 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking that Matters: Rethinking Benchmarking for Practical Impact
Nov 15, 2025Benchmarking has driven scientific progress in Evolutionary Computation, yet current practices fall short of real-world needs. Widely used synthetic suites such as BBOB and CEC isolate algorithmic phenomena but poorly reflect the structure, constraints, and information limitations of continuous and mixed-integer optimization problems in practice. This disconnect leads to the misuse of benchmarking suites for competitions, automated algorithm selection, and industrial decision-making, despite these suites being designed for different purposes. We identify key gaps in current benchmarking practices and tooling, including limited availability of real-world-inspired problems, missing high-level features, and challenges in multi-objective and noisy settings. We propose a vision centered on curated real-world-inspired benchmarks, practitioner-accessible feature spaces and community-maintained performance databases. Real progress requires coordinated effort: A living benchmarking ecosystem that evolves with real-world insights and supports both scientific understanding and industrial use.
Tuning for Trustworthiness -- Balancing Performance and Explanation Consistency in Neural Network Optimization
May 12, 2025



Despite the growing interest in Explainable Artificial Intelligence (XAI), explainability is rarely considered during hyperparameter tuning or neural architecture optimization, where the focus remains primarily on minimizing predictive loss. In this work, we introduce the novel concept of XAI consistency, defined as the agreement among different feature attribution methods, and propose new metrics to quantify it. For the first time, we integrate XAI consistency directly into the hyperparameter tuning objective, creating a multi-objective optimization framework that balances predictive performance with explanation robustness. Implemented within the Sequential Parameter Optimization Toolbox (SPOT), our approach uses both weighted aggregation and desirability-based strategies to guide model selection. Through our proposed framework and supporting tools, we explore the impact of incorporating XAI consistency into the optimization process. This enables us to characterize distinct regions in the architecture configuration space: one region with poor performance and comparatively low interpretability, another with strong predictive performance but weak interpretability due to low \gls{xai} consistency, and a trade-off region that balances both objectives by offering high interpretability alongside competitive performance. Beyond introducing this novel approach, our research provides a foundation for future investigations into whether models from the trade-off zone-balancing performance loss and XAI consistency-exhibit greater robustness by avoiding overfitting to training performance, thereby leading to more reliable predictions on out-of-distribution data.
Multi-Objective Optimization and Hyperparameter Tuning With Desirability Functions
Mar 30, 2025



