 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic Is Not Enough: A Comparative Study of VR and SpaceMouse in Static and Dynamic Teleoperation Tasks
Jan 19, 2026Imitation learning relies on high-quality demonstrations, and teleoperation is a primary way to collect them, making teleoperation interface choice crucial for the data. Prior work mainly focused on static tasks, i.e., discrete, segmented motions, yet demonstrations also include dynamic tasks requiring reactive control. As dynamic tasks impose fundamentally different interface demands, insights from static-task evaluations cannot generalize. To address this gap, we conduct a within-subjects study comparing a VR controller and a SpaceMouse across two static and two dynamic tasks ($N=25$). We assess success rate, task duration, cumulative success, alongside NASA-TLX, SUS, and open-ended feedback. Results show statistically significant advantages for VR: higher success rates, particularly on dynamic tasks, shorter successful execution times across tasks, and earlier successes across attempts, with significantly lower workload and higher usability. As existing VR teleoperation systems are rarely open-source or suited for dynamic tasks, we release our VR interface to fill this gap.
Can you see how I learn? Human observers' inferences about Reinforcement Learning agents' learning processes
Jun 16, 2025
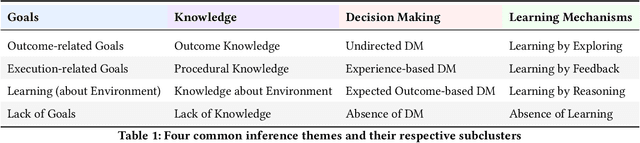
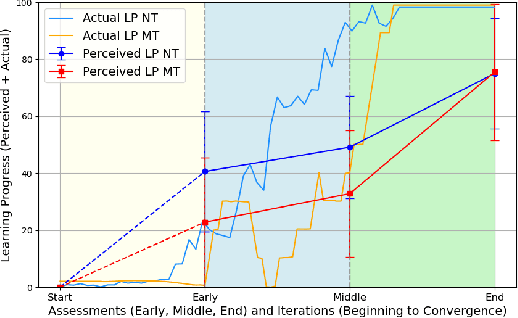

Reinforcement Learning (RL) agents often exhibit learning behaviors that are not intuitively interpretable by human observers, which can result in suboptimal feedback in collaborative teaching settings. Yet, how humans perceive and interpret RL agent's learning behavior is largely unknown. In a bottom-up approach with two experiments, this work provides a data-driven understanding of the factors of human observers' understanding of the agent's learning process. A novel, observation-based paradigm to directly assess human inferences about agent learning was developed. In an exploratory interview study (\textit{N}=9), we identify four core themes in human interpretations: Agent Goals, Knowledge, Decision Making, and Learning Mechanisms. A second confirmatory study (\textit{N}=34) applied an expanded version of the paradigm across two tasks (navigation/manipulation) and two RL algorithms (tabular/function approximation). Analyses of 816 responses confirmed the reliability of the paradigm and refined the thematic framework, revealing how these themes evolve over time and interrelate. Our findings provide a human-centered understanding of how people make sense of agent learning, offering actionable insights for designing interpretable RL systems and improving transparency in Human-Robot Interaction.
Robot Policy Transfer with Online Demonstrations: An Active Reinforcement Learning Approach
Mar 17, 2025



Transfer Learning (TL) is a powerful tool that enables robots to transfer learned policies across different environments, tasks, or embodiments. To further facilitate this process, efforts have been made to combine it with Learning from Demonstrations (LfD) for more flexible and efficient policy transfer. However, these approaches are almost exclusively limited to offline demonstrations collected before policy transfer starts, which may suffer from the intrinsic issue of covariance shift brought by LfD and harm the performance of policy transfer. Meanwhile, extensive work in the learning-from-scratch setting has shown that online demonstrations can effectively alleviate covariance shift and lead to better policy performance with improved sample efficiency. This work combines these insights to introduce online demonstrations into a policy transfer setting. We present Policy Transfer with Online Demonstrations, an active LfD algorithm for policy transfer that can optimize the timing and content of queries for online episodic expert demonstrations under a limited demonstration budget. We evaluate our method in eight robotic scenarios, involving policy transfer across diverse environment characteristics, task objectives, and robotic embodiments, with the aim to transfer a trained policy from a source task to a related but different target task. The results show that our method significantly outperforms all baselines in terms of average success rate and sample efficiency, compared to two canonical LfD methods with offline demonstrations and one active LfD method with online demonstrations. Additionally, we conduct preliminary sim-to-real tests of the transferred policy on three transfer scenarios in the real-world environment, demonstrating the policy effectiveness on a real robot manipulator.
Active Robot Curriculum Learning from Online Human Demonstrations
Mar 04, 2025Learning from Demonstrations (LfD) allows robots to learn skills from human users, but its effectiveness can suffer due to sub-optimal teaching, especially from untrained demonstrators. Active LfD aims to improve this by letting robots actively request demonstrations to enhance learning. However, this may lead to frequent context switches between various task situations, increasing the human cognitive load and introducing errors to demonstrations. Moreover, few prior studies in active LfD have examined how these active query strategies may impact human teaching in aspects beyond user experience, which can be crucial for developing algorithms that benefit both robot learning and human teaching. To tackle these challenges, we propose an active LfD method that optimizes the query sequence of online human demonstrations via Curriculum Learning (CL), where demonstrators are guided to provide demonstrations in situations of gradually increasing difficulty. We evaluate our method across four simulated robotic tasks with sparse rewards and conduct a user study (N=26) to investigate the influence of active LfD methods on human teaching regarding teaching performance, post-guidance teaching adaptivity, and teaching transferability. Our results show that our method significantly improves learning performance compared to three other LfD baselines in terms of the final success rate of the converged policy and sample efficiency. Additionally, results from our user study indicate that our method significantly reduces the time required from human demonstrators and decreases failed demonstration attempts. It also enhances post-guidance human teaching in both seen and unseen scenarios compared to another active LfD baseline, indicating enhanced teaching performance, greater post-guidance teaching adaptivity, and better teaching transferability achieved by our method.
"Give Me an Example Like This": Episodic Active Reinforcement Learning from Demonstrations
Jun 06, 2024



