 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Subnetwork Annealing: A Regularization Technique for Fine Tuning Pruned Subnetworks
Jan 16, 2024Pruning methods have recently grown in popularity as an effective way to reduce the size and computational complexity of deep neural networks. Large numbers of parameters can be removed from trained models with little discernible loss in accuracy after a small number of continued training epochs. However, pruning too many parameters at once often causes an initial steep drop in accuracy which can undermine convergence quality. Iterative pruning approaches mitigate this by gradually removing a small number of parameters over multiple epochs. However, this can still lead to subnetworks that overfit local regions of the loss landscape. We introduce a novel and effective approach to tuning subnetworks through a regularization technique we call Stochastic Subnetwork Annealing. Instead of removing parameters in a discrete manner, we instead represent subnetworks with stochastic masks where each parameter has a probabilistic chance of being included or excluded on any given forward pass. We anneal these probabilities over time such that subnetwork structure slowly evolves as mask values become more deterministic, allowing for a smoother and more robust optimization of subnetworks at high levels of sparsity.
Subnetwork Ensembles
Nov 23, 2023Neural network ensembles have been effectively used to improve generalization by combining the predictions of multiple independently trained models. However, the growing scale and complexity of deep neural networks have led to these methods becoming prohibitively expensive and time consuming to implement. Low-cost ensemble methods have become increasingly important as they can alleviate the need to train multiple models from scratch while retaining the generalization benefits that traditional ensemble learning methods afford. This dissertation introduces and formalizes a low-cost framework for constructing Subnetwork Ensembles, where a collection of child networks are formed by sampling, perturbing, and optimizing subnetworks from a trained parent model. We explore several distinct methodologies for generating child networks and we evaluate their efficacy through a variety of ablation studies and established benchmarks. Our findings reveal that this approach can greatly improve training efficiency, parametric utilization, and generalization performance while minimizing computational cost. Subnetwork Ensembles offer a compelling framework for exploring how we can build better systems by leveraging the unrealized potential of deep neural networks.
Interpretable Diversity Analysis: Visualizing Feature Representations In Low-Cost Ensembles
Feb 12, 2023



Diversity is an important consideration in the construction of robust neural network ensembles. A collection of well trained models will generalize better if they are diverse in the patterns they respond to and the predictions they make. Diversity is especially important for low-cost ensemble methods because members often share network structure in order to avoid training several independent models from scratch. Diversity is traditionally analyzed by measuring differences between the outputs of models. However, this gives little insight into how knowledge representations differ between ensemble members. This paper introduces several interpretability methods that can be used to qualitatively analyze diversity. We demonstrate these techniques by comparing the diversity of feature representations between child networks using two low-cost ensemble algorithms, Snapshot Ensembles and Prune and Tune Ensembles. We use the same pre-trained parent network as a starting point for both methods which allows us to explore how feature representations evolve over time. This approach to diversity analysis can lead to valuable insights and new perspectives for how we measure and promote diversity in ensemble methods.
Sparse Mutation Decompositions: Fine Tuning Deep Neural Networks with Subspace Evolution
Feb 12, 2023



