 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Determine the Preferred Image Distribution of a Black-Box Vision-Language Model?
Sep 03, 2024Large foundation models have revolutionized the field, yet challenges remain in optimizing multi-modal models for specialized visual tasks. We propose a novel, generalizable methodology to identify preferred image distributions for black-box Vision-Language Models (VLMs) by measuring output consistency across varied input prompts. Applying this to different rendering types of 3D objects, we demonstrate its efficacy across various domains requiring precise interpretation of complex structures, with a focus on Computer-Aided Design (CAD) as an exemplar field. We further refine VLM outputs using in-context learning with human feedback, significantly enhancing explanation quality. To address the lack of benchmarks in specialized domains, we introduce CAD-VQA, a new dataset for evaluating VLMs on CAD-related visual question answering tasks. Our evaluation of state-of-the-art VLMs on CAD-VQA establishes baseline performance levels, providing a framework for advancing VLM capabilities in complex visual reasoning tasks across various fields requiring expert-level visual interpretation. We release the dataset and evaluation codes at \url{https://github.com/asgsaeid/cad_vqa}.
Detecting Generative Parroting through Overfitting Masked Autoencoders
Mar 27, 2024

The advent of generative AI models has revolutionized digital content creation, yet it introduces challenges in maintaining copyright integrity due to generative parroting, where models mimic their training data too closely. Our research presents a novel approach to tackle this issue by employing an overfitted Masked Autoencoder (MAE) to detect such parroted samples effectively. We establish a detection threshold based on the mean loss across the training dataset, allowing for the precise identification of parroted content in modified datasets. Preliminary evaluations demonstrate promising results, suggesting our method's potential to ensure ethical use and enhance the legal compliance of generative models.
Sketch-A-Shape: Zero-Shot Sketch-to-3D Shape Generation
Jul 08, 2023



Significant progress has recently been made in creative applications of large pre-trained models for downstream tasks in 3D vision, such as text-to-shape generation. This motivates our investigation of how these pre-trained models can be used effectively to generate 3D shapes from sketches, which has largely remained an open challenge due to the limited sketch-shape paired datasets and the varying level of abstraction in the sketches. We discover that conditioning a 3D generative model on the features (obtained from a frozen large pre-trained vision model) of synthetic renderings during training enables us to effectively generate 3D shapes from sketches at inference time. This suggests that the large pre-trained vision model features carry semantic signals that are resilient to domain shifts, i.e., allowing us to use only RGB renderings, but generalizing to sketches at inference time. We conduct a comprehensive set of experiments investigating different design factors and demonstrate the effectiveness of our straightforward approach for generation of multiple 3D shapes per each input sketch regardless of their level of abstraction without requiring any paired datasets during training.
Point2Cyl: Reverse Engineering 3D Objects from Point Clouds to Extrusion Cylinders
Dec 17, 2021
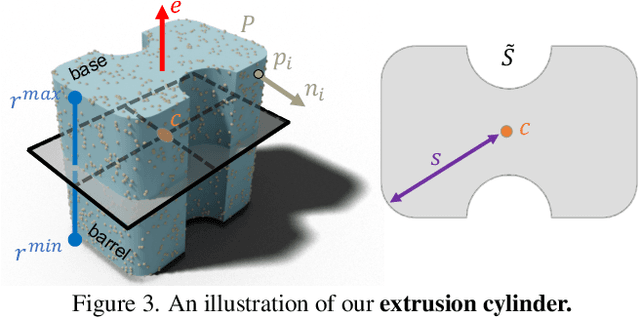
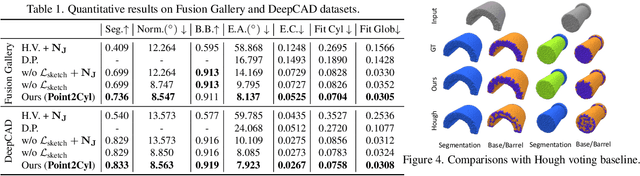

We propose Point2Cyl, a supervised network transforming a raw 3D point cloud to a set of extrusion cylinders. Reverse engineering from a raw geometry to a CAD model is an essential task to enable manipulation of the 3D data in shape editing software and thus expand their usages in many downstream applications. Particularly, the form of CAD models having a sequence of extrusion cylinders -- a 2D sketch plus an extrusion axis and range -- and their boolean combinations is not only widely used in the CAD community/software but also has great expressivity of shapes, compared to having limited types of primitives (e.g., planes, spheres, and cylinders). In this work, we introduce a neural network that solves the extrusion cylinder decomposition problem in a geometry-grounded way by first learning underlying geometric proxies. Precisely, our approach first predicts per-point segmentation, base/barrel labels and normals, then estimates for the underlying extrusion parameters in differentiable and closed-form formulations. Our experiments show that our approach demonstrates the best performance on two recent CAD datasets, Fusion Gallery and DeepCAD, and we further showcase our approach on reverse engineering and editing.
UVStyle-Net: Unsupervised Few-shot Learning of 3D Style Similarity Measure for B-Reps
Apr 28, 2021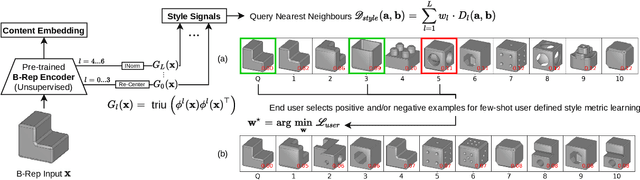

