 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Domain Analysis in Fluid Dynamics
May 28, 2025Novel techniques in evolutionary optimization, simulation and machine learning allow for a broad analysis of domains like fluid dynamics, in which computation is expensive and flow behavior is complex. Under the term of full domain analysis we understand the ability to efficiently determine the full space of solutions in a problem domain, and analyze the behavior of those solutions in an accessible and interactive manner. The goal of full domain analysis is to deepen our understanding of domains by generating many examples of flow, their diversification, optimization and analysis. We define a formal model for full domain analysis, its current state of the art, and requirements of subcomponents. Finally, an example is given to show what we can learn by using full domain analysis. Full domain analysis, rooted in optimization and machine learning, can be a helpful tool in understanding complex systems in computational physics and beyond.
Generative Design through Quality-Diversity Data Synthesis and Language Models
May 16, 2024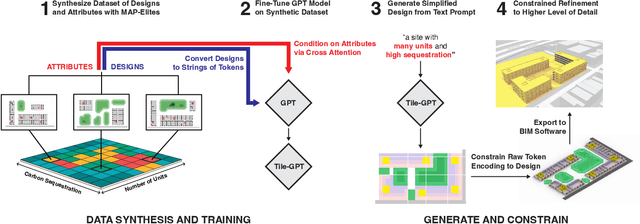

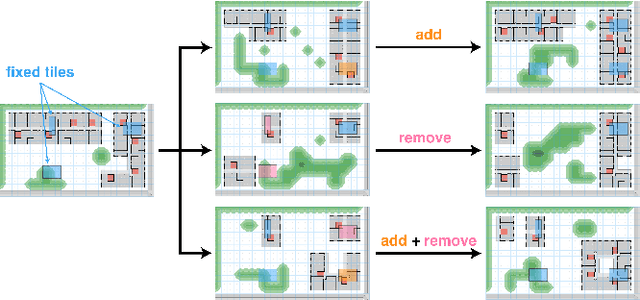
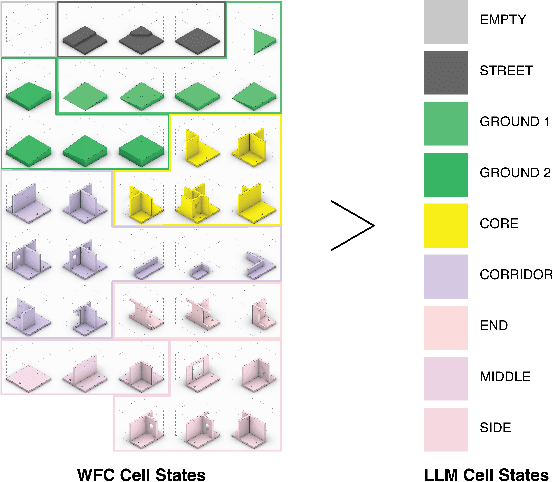
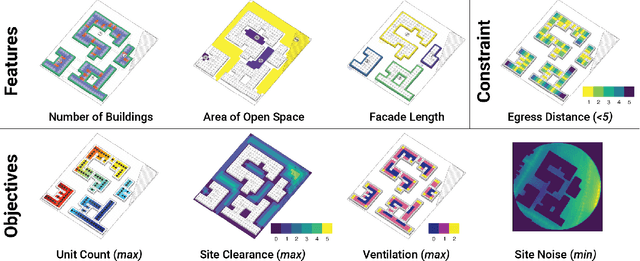
Two fundamental challenges face generative models in engineering applications: the acquisition of high-performing, diverse datasets, and the adherence to precise constraints in generated designs. We propose a novel approach combining optimization, constraint satisfaction, and language models to tackle these challenges in architectural design. Our method uses Quality-Diversity (QD) to generate a diverse, high-performing dataset. We then fine-tune a language model with this dataset to generate high-level designs. These designs are then refined into detailed, constraint-compliant layouts using the Wave Function Collapse algorithm. Our system demonstrates reliable adherence to textual guidance, enabling the generation of layouts with targeted architectural and performance features. Crucially, our results indicate that data synthesized through the evolutionary search of QD not only improves overall model performance but is essential for the model's ability to closely adhere to textual guidance. This improvement underscores the pivotal role evolutionary computation can play in creating the datasets key to training generative models for design. Web article at https://tilegpt.github.io
PlotMap: Automated Layout Design for Building Game Worlds
Sep 26, 2023