The goal of this article is to provide an introduction to the desirability function approach to multi-objective optimization (direct and surrogate model-based), and multi-objective hyperparameter tuning. This work is based on the paper by Kuhn (2016). It presents a `Python` implementation of Kuhn's `R` package `desirability`. The `Python` package `spotdesirability` is available as part of the `sequential parameter optimization` framework. After a brief introduction to the desirability function approach is presented, three examples are given that demonstrate how to use the desirability functions for classical optimization, surrogate-model based optimization, and hyperparameter tuning.
Bed-Attached Vibration Sensor System: A Machine Learning Approach for Fall Detection in Nursing Homes
Dec 06, 2024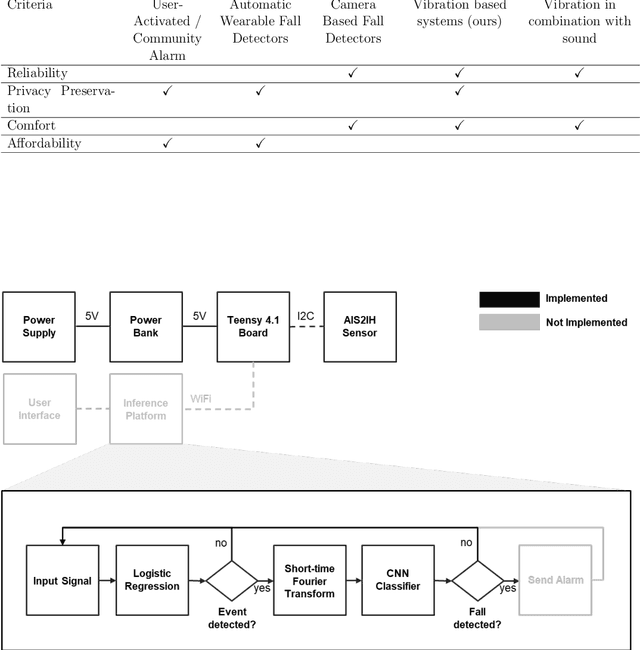
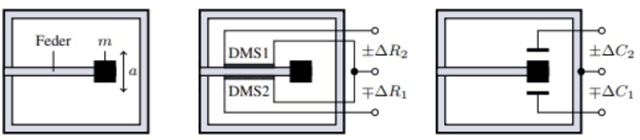
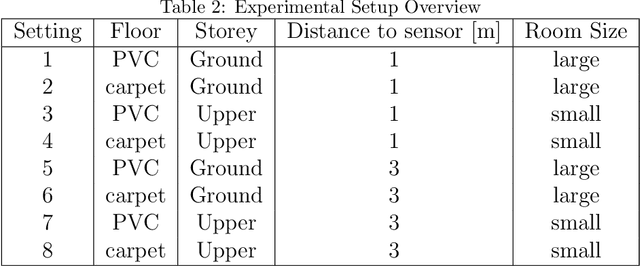
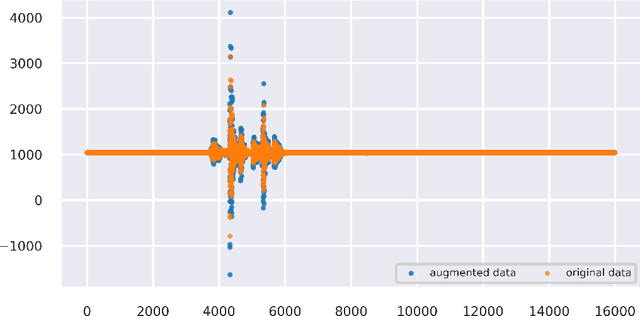
The increasing shortage of nursing staff and the acute risk of falls in nursing homes pose significant challenges for the healthcare system. This study presents the development of an automated fall detection system integrated into care beds, aimed at enhancing patient safety without compromising privacy through wearables or video monitoring. Mechanical vibrations transmitted through the bed frame are processed using a short-time Fourier transform, enabling robust classification of distinct human fall patterns with a convolutional neural network. Challenges pertaining to the quantity and diversity of the data are addressed, proposing the generation of additional data with a specific emphasis on enhancing variation. While the model shows promising results in distinguishing fall events from noise using lab data, further testing in real-world environments is recommended for validation and improvement. Despite limited available data, the proposed system shows the potential for an accurate and rapid response to falls, mitigating health implications, and addressing the needs of an aging population. This case study was performed as part of the ZIM Project. Further research on sensors enhanced by artificial intelligence will be continued in the ShapeFuture Project.
Enhancing Feature Selection and Interpretability in AI Regression Tasks Through Feature Attribution
Sep 25, 2024Research in Explainable Artificial Intelligence (XAI) is increasing, aiming to make deep learning models more transparent. Most XAI methods focus on justifying the decisions made by Artificial Intelligence (AI) systems in security-relevant applications. However, relatively little attention has been given to using these methods to improve the performance and robustness of deep learning algorithms. Additionally, much of the existing XAI work primarily addresses classification problems. In this study, we investigate the potential of feature attribution methods to filter out uninformative features in input data for regression problems, thereby improving the accuracy and stability of predictions. We introduce a feature selection pipeline that combines Integrated Gradients with k-means clustering to select an optimal set of variables from the initial data space. To validate the effectiveness of this approach, we apply it to a real-world industrial problem - blade vibration analysis in the development process of turbo machinery.
A Novel Ranking Scheme for the Performance Analysis of Stochastic Optimization Algorithms using the Principles of Severity
May 31, 2024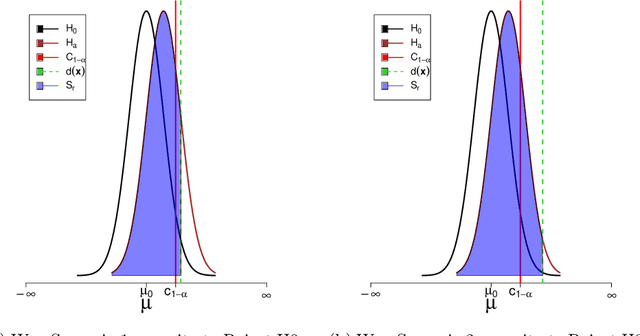

