 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderwater Acoustic Networks for Security Risk Assessment in Public Drinking Water Reservoirs
Jul 29, 2021


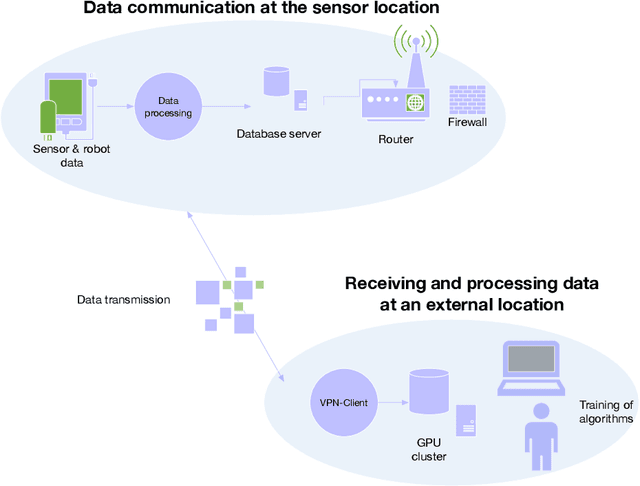
We have built a novel system for the surveillance of drinking water reservoirs using underwater sensor networks. We implement an innovative AI-based approach to detect, classify and localize underwater events. In this paper, we describe the technology and cognitive AI architecture of the system based on one of the sensor networks, the hydrophone network. We discuss the challenges of installing and using the hydrophone network in a water reservoir where traffic, visitors, and variable water conditions create a complex, varying environment. Our AI solution uses an autoencoder for unsupervised learning of latent encodings for classification and anomaly detection, and time delay estimates for sound localization. Finally, we present the results of experiments carried out in a laboratory pool and the water reservoir and discuss the system's potential.
Behavior-based Neuroevolutionary Training in Reinforcement Learning
May 17, 2021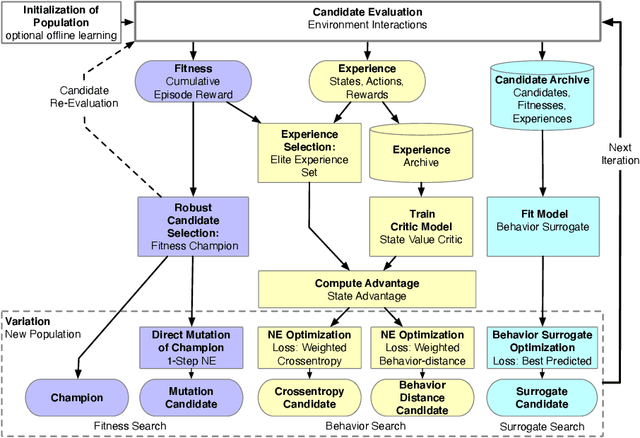
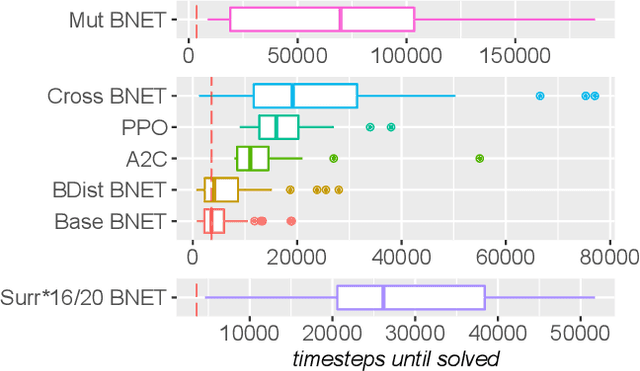
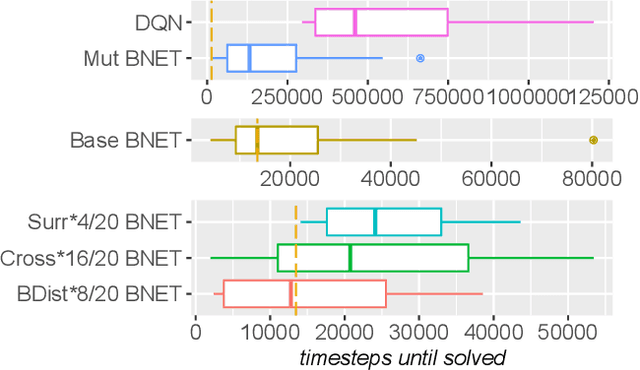
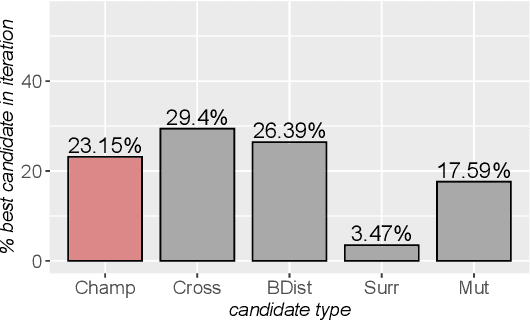
In addition to their undisputed success in solving classical optimization problems, neuroevolutionary and population-based algorithms have become an alternative to standard reinforcement learning methods. However, evolutionary methods often lack the sample efficiency of standard value-based methods that leverage gathered state and value experience. If reinforcement learning for real-world problems with significant resource cost is considered, sample efficiency is essential. The enhancement of evolutionary algorithms with experience