World-building, the process of developing both the narrative and physical world of a game, plays a vital role in the game's experience. Critically acclaimed independent and AAA video games are praised for strong world building, with game maps that masterfully intertwine with and elevate the narrative, captivating players and leaving a lasting impression. However, designing game maps that support a desired narrative is challenging, as it requires satisfying complex constraints from various considerations. Most existing map generation methods focus on considerations about gameplay mechanics or map topography, while the need to support the story is typically neglected. As a result, extensive manual adjustment is still required to design a game world that facilitates particular stories. In this work, we approach this problem by introducing an extra layer of plot facility layout design that is independent of the underlying map generation method in a world-building pipeline. Concretely, we present a system that leverages Reinforcement Learning (RL) to automatically assign concrete locations on a game map to abstract locations mentioned in a given story (plot facilities), following spatial constraints derived from the story. A decision-making agent moves the plot facilities around, considering their relationship to the map and each other, to locations on the map that best satisfy the constraints of the story. Our system considers input from multiple modalities: map images as pixels, facility locations as real values, and story constraints expressed in natural language. We develop a method of generating datasets of facility layout tasks, create an RL environment to train and evaluate RL models, and further analyze the behaviors of the agents through a group of comprehensive experiments and ablation studies, aiming to provide insights for RL-based plot facility layout design.
T-DominO: Exploring Multiple Criteria with Quality-Diversity and the Tournament Dominance Objective
Jul 04, 2022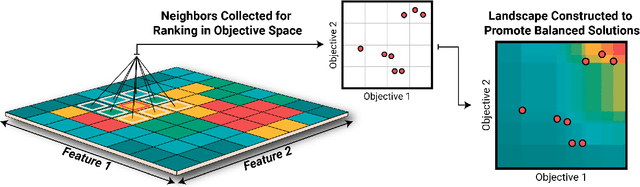
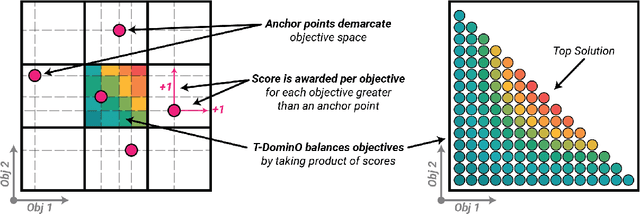
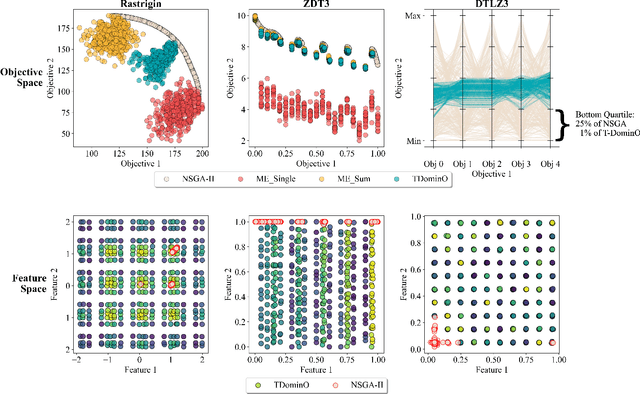
Real-world design problems are a messy combination of constraints, objectives, and features. Exploring these problem spaces can be defined as a Multi-Criteria Exploration (MCX) problem, whose goals are to produce a set of diverse solutions with high performance across many objectives, while avoiding low performance across any objectives. Quality-Diversity algorithms produce the needed design variation, but typically consider only a single objective. We present a new ranking, T-DominO, specifically designed to handle multiple objectives in MCX problems. T-DominO ranks individuals relative to other solutions in the archive, favoring individuals with balanced performance over those which excel at a few objectives at the cost of the others. Keeping only a single balanced solution in each MAP-Elites bin maintains the visual accessibility of the archive -- a strong asset for design exploration. We illustrate our approach on a set of easily understood benchmarks, and showcase its potential in a many-objective real-world architecture case study.
