 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunPhase: A Periodic Functional Autoencoder for Motion Generation via Phase Manifolds
Dec 10, 2025Learning natural body motion remains challenging due to the strong coupling between spatial geometry and temporal dynamics. Embedding motion in phase manifolds, latent spaces that capture local periodicity, has proven effective for motion prediction; however, existing approaches lack scalability and remain confined to specific settings. We introduce FunPhase, a functional periodic autoencoder that learns a phase manifold for motion and replaces discrete temporal decoding with a function-space formulation, enabling smooth trajectories that can be sampled at arbitrary temporal resolutions. FunPhase supports downstream tasks such as super-resolution and partial-body motion completion, generalizes across skeletons and datasets, and unifies motion prediction and generation within a single interpretable manifold. Our model achieves substantially lower reconstruction error than prior periodic autoencoder baselines while enabling a broader range of applications and performing on par with state-of-the-art motion generation methods.
UniMoGen: Universal Motion Generation
May 28, 2025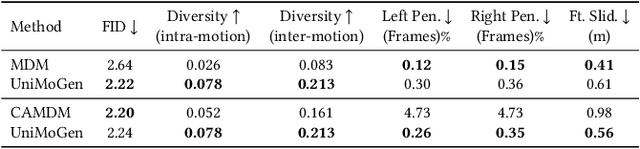
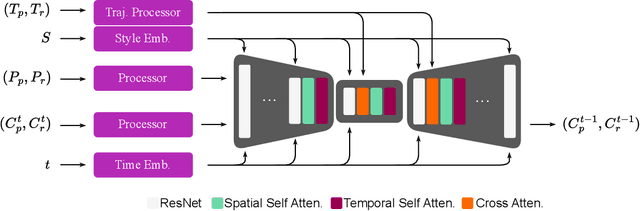


Motion generation is a cornerstone of computer graphics, animation, gaming, and robotics, enabling the creation of realistic and varied character movements. A significant limitation of existing methods is their reliance on specific skeletal structures, which restricts their versatility across different characters. To overcome this, we introduce UniMoGen, a novel UNet-based diffusion model designed for skeleton-agnostic motion generation. UniMoGen can be trained on motion data from diverse characters, such as humans and animals, without the need for a predefined maximum number of joints. By dynamically processing only the necessary joints for each character, our model achieves both skeleton agnosticism and computational efficiency. Key features of UniMoGen include controllability via style and trajectory inputs, and the ability to continue motions from past frames. We demonstrate UniMoGen's effectiveness on the 100style dataset, where it outperforms state-of-the-art methods in diverse character motion generation. Furthermore, when trained on both the 100style and LAFAN1 datasets, which use different skeletons, UniMoGen achieves high performance and improved efficiency across both skeletons. These results highlight UniMoGen's potential to advance motion generation by providing a flexible, efficient, and controllable solution for a wide range of character animations.
PlotMap: Automated Layout Design for Building Game Worlds
Sep 26, 2023



World-building, the process of developing both the narrative and physical world of a game, plays a vital role in the game's experience. Critically acclaimed independent and AAA video games are praised for strong world building, with game maps that masterfully intertwine with and elevate the narrative, captivating players and leaving a lasting impression. However, designing game maps that support a desired narrative is challenging, as it requires satisfying complex constraints from various considerations. Most existing map generation methods focus on considerations about gameplay mechanics or map topography, while the need to support the story is typically neglected. As a result, extensive manual adjustment is still required to design a game world that facilitates particular stories. In this work, we approach this problem by introducing an extra layer of plot facility layout design that is independent of the underlying map generation method in a world-building pipeline. Concretely, we present a system that leverages Reinforcement Learning (RL) to automatically assign concrete locations on a game map to abstract locations mentioned in a given story (plot facilities), following spatial constraints derived from the story. A decision-making agent moves the plot facilities around, considering their relationship to the map and each other, to locations on the map that best satisfy the constraints of the story. Our system considers input from multiple modalities: map images as pixels, facility locations as real values, and story constraints expressed in natural language. We develop a method of generating datasets of facility layout tasks, create an RL environment to train and evaluate RL models, and further analyze the behaviors of the agents through a group of comprehensive experiments and ablation studies, aiming to provide insights for RL-based plot facility layout design.
Sketch-A-Shape: Zero-Shot Sketch-to-3D Shape Generation
Jul 08, 2023



Significant progress has recently been made in creative applications of large pre-trained models for downstream tasks in 3D vision, such as text-to-shape generation. This motivates our investigation of how these pre-trained models can be used effectively to generate 3D shapes from sketches, which has largely remained an open challenge due to the limited sketch-shape paired datasets and the varying level of abstraction in the sketches. We discover that conditioning a 3D generative model on the features (obtained from a frozen large pre-trained vision model) of synthetic renderings during training enables us to effectively generate 3D shapes from sketches at inference time. This suggests that the large pre-trained vision model features carry semantic signals that are resilient to domain shifts, i.e., allowing us to use only RGB renderings, but generalizing to sketches at inference time. We conduct a comprehensive set of experiments investigating different design factors and demonstrate the effectiveness of our straightforward approach for generation of multiple 3D shapes per each input sketch regardless of their level of abstraction without requiring any paired datasets during training.