exploiting methods is thus desired and promises valuable insights. This work presents a hybrid algorithm that combines topology-changing neuroevolutionary optimization with value-based reinforcement learning. We illustrate how the behavior of policies can be used to create distance and loss functions, which benefit from stored experiences and calculated state values. They allow us to model behavior and perform a directed search in the behavior space by gradient-free evolutionary algorithms and surrogate-based optimization. For this purpose, we consolidate different methods to generate and optimize agent policies, creating a diverse population. We exemplify the performance of our algorithm on standard benchmarks and a purpose-built real-world problem. Our results indicate that combining methods can enhance the sample efficiency and learning speed for evolutionary approaches.
CAAI -- A Cognitive Architecture to Introduce Artificial Intelligence in Cyber-Physical Production Systems
Feb 26, 2020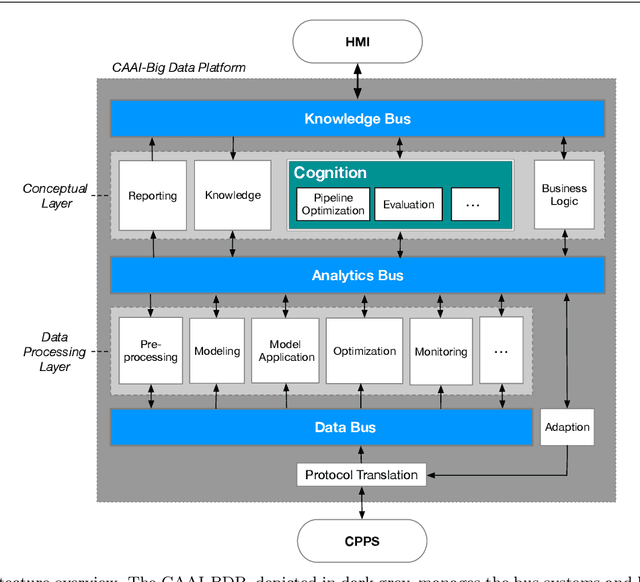
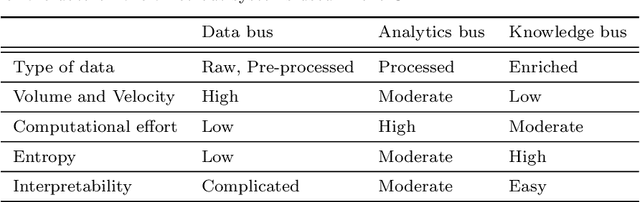
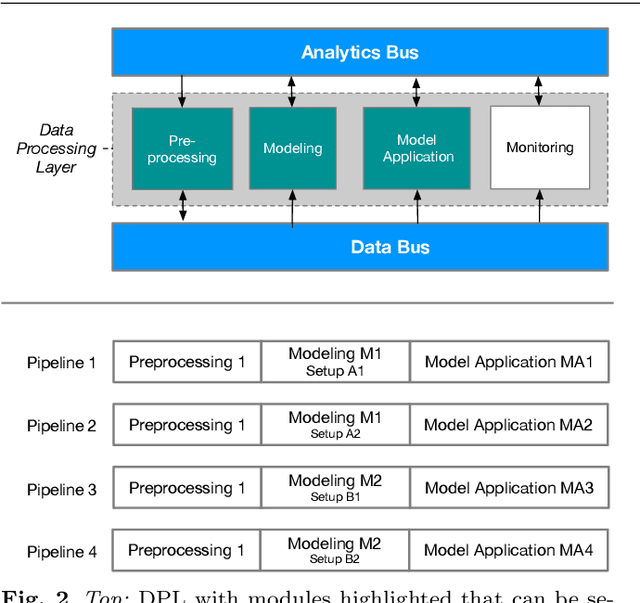
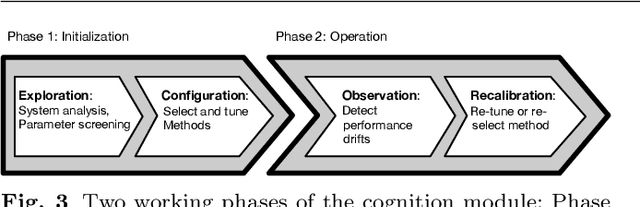
This paper introduces CAAI, a novel cognitive architecture for artificial intelligence in cyber-physical production systems. The goal of the architecture is to reduce the implementation effort for the usage of artificial intelligence algorithms. The core of the CAAI is a cognitive module that processes declarative goals of the user, selects suitable models and algorithms, and creates a configuration for the execution of a processing pipeline on a big data platform. Constant observation and evaluation against performance criteria assess the performance of pipelines for many and varying use cases. Based on these evaluations, the pipelines are automatically adapted if