COIL: Constrained Optimization in Learned Latent Space -- Learning Representations for Valid Solutions
Feb 07, 2022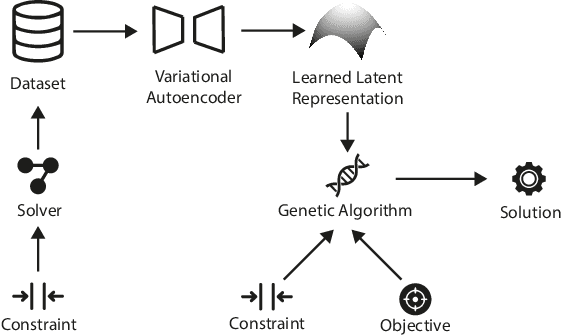
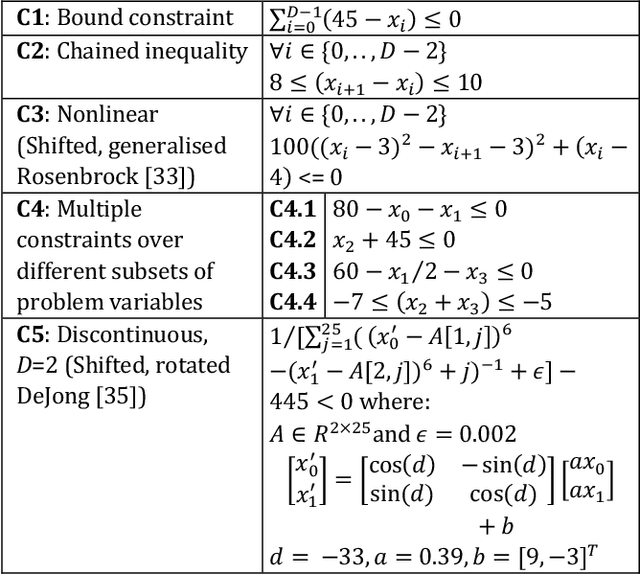
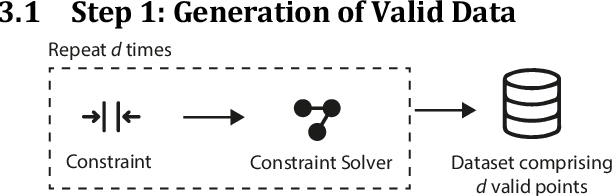
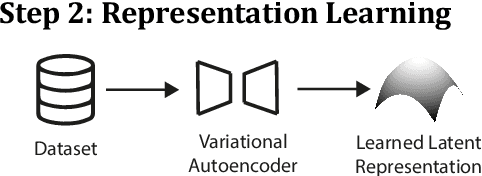
Constrained optimization problems can be difficult because their search spaces have properties not conducive to search, e.g., multimodality, discontinuities, or deception. To address such difficulties, considerable research has been performed on creating novel evolutionary algorithms or specialized genetic operators. However, if the representation that defined the search space could be altered such that it only permitted valid solutions that satisfied the constraints, the task of finding the optimal would be made more feasible without any need for specialized optimization algorithms. We propose the use of a Variational Autoencoder to learn such representations. We present Constrained Optimization in Latent Space (COIL), which uses a VAE to generate a learned latent representation from a dataset comprising samples from the valid region of the search space according to a constraint, thus enabling the optimizer to find the objective in the new space defined by the learned representation. We investigate the value of this approach on different constraint types and for different numbers of variables. We show that, compared to an identical GA using a standard representation, COIL with its learned latent representation can satisfy constraints and find solutions with distance to objective up to two orders of magnitude closer.