Neuroevolution is a promising area of research that combines evolutionary algorithms with neural networks. A popular subclass of neuroevolutionary methods, called evolution strategies, relies on dense noise perturbations to mutate networks, which can be sample inefficient and challenging for large models with millions of parameters. We introduce an approach to alleviating this problem by decomposing dense mutations into low-dimensional subspaces. Restricting mutations in this way can significantly reduce variance as networks can handle stronger perturbations while maintaining performance, which enables a more controlled and targeted evolution of deep networks. This approach is uniquely effective for the task of fine tuning pre-trained models, which is an increasingly valuable area of research as networks continue to scale in size and open source models become more widely available. Furthermore, we show how this work naturally connects to ensemble learning where sparse mutations encourage diversity among children such that their combined predictions can reliably improve performance. We conduct the first large scale exploration of neuroevolutionary fine tuning and ensembling on the notoriously difficult ImageNet dataset, where we see small generalization improvements with only a single evolutionary generation using nearly a dozen different deep neural network architectures.
Quantum Neuron Selection: Finding High Performing Subnetworks With Quantum Algorithms
Feb 12, 2023Gradient descent methods have long been the de facto standard for training deep neural networks. Millions of training samples are fed into models with billions of parameters, which are slowly updated over hundreds of epochs. Recently, it's been shown that large, randomly initialized neural networks contain subnetworks that perform as well as fully trained models. This insight offers a promising avenue for training future neural networks by simply pruning weights from large, random models. However, this problem is combinatorically hard and classical algorithms are not efficient at finding the best subnetwork. In this paper, we explore how quantum algorithms could be formulated and applied to this neuron selection problem. We introduce several methods for local quantum neuron selection that reduce the entanglement complexity that large scale neuron selection would require, making this problem more tractable for current quantum hardware.
Synaptic Stripping: How Pruning Can Bring Dead Neurons Back To Life
Feb 11, 2023Rectified Linear Units (ReLU) are the default choice for activation functions in deep neural networks. While they demonstrate excellent empirical performance, ReLU activations can fall victim to the dead neuron problem. In these cases, the weights feeding into a neuron end up being pushed into a state where the neuron outputs zero for all inputs. Consequently, the gradient is also zero for all inputs, which means that the weights which feed into the neuron cannot update. The neuron is not able to recover from direct back propagation and model capacity is reduced as those parameters can no longer be further optimized. Inspired by a neurological process of the same name, we introduce Synaptic Stripping as a means to combat this dead neuron problem. By automatically removing problematic connections during training, we can regenerate dead neurons and significantly improve model capacity and parametric utilization. Synaptic Stripping is easy to implement and results in sparse networks that are more efficient than the dense networks they are derived from. We conduct several ablation studies to investigate these dynamics as a function of network width and depth and we conduct an exploration of Synaptic Stripping with Vision Transformers on a variety of benchmark datasets.
Prune and Tune Ensembles: Low-Cost Ensemble Learning With Sparse Independent Subnetworks
Mar 25, 2022

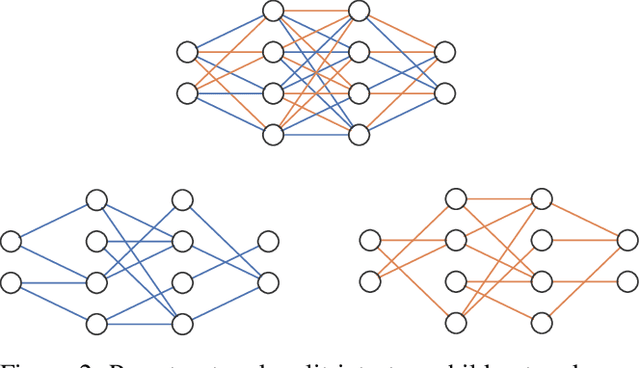

Ensemble Learning is an effective method for improving generalization in machine learning. However, as state-of-the-art neural networks grow larger, the computational cost associated with training several independent networks becomes expensive. We introduce a fast, low-cost method for creating diverse ensembles of neural networks without needing to train multiple models from scratch. We do this by first training a single parent network. We then create child networks by cloning the parent and dramatically pruning the parameters of each child to create an ensemble of members with unique and diverse topologies. We then briefly train each child network for a small number of epochs, which now converge significantly faster when compared to training from scratch. We explore various ways to maximize diversity in the child networks, including the use of anti-random pruning and one-cycle tuning. This diversity enables "Prune and Tune" ensembles to achieve results that are competitive with traditional ensembles at a fraction of the training cost. We benchmark our approach against state of the art low-cost ensemble methods and display marked improvement in both accuracy and uncertainty estimation on CIFAR-10 and CIFAR-100.