necessary. The modular design with well-defined interfaces enables the reusability and extensibility of pipeline components. A big data platform implements this modular design supported by technologies such as Docker, Kubernetes, and Kafka for virtualization and orchestration of the individual components and their communication. The implementation of the architecture is evaluated using a real-world use case.
Surrogate Models for Enhancing the Efficiency of Neuroevolution in Reinforcement Learning
Jul 22, 2019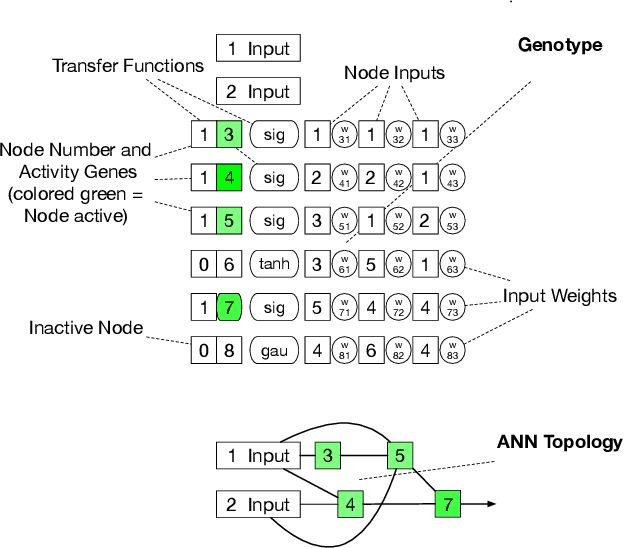
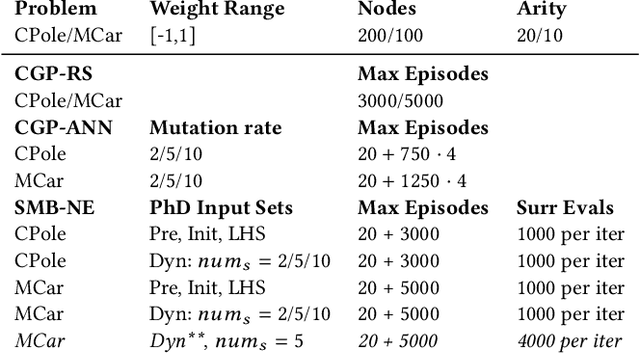
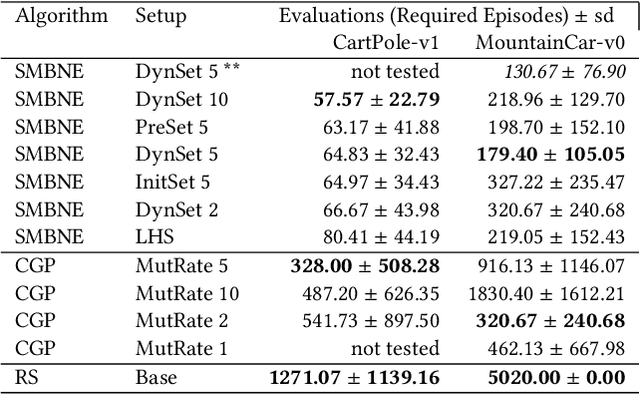
In the last years, reinforcement learning received a lot of attention. One method to solve reinforcement learning tasks is Neuroevolution, where neural networks are optimized by evolutionary algorithms. A disadvantage of Neuroevolution is that it can require numerous function evaluations, while not fully utilizing the available information from each fitness evaluation. This is especially problematic when fitness evaluations become expensive. To reduce the cost of fitness evaluations, surrogate models can be employed to partially replace the fitness function. The difficulty of surrogate modeling for Neuroevolution is the complex search space and how to compare different networks. To that end, recent studies showed that a kernel based approach, particular with phenotypic distance measures, works well. These kernels compare different networks via their behavior (phenotype) rather than their topology or encoding (genotype). In this work, we discuss the use of surrogate model-based Neuroevolution (SMB-NE) using a phenotypic distance for reinforcement learning. In detail, we investigate a) the potential of SMB-NE with respect to evaluation efficiency and b) how to select adequate input sets for the phenotypic distance measure in a reinforcement learning problem. The results indicate that we are able to considerably increase the evaluation efficiency using dynamic input sets.