Automating Representation Discovery with MAP-Elites
Mar 09, 2020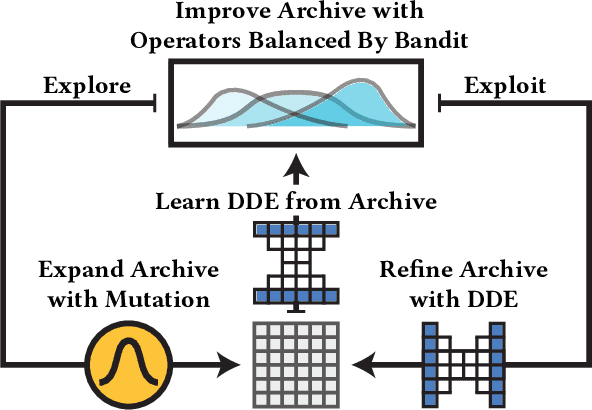
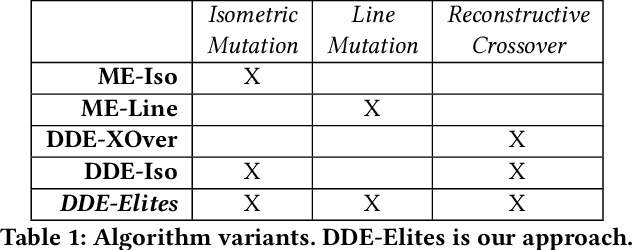
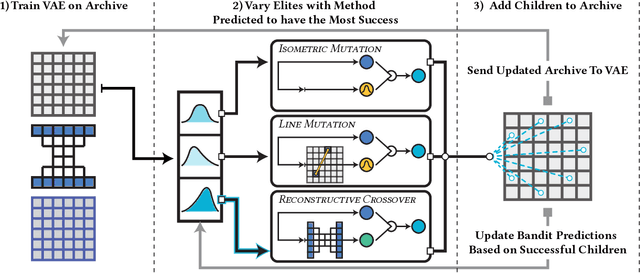
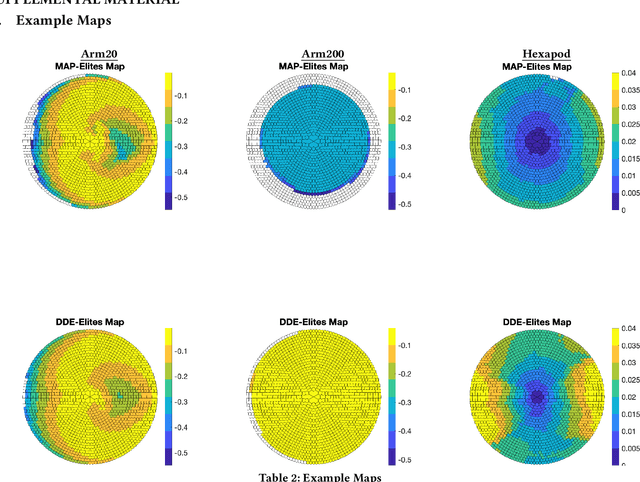
The way solutions are represented, or encoded, is usually the result of domain knowledge and experience. In this work, we combine MAP-Elites with Variational Autoencoders to learn a Data-Driven Encoding (DDE) that captures the essence of the highest-performing solutions while still able to encode a wide array of solutions. Our approach learns this data-driven encoding during optimization by balancing between exploiting the DDE to generalize the knowledge contained in the current archive of elites and exploring new representations that are not yet captured by the DDE. Learning representation during optimization allows the algorithm to solve high-dimensional problems, and provides a low-dimensional representation which can be then be re-used. We evaluate the DDE approach by evolving solutions for inverse kinematics of a planar arm (200 joint angles) and for gaits of a 6-legged robot in action space (a sequence of 60 positions for each of the 12 joints). We show that the DDE approach not only accelerates and improves optimization, but produces a powerful encoding that captures a bias for high performance while expressing a variety of solutions.
