 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Motion Infilling From Imprecisely Timed Keyframes
Mar 02, 2025

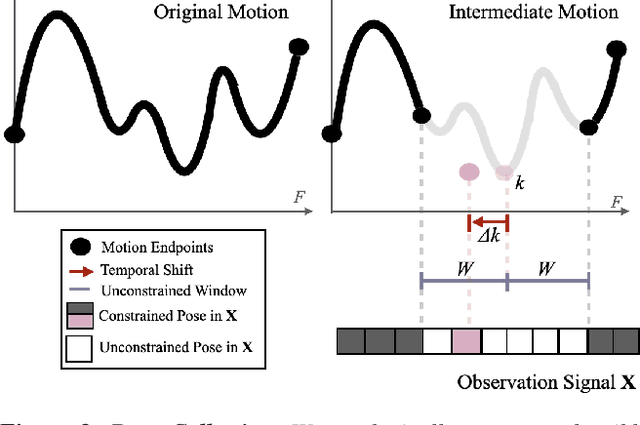

Keyframes are a standard representation for kinematic motion specification. Recent learned motion-inbetweening methods use keyframes as a way to control generative motion models, and are trained to generate life-like motion that matches the exact poses and timings of input keyframes. However, the quality of generated motion may degrade if the timing of these constraints is not perfectly consistent with the desired motion. Unfortunately, correctly specifying keyframe timings is a tedious and challenging task in practice. Our goal is to create a system that synthesizes high-quality motion from keyframes, even if keyframes are imprecisely timed. We present a method that allows constraints to be retimed as part of the generation process. Specifically, we introduce a novel model architecture that explicitly outputs a time-warping function to correct mistimed keyframes, and spatial residuals that add pose details. We demonstrate how our method can automatically turn approximately timed keyframe constraints into diverse, realistic motions with plausible timing and detailed submovements.
Iterative Motion Editing with Natural Language
Dec 15, 2023



Text-to-motion diffusion models can generate realistic animations from text prompts, but do not support fine-grained motion editing controls. In this paper we present a method for using natural language to iteratively specify local edits to existing character animations, a task that is common in most computer animation workflows. Our key idea is to represent a space of motion edits using a set of kinematic motion operators that have well-defined semantics for how to modify specific frames of a target motion. We provide an algorithm that leverages pre-existing language models to translate textual descriptions of motion edits to sequences of motion editing operators (MEOs). Given new keyframes produced by the MEOs, we use diffusion-based keyframe interpolation to generate final motions. Through a user study and quantitative evaluation, we demonstrate that our system can perform motion edits that respect the animator's editing intent, remain faithful to the original animation (they edit the original animation, not dramatically change it), and yield realistic character animation results.
Point2Cyl: Reverse Engineering 3D Objects from Point Clouds to Extrusion Cylinders
Dec 17, 2021
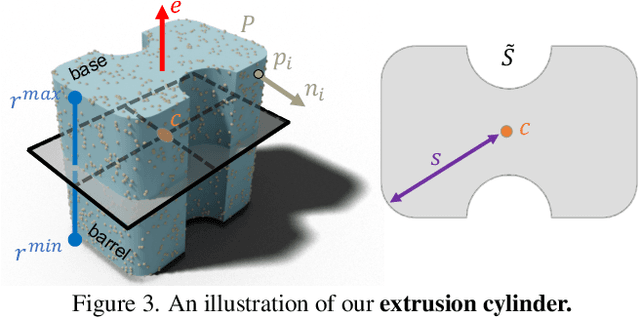
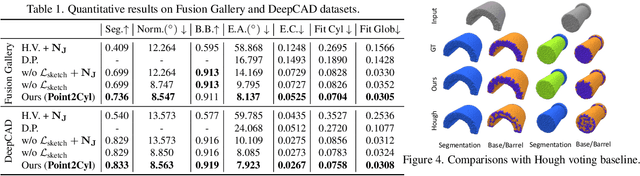

We propose Point2Cyl, a supervised network transforming a raw 3D point cloud to a set of extrusion cylinders. Reverse engineering from a raw geometry to a CAD model is an essential task to enable manipulation of the 3D data in shape editing software and thus expand their usages in many downstream applications. Particularly, the form of CAD models having a sequence of extrusion cylinders -- a 2D sketch plus an extrusion axis and range -- and their boolean combinations is not only widely used in the CAD community/software but also has great expressivity of shapes, compared to having limited types of primitives (e.g., planes, spheres, and cylinders). In this work, we introduce a neural network that solves the extrusion cylinder decomposition problem in a geometry-grounded way by first learning underlying geometric proxies. Precisely, our approach first predicts per-point segmentation, base/barrel labels and normals, then estimates for the underlying extrusion parameters in differentiable and closed-form formulations. Our experiments show that our approach demonstrates the best performance on two recent CAD datasets, Fusion Gallery and DeepCAD, and we further showcase our approach on reverse engineering and editing.