Boundary Representations (B-Reps) are the industry standard in 3D Computer Aided Design/Manufacturing (CAD/CAM) and industrial design due to their fidelity in representing stylistic details. However, they have been ignored in the 3D style research. Existing 3D style metrics typically operate on meshes or pointclouds, and fail to account for end-user subjectivity by adopting fixed definitions of style, either through crowd-sourcing for style labels or hand-crafted features. We propose UVStyle-Net, a style similarity measure for B-Reps that leverages the style signals in the second order statistics of the activations in a pre-trained (unsupervised) 3D encoder, and learns their relative importance to a subjective end-user through few-shot learning. Our approach differs from all existing data-driven 3D style methods since it may be used in completely unsupervised settings, which is desirable given the lack of publicly available labelled B-Rep datasets. More importantly, the few-shot learning accounts for the inherent subjectivity associated with style. We show quantitatively that our proposed method with B-Reps is able to capture stronger style signals than alternative methods on meshes and pointclouds despite its significantly greater computational efficiency. We also show it is able to generate meaningful style gradients with respect to the input shape, and that few-shot learning with as few as two positive examples selected by an end-user is sufficient to significantly improve the style measure. Finally, we demonstrate its efficacy on a large unlabeled public dataset of CAD models. Source code and data will be released in the future.
UV-Net: Learning from Curve-Networks and Solids
Jun 18, 2020
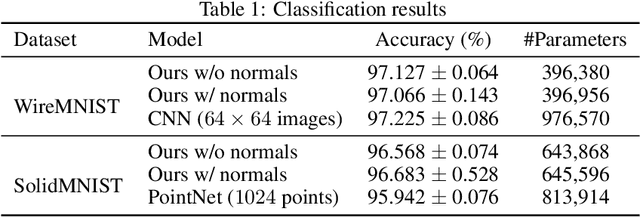
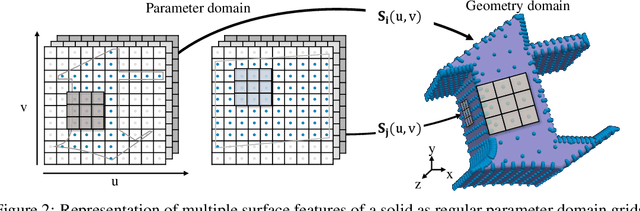
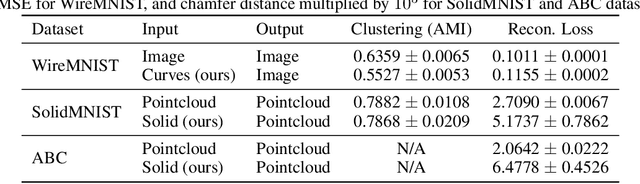
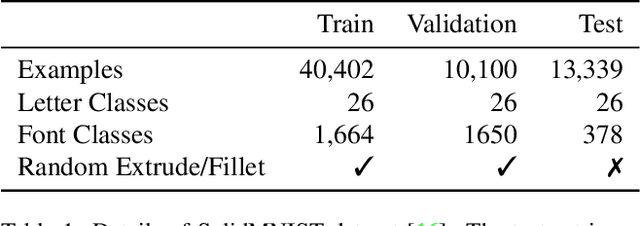
Parametric curves, surfaces and boundary representations are the basis for 2D vector graphics and 3D industrial designs. Despite their prevalence, there exists limited research on applying modern deep neural networks directly to such representations. The unique challenges in working with such representations arise from the combination of continuous non-Euclidean geometry domain and discrete topology, as well as a lack of labeled datasets, benchmarks and baseline models. In this paper, we propose a unified representation for parametric curve-networks and solids by exploiting the u- and uv-parameter domains of curve and surfaces, respectively, to model the geometry, and an adjacency graph to explicitly model the topology. This leads to a unique and efficient network architecture based on coupled image and graph convolutional neural networks to extract features from curve-networks and solids. Inspired by the MNIST image dataset, we create and publish WireMNIST (for 2D curve-networks) and SolidMNIST (for 3D solids), two related labeled datasets depicting alphabets to encourage future research in this area. We demonstrate the effectiveness of our method using supervised and self-supervised tasks on our new datasets, as well as the publicly available ABC dataset. The results demonstrate the effectiveness of our representation and provide a competitive baseline for learning tasks involving curve-networks and solids.