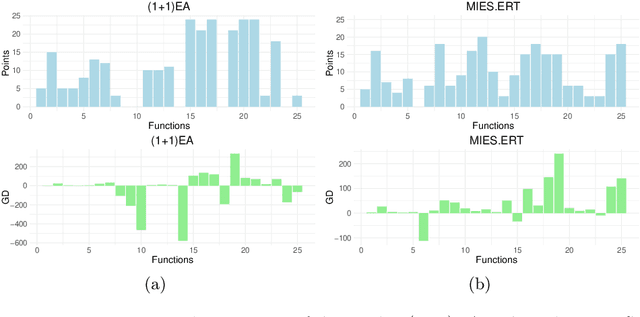

Stochastic optimization algorithms have been successfully applied in several domains to find optimal solutions. Because of the ever-growing complexity of the integrated systems, novel stochastic algorithms are being proposed, which makes the task of the performance analysis of the algorithms extremely important. In this paper, we provide a novel ranking scheme to rank the algorithms over multiple single-objective optimization problems. The results of the algorithms are compared using a robust bootstrapping-based hypothesis testing procedure that is based on the principles of severity. Analogous to the football league scoring scheme, we propose pairwise comparison of algorithms as in league competition. Each algorithm accumulates points and a performance metric of how good or bad it performed against other algorithms analogous to goal differences metric in football league scoring system. The goal differences performance metric can not only be used as a tie-breaker but also be used to obtain a quantitative performance of each algorithm. The key novelty of the proposed ranking scheme is that it takes into account the performance of each algorithm considering the magnitude of the achieved performance improvement along with its practical relevance and does not have any distributional assumptions. The proposed ranking scheme is compared to classical hypothesis testing and the analysis of the results shows that the results are comparable and our proposed ranking showcases many additional benefits.
Simplifying Hyperparameter Tuning in Online Machine Learning -- The spotRiverGUI
Feb 18, 2024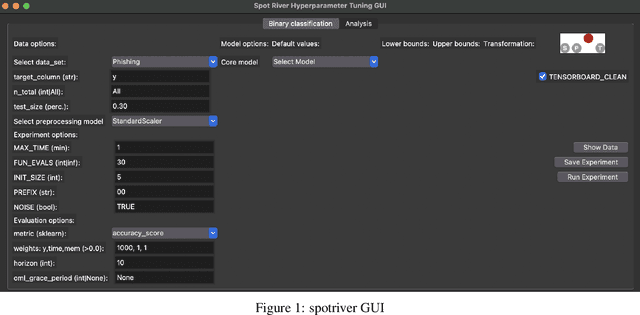