On the Robustness of Monte Carlo Dropout Trained with Noisy Labels
Mar 22, 2021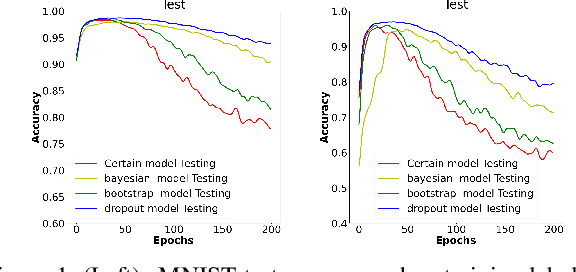


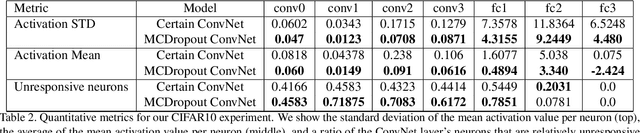
The memorization effect of deep learning hinders its performance to effectively generalize on test set when learning with noisy labels. Prior study has discovered that epistemic uncertainty techniques are robust when trained with noisy labels compared with neural networks without uncertainty estimation. They obtain prolonged memorization effect and better generalization performance under the adversarial setting of noisy labels. Due to its superior performance amongst other selected epistemic uncertainty methods under noisy labels, we focus on Monte Carlo Dropout (MCDropout) and investigate why it is robust when trained with noisy labels. Through empirical studies on datasets MNIST, CIFAR-10, Animal-10n, we deep dive into three aspects of MCDropout under noisy label setting: 1. efficacy: understanding the learning behavior and test accuracy of MCDropout when training set contains artificially generated or naturally embedded label noise; 2. representation volatility: studying the responsiveness of neurons by examining the mean and standard deviation on each neuron's activation; 3. network sparsity: investigating the network support of MCDropout in comparison with deterministic neural networks. Our findings suggest that MCDropout further sparsifies and regularizes the deterministic neural networks and thus provides higher robustness against noisy labels.
ICodeNet -- A Hierarchical Neural Network Approach for Source Code Author Identification
Jan 30, 2021
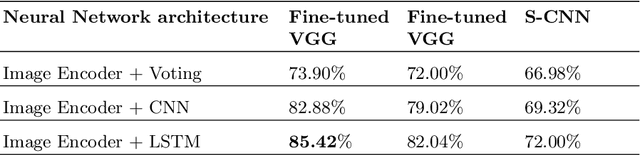
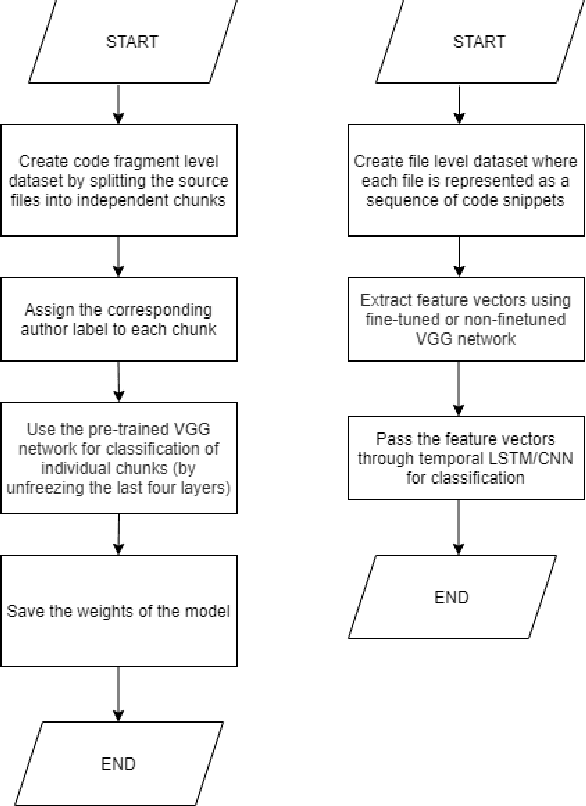
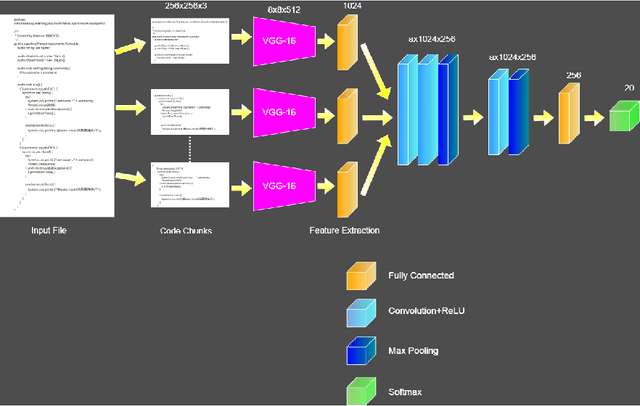