* This is the authors version of the work. It is posted here for your personal use. Not for redistribution. The definitive Version of Record was published in Genetic and Evolutionary Computation Conference (GECCO 2019)
Prediction of neural network performance by phenotypic modeling
Jul 16, 2019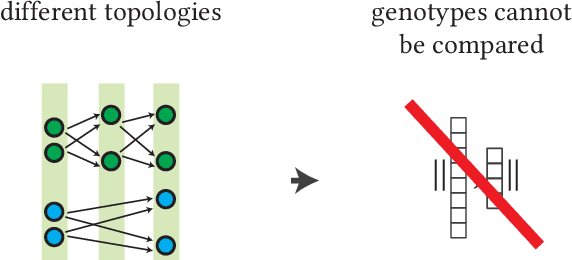
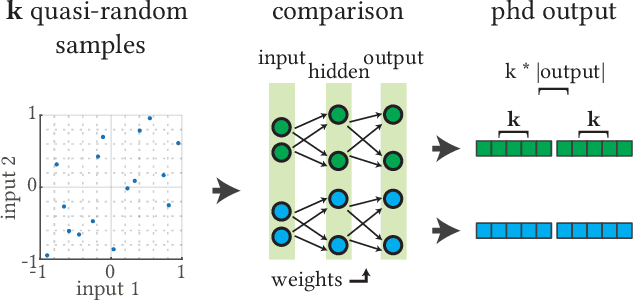
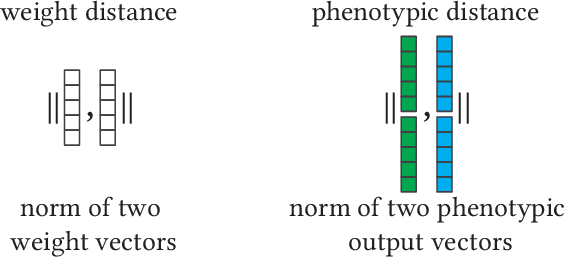
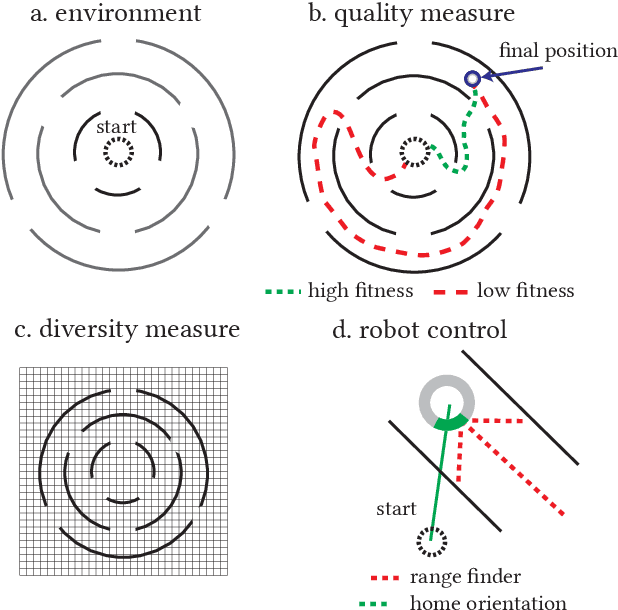
Surrogate models are used to reduce the burden of expensive-to-evaluate objective functions in optimization. By creating models which map genomes to objective values, these models can estimate the performance of unknown inputs, and so be used in place of expensive objective functions. Evolutionary techniques such as genetic programming or neuroevolution commonly alter the structure of the genome itself. A lack of consistency in the genotype is a fatal blow to data-driven modeling techniques: interpolation between points is impossible without a common input space. However, while the dimensionality of genotypes may differ across individuals, in many domains, such as controllers or classifiers, the dimensionality of the input and output remains constant. In this work we leverage this insight to embed differing neural networks into the same input space. To judge the difference between the behavior of two neural networks, we give them both the same input sequence, and examine the difference in output. This difference, the phenotypic distance, can then be used to situate these networks into a common input space, allowing us to produce surrogate models which can predict the performance of neural