 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconventional Hexacopters via Evolution and Learning: Performance Gains and New Insights
May 20, 2025Evolution and learning have historically been interrelated topics, and their interplay is attracting increased interest lately. The emerging new factor in this trend is morphological evolution, the evolution of physical forms within embodied AI systems such as robots. In this study, we investigate a system of hexacopter-type drones with evolvable morphologies and learnable controllers and make contributions to two fields. For aerial robotics, we demonstrate that the combination of evolution and learning can deliver non-conventional drones that significantly outperform the traditional hexacopter on several tasks that are more complex than previously considered in the literature. For the field of Evolutionary Computing, we introduce novel metrics and perform new analyses into the interaction of morphological evolution and learning, uncovering hitherto unidentified effects. Our analysis tools are domain-agnostic, making a methodological contribution towards building solid foundations for embodied AI systems that integrate evolution and learning.
Robot Policy Transfer with Online Demonstrations: An Active Reinforcement Learning Approach
Mar 17, 2025



Transfer Learning (TL) is a powerful tool that enables robots to transfer learned policies across different environments, tasks, or embodiments. To further facilitate this process, efforts have been made to combine it with Learning from Demonstrations (LfD) for more flexible and efficient policy transfer. However, these approaches are almost exclusively limited to offline demonstrations collected before policy transfer starts, which may suffer from the intrinsic issue of covariance shift brought by LfD and harm the performance of policy transfer. Meanwhile, extensive work in the learning-from-scratch setting has shown that online demonstrations can effectively alleviate covariance shift and lead to better policy performance with improved sample efficiency. This work combines these insights to introduce online demonstrations into a policy transfer setting. We present Policy Transfer with Online Demonstrations, an active LfD algorithm for policy transfer that can optimize the timing and content of queries for online episodic expert demonstrations under a limited demonstration budget. We evaluate our method in eight robotic scenarios, involving policy transfer across diverse environment characteristics, task objectives, and robotic embodiments, with the aim to transfer a trained policy from a source task to a related but different target task. The results show that our method significantly outperforms all baselines in terms of average success rate and sample efficiency, compared to two canonical LfD methods with offline demonstrations and one active LfD method with online demonstrations. Additionally, we conduct preliminary sim-to-real tests of the transferred policy on three transfer scenarios in the real-world environment, demonstrating the policy effectiveness on a real robot manipulator.
Active Robot Curriculum Learning from Online Human Demonstrations
Mar 04, 2025Learning from Demonstrations (LfD) allows robots to learn skills from human users, but its effectiveness can suffer due to sub-optimal teaching, especially from untrained demonstrators. Active LfD aims to improve this by letting robots actively request demonstrations to enhance learning. However, this may lead to frequent context switches between various task situations, increasing the human cognitive load and introducing errors to demonstrations. Moreover, few prior studies in active LfD have examined how these active query strategies may impact human teaching in aspects beyond user experience, which can be crucial for developing algorithms that benefit both robot learning and human teaching. To tackle these challenges, we propose an active LfD method that optimizes the query sequence of online human demonstrations via Curriculum Learning (CL), where demonstrators are guided to provide demonstrations in situations of gradually increasing difficulty. We evaluate our method across four simulated robotic tasks with sparse rewards and conduct a user study (N=26) to investigate the influence of active LfD methods on human teaching regarding teaching performance, post-guidance teaching adaptivity, and teaching transferability. Our results show that our method significantly improves learning performance compared to three other LfD baselines in terms of the final success rate of the converged policy and sample efficiency. Additionally, results from our user study indicate that our method significantly reduces the time required from human demonstrators and decreases failed demonstration attempts. It also enhances post-guidance human teaching in both seen and unseen scenarios compared to another active LfD baseline, indicating enhanced teaching performance, greater post-guidance teaching adaptivity, and better teaching transferability achieved by our method.
"Give Me an Example Like This": Episodic Active Reinforcement Learning from Demonstrations
Jun 06, 2024



Reinforcement Learning (RL) has achieved great success in sequential decision-making problems, but often at the cost of a large number of agent-environment interactions. To improve sample efficiency, methods like Reinforcement Learning from Expert Demonstrations (RLED) introduce external expert demonstrations to facilitate agent exploration during the learning process. In practice, these demonstrations, which are often collected from human users, are costly and hence often constrained to a limited amount. How to select the best set of human demonstrations that is most beneficial for learning therefore becomes a major concern. This paper presents EARLY (Episodic Active Learning from demonstration querY), an algorithm that enables a learning agent to generate optimized queries of expert demonstrations in a trajectory-based feature space. Based on a trajectory-level estimate of uncertainty in the agent's current policy, EARLY determines the optimized timing and content for feature-based queries. By querying episodic demonstrations as opposed to isolated state-action pairs, EARLY improves the human teaching experience and achieves better learning performance. We validate the effectiveness of our method in three simulated navigation tasks of increasing difficulty. The results show that our method is able to achieve expert-level performance for all three tasks with convergence over 30\% faster than other baseline methods when demonstrations are generated by simulated oracle policies. The results of a follow-up pilot user study (N=18) further validate that our method can still maintain a significantly better convergence in the case of human expert demonstrators while achieving a better user experience in perceived task load and consuming significantly less human time.
