneous inputs such as adversarial, corrupted, out-of-distribution, and misclassified examples. In this work, we train a linear SVM classifier to detect these four types of erroneous data using hidden and softmax feature vectors of pre-trained neural networks. Our results indicate that these faulty data types generally exhibit linearly separable activation properties from correct examples, giving us the ability to reject bad inputs with no extra training or overhead. We experimentally validate our findings across a diverse range of datasets, domains, pre-trained models, and adversarial attacks.