networks regardless of topology. In a robotic navigation task, we show that models trained using this phenotypic embedding perform as well or better as those trained on the weight values of a fixed topology neural network. We establish such phenotypic surrogate models as a promising and flexible approach which enables surrogate modeling even for representations that undergo structural changes.
Improving NeuroEvolution Efficiency by Surrogate Model-based Optimization with Phenotypic Distance Kernels
Feb 09, 2019



In NeuroEvolution, the topologies of artificial neural networks are optimized with evolutionary algorithms to solve tasks in data regression, data classification, or reinforcement learning. One downside of NeuroEvolution is the large amount of necessary fitness evaluations, which might render it inefficient for tasks with expensive evaluations, such as real-time learning. For these expensive optimization tasks, surrogate model-based optimization is frequently applied as it features a good evaluation efficiency. While a combination of both procedures appears as a valuable solution, the definition of adequate distance measures for the surrogate modeling process is difficult. In this study, we will extend cartesian genetic programming of artificial neural networks by the use of surrogate model-based optimization. We propose different distance measures and test our algorithm on a replicable benchmark task. The results indicate that we can significantly increase the evaluation efficiency and that a phenotypic distance, which is based on the behavior of the associated neural networks, is most promising.
A new Taxonomy of Continuous Global Optimization Algorithms
Aug 27, 2018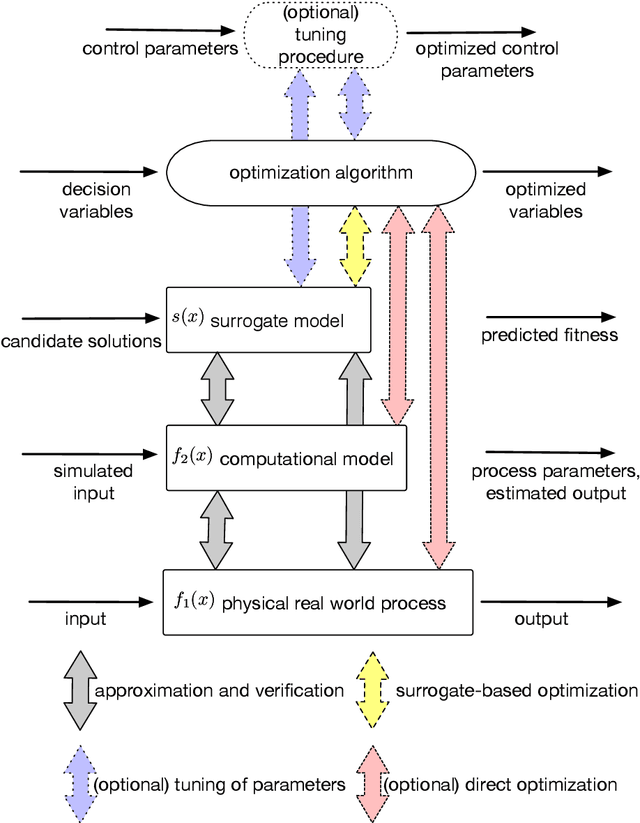
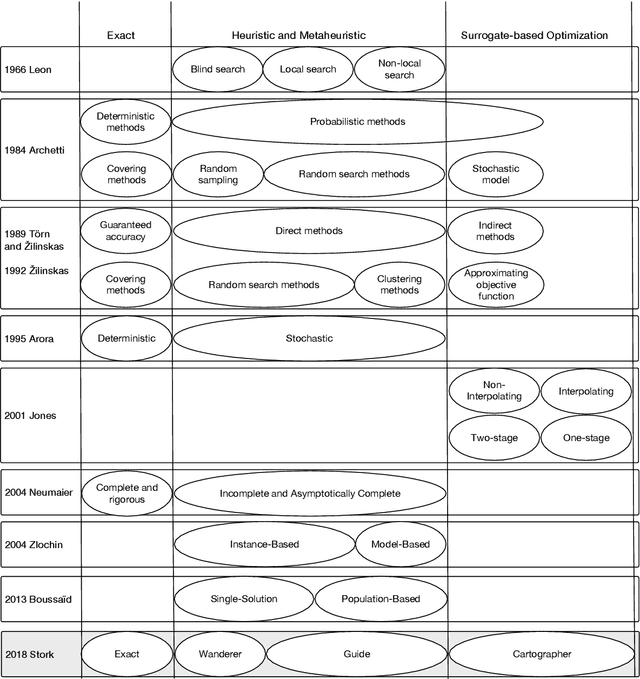
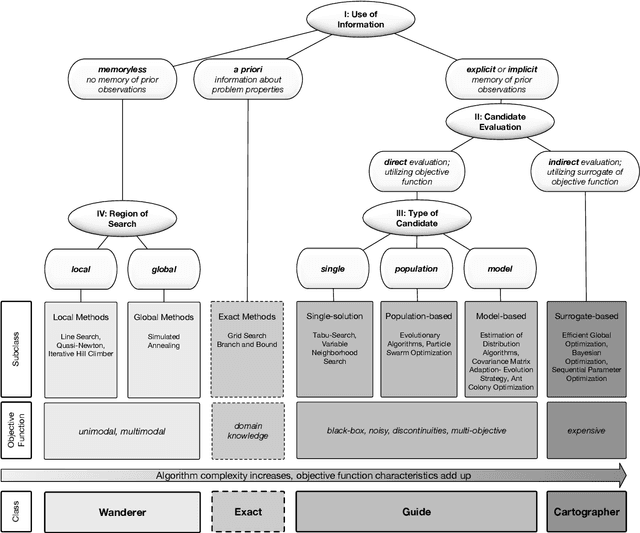