Emergence of specialized Collective Behaviors in Evolving Heterogeneous Swarms
Feb 07, 2024



Natural groups of animals, such as swarms of social insects, exhibit astonishing degrees of task specialization, useful to address complex tasks and to survive. This is supported by phenotypic plasticity: individuals sharing the same genotype that is expressed differently for different classes of individuals, each specializing in one task. In this work, we evolve a swarm of simulated robots with phenotypic plasticity to study the emergence of specialized collective behavior during an emergent perception task. Phenotypic plasticity is realized in the form of heterogeneity of behavior by dividing the genotype into two components, with one different neural network controller associated to each component. The whole genotype, expressing the behavior of the whole group through the two components, is subject to evolution with a single fitness function. We analyse the obtained behaviors and use the insights provided by these results to design an online regulatory mechanism. Our experiments show three main findings: 1) The sub-groups evolve distinct emergent behaviors. 2) The effectiveness of the whole swarm depends on the interaction between the two sub-groups, leading to a more robust performance than with singular sub-group behavior. 3) The online regulatory mechanism enhances overall performance and scalability.
Environment induced emergence of collective behaviour in evolving swarms with limited sensing
Apr 11, 2022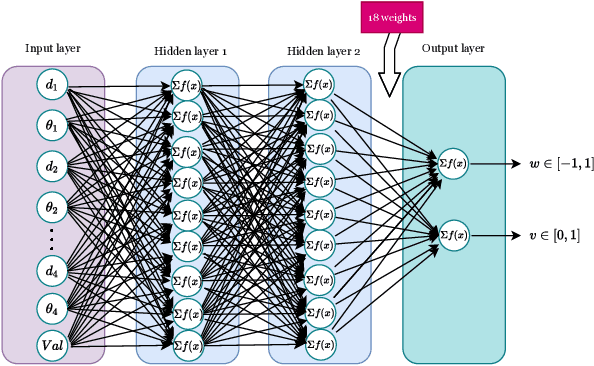
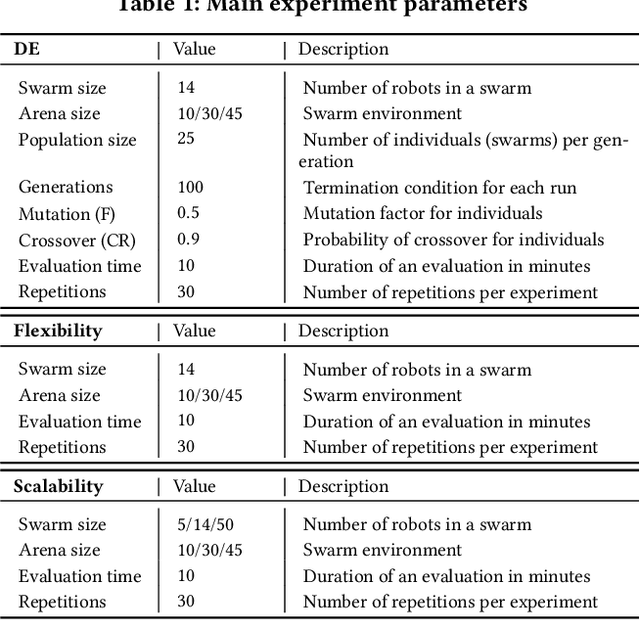
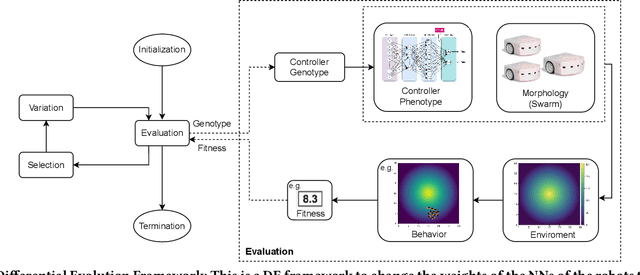
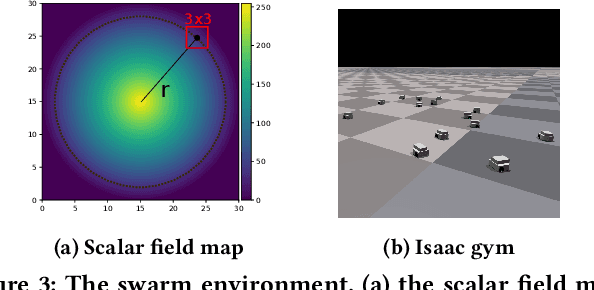