Reinforcement Learning (RL) has achieved great success in sequential decision-making problems, but often at the cost of a large number of agent-environment interactions. To improve sample efficiency, methods like Reinforcement Learning from Expert Demonstrations (RLED) introduce external expert demonstrations to facilitate agent exploration during the learning process. In practice, these demonstrations, which are often collected from human users, are costly and hence often constrained to a limited amount. How to select the best set of human demonstrations that is most beneficial for learning therefore becomes a major concern. This paper presents EARLY (Episodic Active Learning from demonstration querY), an algorithm that enables a learning agent to generate optimized queries of expert demonstrations in a trajectory-based feature space. Based on a trajectory-level estimate of uncertainty in the agent's current policy, EARLY determines the optimized timing and content for feature-based queries. By querying episodic demonstrations as opposed to isolated state-action pairs, EARLY improves the human teaching experience and achieves better learning performance. We validate the effectiveness of our method in three simulated navigation tasks of increasing difficulty. The results show that our method is able to achieve expert-level performance for all three tasks with convergence over 30\% faster than other baseline methods when demonstrations are generated by simulated oracle policies. The results of a follow-up pilot user study (N=18) further validate that our method can still maintain a significantly better convergence in the case of human expert demonstrators while achieving a better user experience in perceived task load and consuming significantly less human time.
A Multi-Behavior Planning Framework for Robot Guide
Jan 07, 2022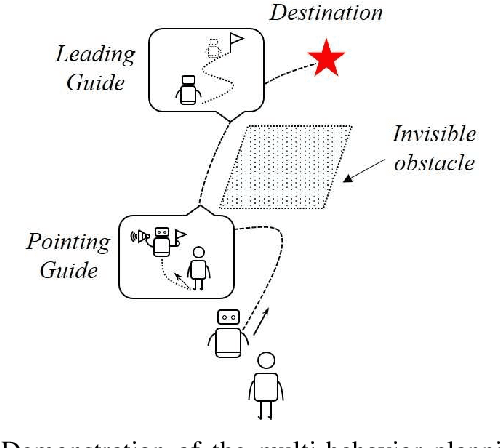
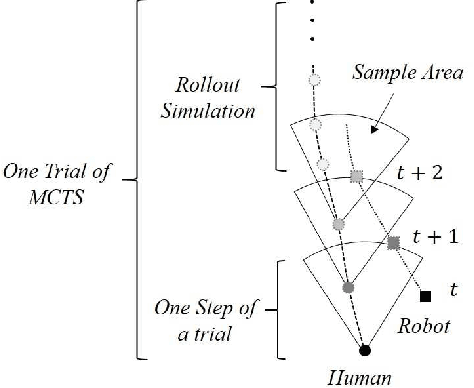
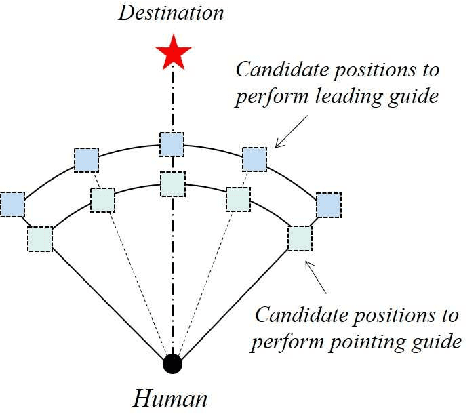
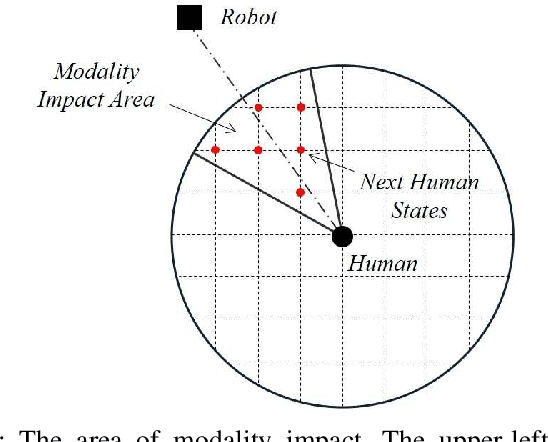
The guiding task of a mobile robot requires not only human-aware navigation, but also appropriate yet timely interaction for active instruction. State-of-the-art tour-guide models limit their socially-aware consideration to adapting to users' motion, ignoring the interactive behavior planning to fulfill the communicative demands. We propose a multi-behavior planning framework based on Monte Carlo Tree Search to better assist users to understand confusing scene contexts, select proper paths and timely arrive at the destination. To provide proactive guidance, we construct a sampling-based probability model of human motion to consider the interrelated effects between robots and humans. We validate our method both in simulation and real-world experiments along with performance comparison with state-of-the-art models.