Prediction of neural network performance by phenotypic modeling
Jul 16, 2019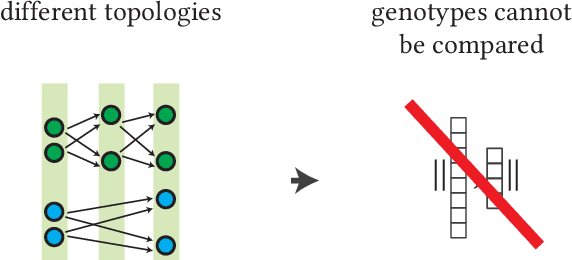
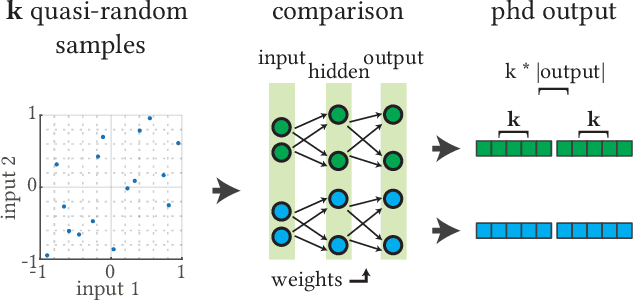
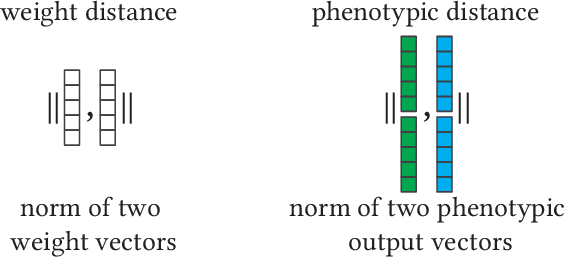
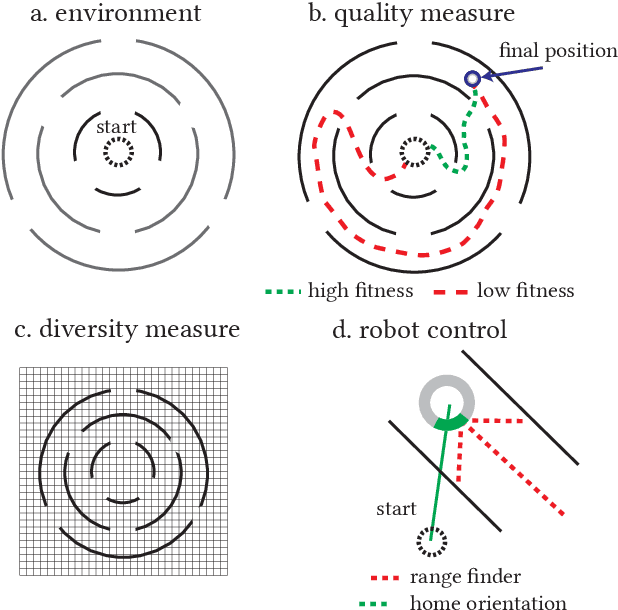
Surrogate models are used to reduce the burden of expensive-to-evaluate objective functions in optimization. By creating models which map genomes to objective values, these models can estimate the performance of unknown inputs, and so be used in place of expensive objective functions. Evolutionary techniques such as genetic programming or neuroevolution commonly alter the structure of the genome itself. A lack of consistency in the genotype is a fatal blow to data-driven modeling techniques: interpolation between points is impossible without a common input space. However, while the dimensionality of genotypes may differ across individuals, in many domains, such as controllers or classifiers, the dimensionality of the input and output remains constant. In this work we leverage this insight to embed differing neural networks into the same input space. To judge the difference between the behavior of two neural networks, we give them both the same input sequence, and examine the difference in output. This difference, the phenotypic distance, can then be used to situate these networks into a common input space, allowing us to produce surrogate models which can predict the performance of neural networks regardless of topology. In a robotic navigation task, we show that models trained using this phenotypic embedding perform as well or better as those trained on the weight values of a fixed topology neural network. We establish such phenotypic surrogate models as a promising and flexible approach which enables surrogate modeling even for representations that undergo structural changes.
