Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Network Properties to Detect Erroneous Inputs
Paper and Code
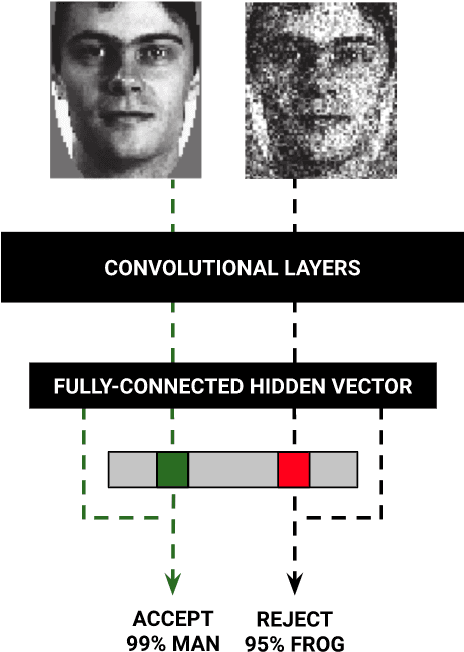
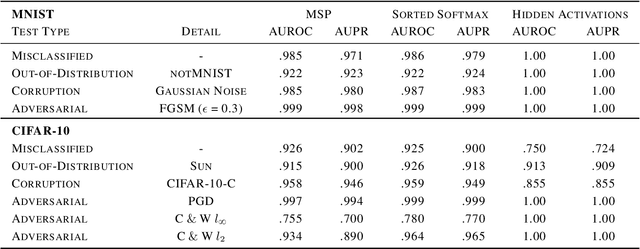
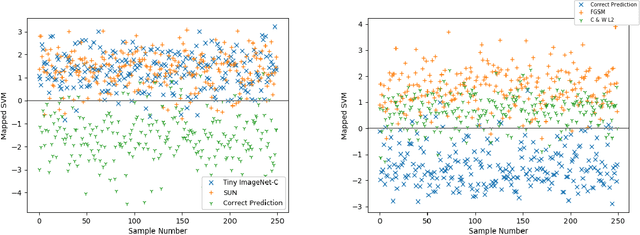
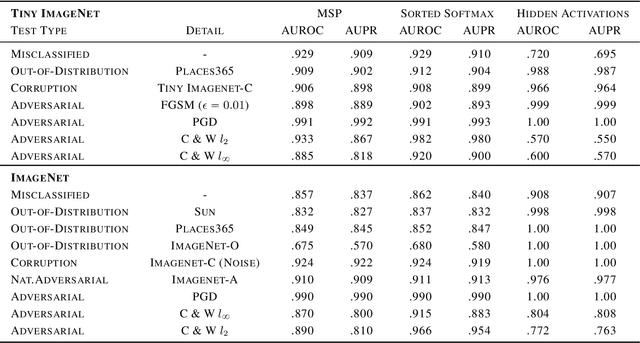
Neural networks are vulnerable to a wide range of erroneous inputs such as adversarial, corrupted, out-of-distribution, and misclassified examples. In this work, we train a linear SVM classifier to detect these four types of erroneous data using hidden and softmax feature vectors of pre-trained neural networks. Our results indicate that these faulty data types generally exhibit linearly separable activation properties from correct examples, giving us the ability to reject bad inputs with no extra training or overhead. We experimentally validate our findings across a diverse range of datasets, domains, pre-trained models, and adversarial attacks.
View paper on