Designing controllers for robot swarms is challenging, because human developers have typically no good understanding of the link between the details of a controller that governs individual robots and the swarm behavior that is an indirect result of the interactions between swarm members and the environment. In this paper we investigate whether an evolutionary approach can mitigate this problem. We consider a very challenging task where robots with limited sensing and communication abilities must follow the gradient of an environmental feature and use Differential Evolution to evolve a neural network controller for simulated robots. We conduct a systematic study to measure the flexibility and scalability of the method by varying the size of the arena and number of robots in the swarm. The experiments confirm the feasibility of our approach, the evolved robot controllers induced swarm behavior that solved the task. We found that solutions evolved under the harshest conditions (where the environmental clues were the weakest) were the most flexible and that there is a sweet spot regarding the swarm size. Furthermore, we observed collective motion of the swarm, showcasing truly emergent behavior that was not represented in- and selected for during evolution.
Comparing lifetime learning methods for morphologically evolving robots
Mar 08, 2022
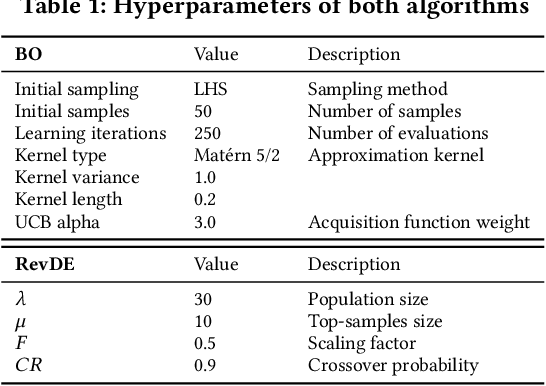
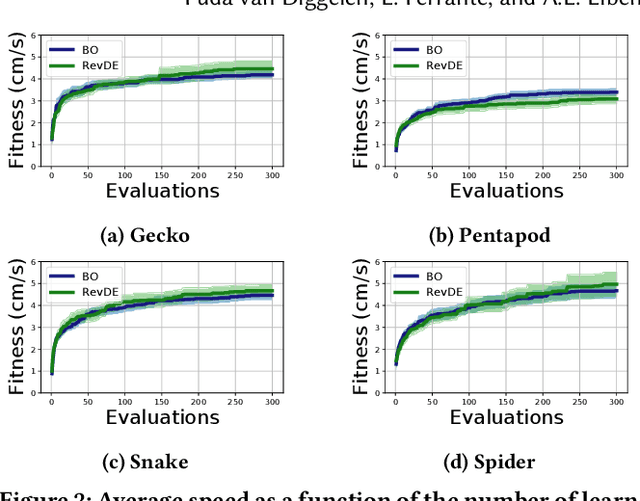
Evolving morphologies and controllers of robots simultaneously leads to a problem: Even if the parents have well-matching bodies and brains, the stochastic recombination can break this match and cause a body-brain mismatch in their offspring. We argue that this can be mitigated by having newborn robots perform a learning process that optimizes their inherited brain quickly after birth. We compare three different algorithms for doing this. To this end, we consider three algorithmic properties, efficiency, efficacy, and the sensitivity to differences in the morphologies of the robots that run the learning process.