Weight Agnostic Neural Networks
Jun 11, 2019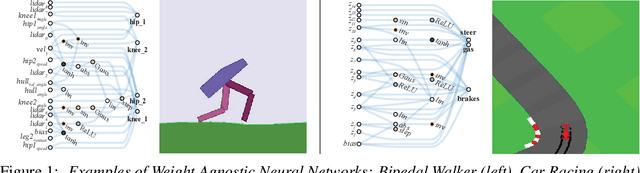
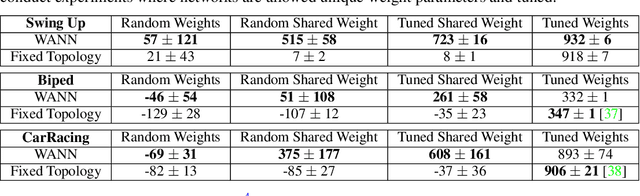
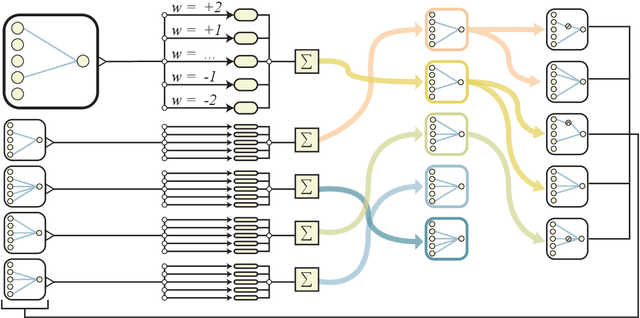
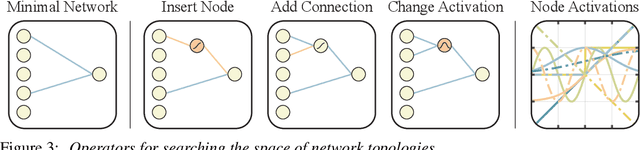
Not all neural network architectures are created equal, some perform much better than others for certain tasks. But how important are the weight parameters of a neural network compared to its architecture? In this work, we question to what extent neural network architectures alone, without learning any weight parameters, can encode solutions for a given task. We propose a search method for neural network architectures that can already perform a task without any explicit weight training. To evaluate these networks, we populate the connections with a single shared weight parameter sampled from a uniform random distribution, and measure the expected performance. We demonstrate that our method can find minimal neural network architectures that can perform several reinforcement learning tasks without weight training. On a supervised learning domain, we find network architectures that achieve much higher than chance accuracy on MNIST using random weights. Interactive version of this paper at https://weightagnostic.github.io/
Data-Efficient Design Exploration through Surrogate-Assisted Illumination
Jun 15, 2018Design optimization techniques are often used at the beginning of the design process to explore the space of possible designs. In these domains illumination algorithms, such as MAP-Elites, are promising alternatives to classic optimization algorithms because they produce diverse, high-quality solutions in a single run, instead of only a single near-optimal solution. Unfortunately, these algorithms currently require a large number of function evaluations, limiting their applicability. In this article we introduce a new illumination algorithm, Surrogate-Assisted Illumination (SAIL), that leverages surrogate modeling techniques to create a map of the design space according to user-defined features while minimizing the number of fitness evaluations. On a 2-dimensional airfoil optimization problem SAIL produces hundreds of diverse but high-performing designs with several orders of magnitude fewer evaluations than MAP-Elites or CMA-ES. We demonstrate that SAIL is also capable of producing maps of high-performing designs in realistic 3-dimensional aerodynamic tasks with an accurate flow simulation. Data-efficient design exploration with SAIL can help designers understand what is possible, beyond what is optimal, by considering more than pure objective-based optimization.