Surrogate-based optimization and nature-inspired metaheuristics have become the state-of-the-art in solving real-world optimization problems. Still, it is difficult for beginners and even experts to get an overview that explains their advantages in comparison to the large number of available methods in the scope of continuous optimization. Available taxonomies lack the integration of surrogate-based approaches and thus their embedding in the larger context of this broad field. This article presents a taxonomy of the field, which further matches the idea of nature-inspired algorithms, as it is based on the human behavior in path finding. Intuitive analogies make it easy to conceive the most basic principles of the search algorithms, even for beginners and non-experts in this area of research. However, this scheme does not oversimplify the high complexity of the different algorithms, as the class identifier only defines a descriptive meta-level of the algorithm search strategies. The taxonomy was established by exploring and matching algorithm schemes, extracting similarities and differences, and creating a set of classification indicators to distinguish between five distinct classes. In practice, this taxonomy allows recommendations for the applicability of the corresponding algorithms and helps developers trying to create or improve their own algorithms.
Distance-based Kernels for Surrogate Model-based Neuroevolution
Jul 20, 2018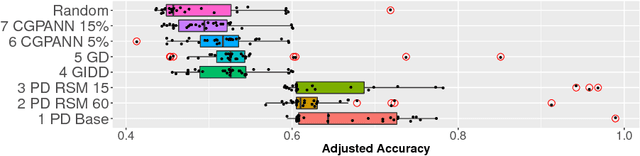
The topology optimization of artificial neural networks can be particularly difficult if the fitness evaluations require expensive experiments or simulations. For that reason, the optimization methods may need to be supported by surrogate models. We propose different distances for a suitable surrogate model, and compare them in a simple numerical test scenario.