With the open-source revolution, source codes are now more easily accessible than ever. This has, however, made it easier for malicious users and institutions to copy the code without giving regards to the license, or credit to the original author. Therefore, source code author identification is a critical task with paramount importance. In this paper, we propose ICodeNet - a hierarchical neural network that can be used for source code file-level tasks. The ICodeNet processes source code in image format and is employed for the task of per file author identification. The ICodeNet consists of an ImageNet trained VGG encoder followed by a shallow neural network. The shallow network is based either on CNN or LSTM. Different variations of models are evaluated on a source code author classification dataset. We have also compared our image-based hierarchical neural network model with simple image-based CNN architecture and text-based CNN and LSTM models to highlight its novelty and efficiency.
Shape From Tracing: Towards Reconstructing 3D Object Geometry and SVBRDF Material from Images via Differentiable Path Tracing
Dec 06, 2020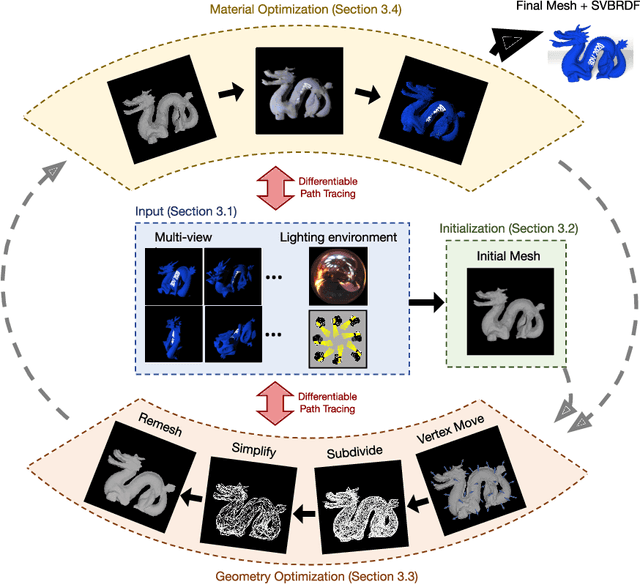
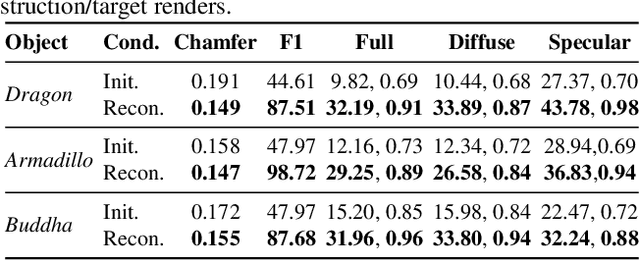


Reconstructing object geometry and material from multiple views typically requires optimization. Differentiable path tracing is an appealing framework as it can reproduce complex appearance effects. However, it is difficult to use due to high computational cost. In this paper, we explore how to use differentiable ray tracing to refine an initial coarse mesh and per-mesh-facet material representation. In simulation, we find that it is possible to reconstruct fine geometric and material detail from low resolution input views, allowing high-quality reconstructions in a few hours despite the expense of path tracing. The reconstructions successfully disambiguate shading, shadow, and global illumination effects such as diffuse interreflection from material properties. We demonstrate the impact of different geometry initializations, including space carving, multi-view stereo, and 3D neural networks. Finally, with input captured using smartphone video and a consumer 360? camera for lighting estimation, we also show how to refine initial reconstructions of real-world objects in unconstrained environments.