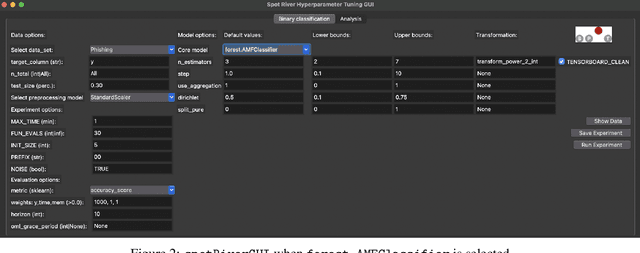
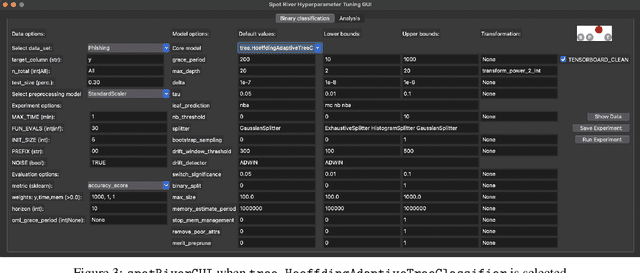
Batch Machine Learning (BML) reaches its limits when dealing with very large amounts of streaming data. This is especially true for available memory, handling drift in data streams, and processing new, unknown data. Online Machine Learning (OML) is an alternative to BML that overcomes the limitations of BML. OML is able to process data in a sequential manner, which is especially useful for data streams. The `river` package is a Python OML-library, which provides a variety of online learning algorithms for classification, regression, clustering, anomaly detection, and more. The `spotRiver` package provides a framework for hyperparameter tuning of OML models. The `spotRiverGUI` is a graphical user interface for the `spotRiver` package. The `spotRiverGUI` releases the user from the burden of manually searching for the optimal hyperparameter setting. After the data is provided, users can compare different OML algorithms from the powerful `river` package in a convenient way and tune the selected algorithms very efficiently.
Hyperparameter Tuning Cookbook: A guide for scikit-learn, PyTorch, river, and spotPython
Jul 17, 2023This document provides a comprehensive guide to hyperparameter tuning using spotPython for scikit-learn, PyTorch, and river. The first part introduces spotPython's surrogate model-based optimization process, while the second part focuses on hyperparameter tuning. Several case studies are presented, including hyperparameter tuning for sklearn models such as Support Vector Classification, Random Forests, Gradient Boosting (XGB), and K-nearest neighbors (KNN), as well as a Hoeffding Adaptive Tree Regressor from river. The integration of spotPython into the PyTorch and PyTorch Lightning training workflow is also discussed. With a hands-on approach and step-by-step explanations, this cookbook serves as a practical starting point for anyone interested in hyperparameter tuning with Python. Highlights include the interplay between Tensorboard, PyTorch Lightning, spotPython, and river. This publication is under development, with updates available on the corresponding webpage.
PyTorch Hyperparameter Tuning -- A Tutorial for spotPython
May 19, 2023



The goal of hyperparameter tuning (or hyperparameter optimization) is to optimize the hyperparameters to improve the performance of the machine or deep learning model. spotPython (``Sequential Parameter Optimization Toolbox in Python'') is the Python version of the well-known hyperparameter tuner SPOT, which has been developed in the R programming environment for statistical analysis for over a decade. PyTorch is an optimized tensor library for deep learning using GPUs and CPUs. This document shows how to integrate the spotPython hyperparameter tuner into the PyTorch training workflow. As an example, the results of the CIFAR10 image classifier are used. In addition to an introduction to spotPython, this tutorial also includes a brief comparison with Ray Tune, a Python library for running experiments and tuning hyperparameters. This comparison is based on the PyTorch hyperparameter tuning tutorial. The advantages and disadvantages of both approaches are discussed. We show that spotPython achieves similar or even better results while being more flexible and transparent than Ray Tune.
Underwater Acoustic Networks for Security Risk Assessment in Public Drinking Water Reservoirs
Jul 29, 2021


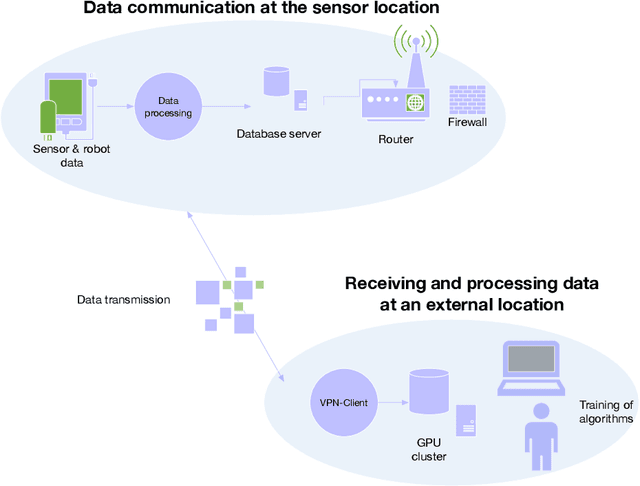
We have built a novel system for the surveillance of drinking water reservoirs using underwater sensor networks. We implement an innovative AI-based approach to detect, classify and localize underwater events. In this paper, we describe the technology and cognitive AI architecture of the system based on one of the sensor networks, the hydrophone network. We discuss the challenges of installing and using the hydrophone network in a water reservoir where traffic, visitors, and variable water conditions create a complex, varying environment. Our AI solution uses an autoencoder for unsupervised learning of latent encodings for classification and anomaly detection, and time delay estimates for sound localization. Finally, we present the results of experiments carried out in a laboratory pool and the water reservoir and discuss the system's potential.