Data-efficient Neuroevolution with Kernel-Based Surrogate Models
Apr 17, 2018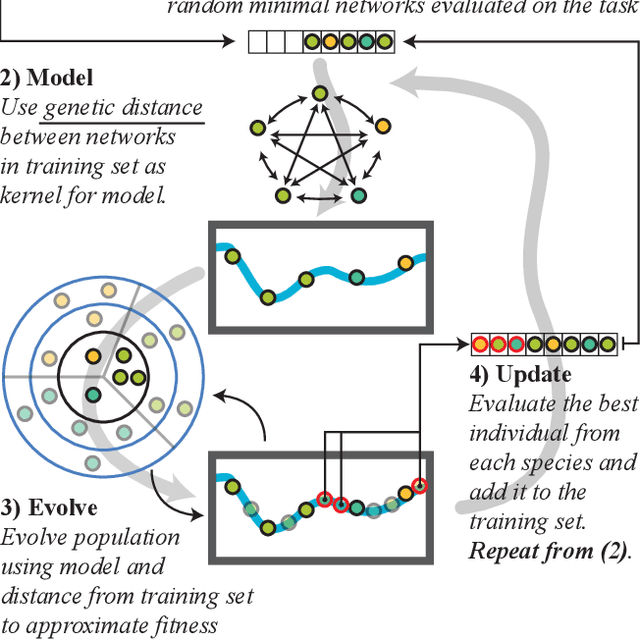

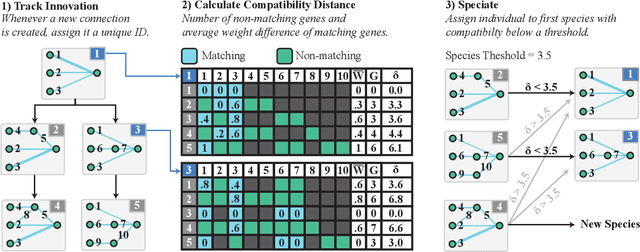
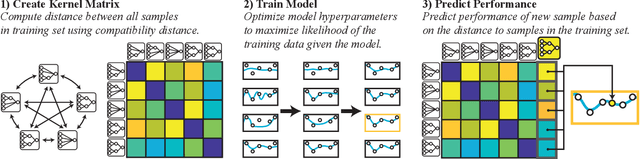
Surrogate-assistance approaches have long been used in computationally expensive domains to improve the data-efficiency of optimization algorithms. Neuroevolution, however, has so far resisted the application of these techniques because it requires the surrogate model to make fitness predictions based on variable topologies, instead of a vector of parameters. Our main insight is that we can sidestep this problem by using kernel-based surrogate models, which require only the definition of a distance measure between individuals. Our second insight is that the well-established Neuroevolution of Augmenting Topologies (NEAT) algorithm provides a computationally efficient distance measure between dissimilar networks in the form of "compatibility distance", initially designed to maintain topological diversity. Combining these two ideas, we introduce a surrogate-assisted neuroevolution algorithm that combines NEAT and a surrogate model built using a compatibility distance kernel. We demonstrate the data-efficiency of this new algorithm on the low dimensional cart-pole swing-up problem, as well as the higher dimensional half-cheetah running task. In both tasks the surrogate-assisted variant achieves the same or better results with several times fewer function evaluations as the original NEAT.