Linear Combination of Distance Measures for Surrogate Models in Genetic Programming
Jul 03, 2018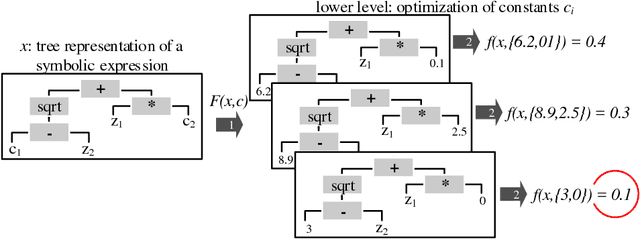
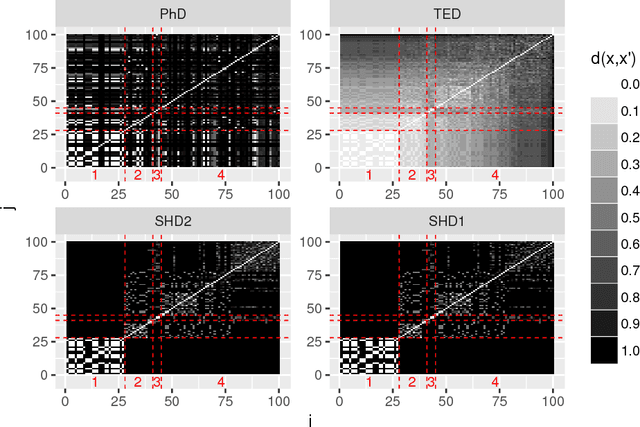
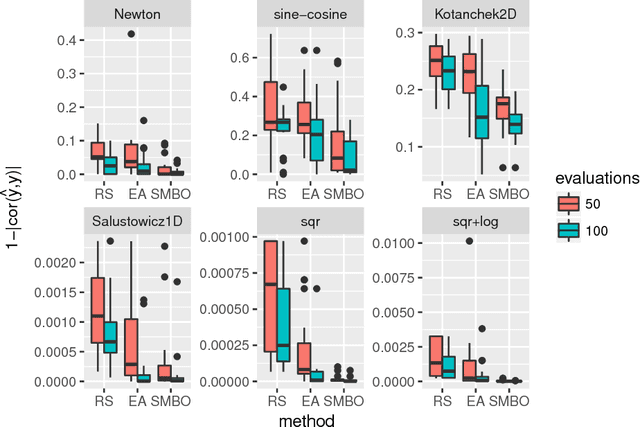
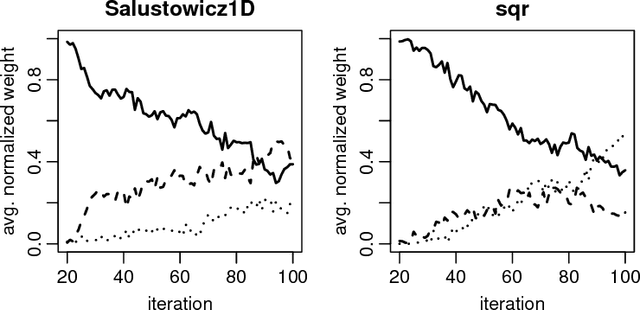
Surrogate models are a well established approach to reduce the number of expensive function evaluations in continuous optimization. In the context of genetic programming, surrogate modeling still poses a challenge, due to the complex genotype-phenotype relationships. We investigate how different genotypic and phenotypic distance measures can be used to learn Kriging models as surrogates. We compare the measures and suggest to use their linear combination in a kernel. We test the resulting model in an optimization framework, using symbolic regression problem instances as a benchmark. Our experiments show that the model provides valuable information. Firstly, the model enables an improved optimization performance compared to a model-free algorithm. Furthermore, the model provides information on the contribution of different distance measures. The data indicates that a phenotypic distance measure is important during the early stages of an optimization run when less data is available. In contrast, genotypic measures, such as the tree edit distance, contribute more during the later stages.