Heritability in Morphological Robot Evolution
Oct 21, 2021
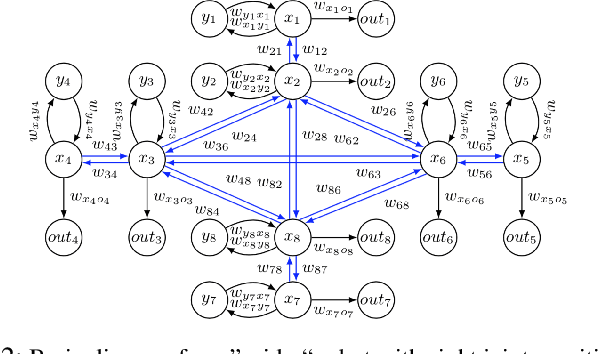
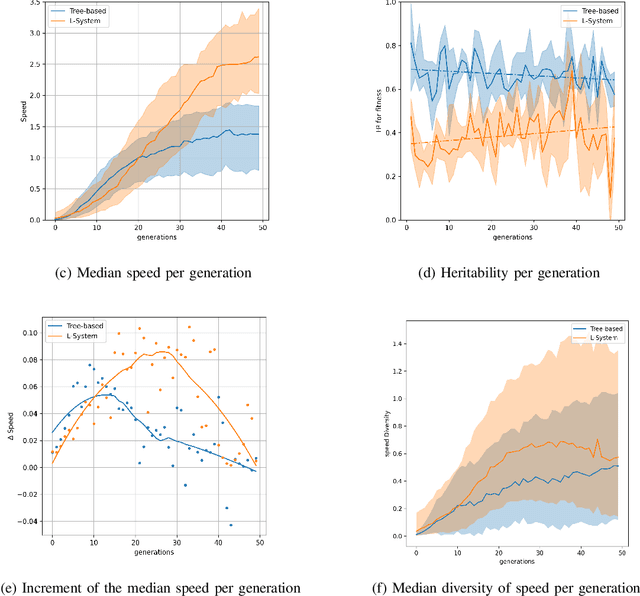
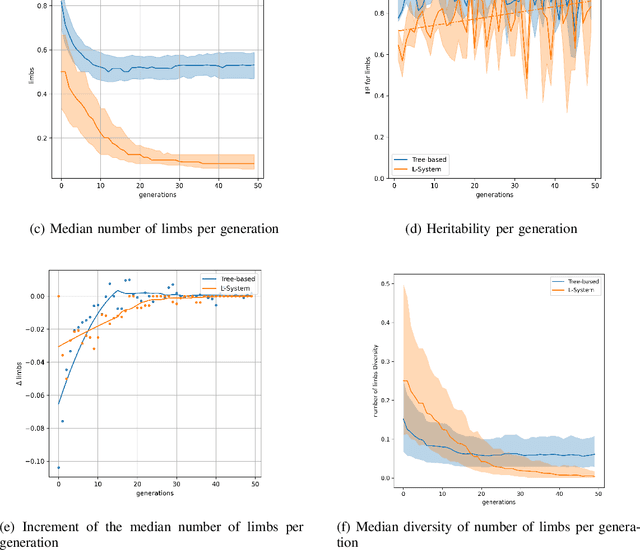
In the field of evolutionary robotics, choosing the correct encoding is very complicated, especially when robots evolve both behaviours and morphologies at the same time. With the objective of improving our understanding of the mapping process from encodings to functional robots, we introduce the biological notion of heritability, which captures the amount of phenotypic variation caused by genotypic variation. In our analysis we measure the heritability on the first generation of robots evolved from two different encodings, a direct encoding and an indirect encoding. In addition we investigate the interplay between heritability and phenotypic diversity through the course of an entire evolutionary process. In particular, we investigate how direct and indirect genotypes can exhibit preferences for exploration or exploitation throughout the course of evolution. We observe how an exploration or exploitation tradeoff can be more easily understood by examining patterns in heritability and phenotypic diversity. In conclusion, we show how heritability can be a useful tool to better understand the relationship between genotypes and phenotypes, especially helpful when designing more complicated systems where complex individuals and environments can adapt and influence each other.
Impact of Energy Efficiency on the Morphology and Behaviour of Evolved Robots
Jul 12, 2021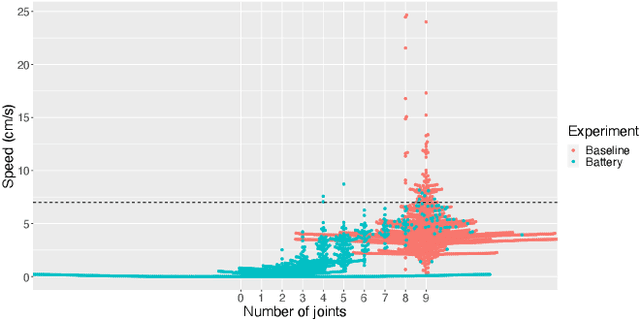

Most evolutionary robotics studies focus on evolving some targeted behavior without taking the energy usage into account. This limits the practical value of such systems because energy efficiency is an important property for real-world autonomous robots. In this paper, we mitigate this problem by extending our simulator with a battery model and taking energy consumption into account during fitness evaluations. Using this system we investigate how energy awareness affects the evolution of robots. Since our system is to evolve morphologies as well as controllers, the main research question is twofold: (i) what is the impact on the morphologies of the evolved robots, and (ii) what is the impact on the behavior of the evolved robots if energy consumption is included in the fitness evaluation? The results show that including the energy consumption in the fitness in a multi-objective fashion (by NSGA-II) reduces the average size of robot bodies while at the same time reducing their speed. However, robots generated without size reduction can achieve speeds comparable to robots from the baseline set.
Behavior-based Neuroevolutionary Training in Reinforcement Learning
May 17, 2021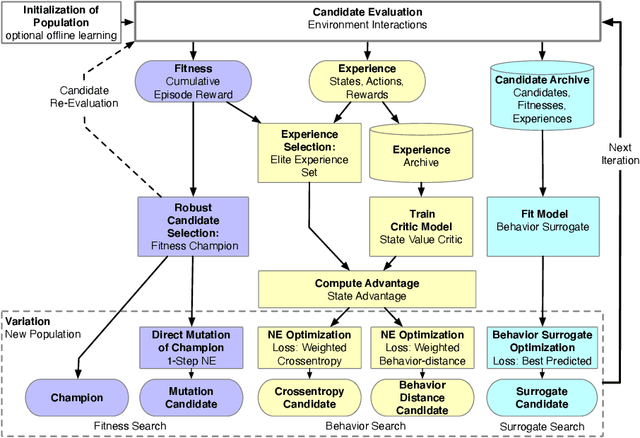
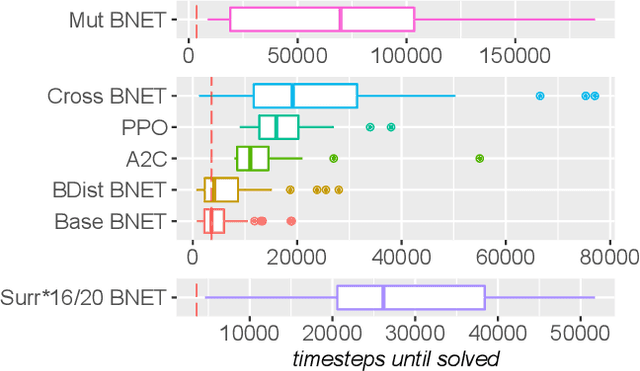
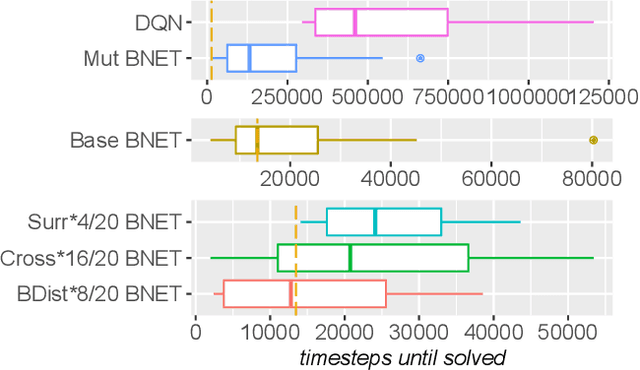
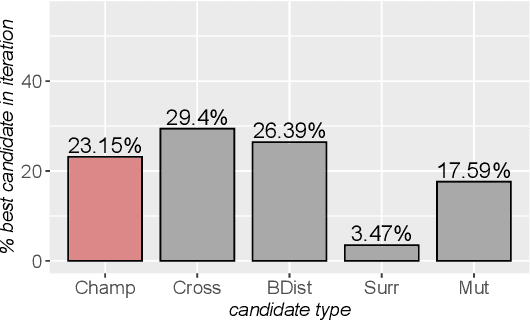
In addition to their undisputed success in solving classical optimization problems, neuroevolutionary and population-based algorithms have become an alternative to standard reinforcement learning methods. However, evolutionary methods often lack the sample efficiency of standard value-based methods that leverage gathered state and value experience. If reinforcement learning for real-world problems with significant resource cost is considered, sample efficiency is essential. The enhancement of evolutionary algorithms with experience exploiting methods is thus desired and promises valuable insights. This work presents a hybrid algorithm that combines topology-changing neuroevolutionary optimization with value-based reinforcement learning. We illustrate how the behavior of policies can be used to create distance and loss functions, which benefit from stored experiences and calculated state values. They allow us to model behavior and perform a directed search in the behavior space by gradient-free evolutionary algorithms and surrogate-based optimization. For this purpose, we consolidate different methods to generate and optimize agent policies, creating a diverse population. We exemplify the performance of our algorithm on standard benchmarks and a purpose-built real-world problem. Our results indicate that combining methods can enhance the sample efficiency and learning speed for evolutionary approaches.