Robust Deep Learning with Active Noise Cancellation for Spatial Computing
Nov 16, 2020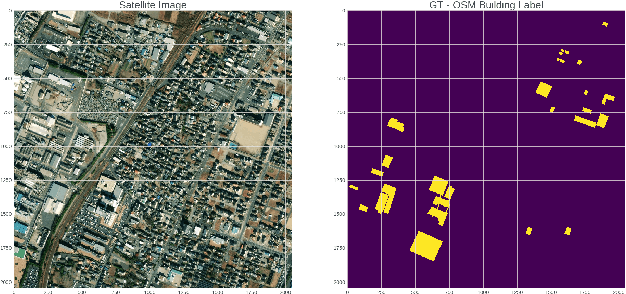
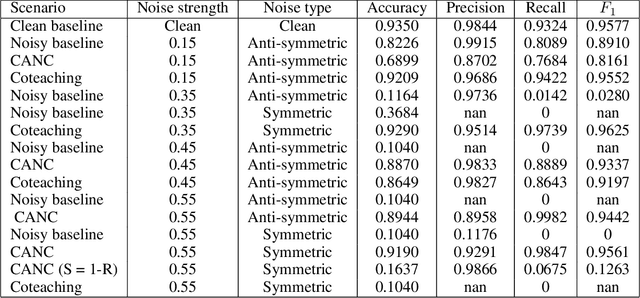
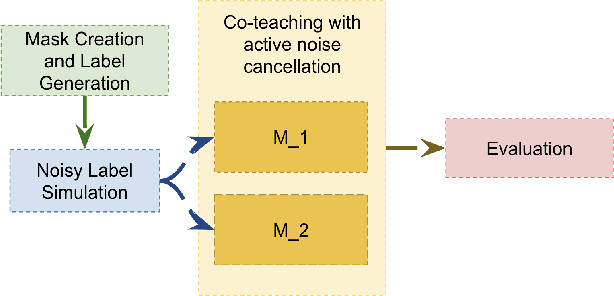
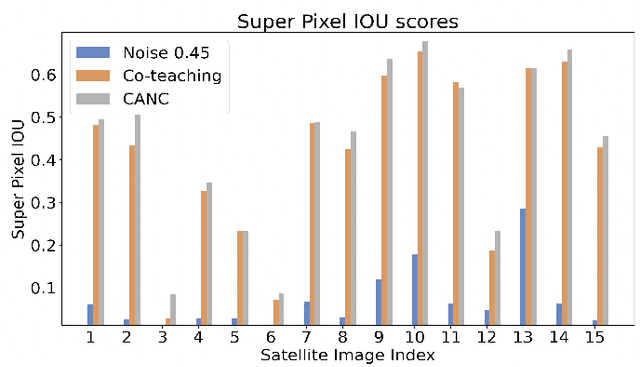
This paper proposes CANC, a Co-teaching Active Noise Cancellation method, applied in spatial computing to address deep learning trained with extreme noisy labels. Deep learning algorithms have been successful in spatial computing for land or building footprint recognition. However a lot of noise exists in ground truth labels due to how labels are collected in spatial computing and satellite imagery. Existing methods to deal with extreme label noise conduct clean sample selection and do not utilize the remaining samples. Such techniques can be wasteful due to the cost of data retrieval. Our proposed CANC algorithm not only conserves high-cost training samples but also provides active label correction to better improve robust deep learning with extreme noisy labels. We demonstrate the effectiveness of CANC for building footprint recognition for spatial computing.
Deep Learning for Hindi Text Classification: A Comparison
Jan 19, 2020
Natural Language Processing (NLP) and especially natural language text analysis have seen great advances in recent times. Usage of deep learning in text processing has revolutionized the techniques for text processing and achieved remarkable results. Different deep learning architectures like CNN, LSTM, and very recent Transformer have been used to achieve state of the art results variety on NLP tasks. In this work, we survey a host of deep learning architectures for text classification tasks. The work is specifically concerned with the classification of Hindi text. The research in the classification of morphologically rich and low resource Hindi language written in Devanagari script has been limited due to the absence of large labeled corpus. In this work, we used translated versions of English data-sets to evaluate models based on CNN, LSTM and Attention. Multilingual pre-trained sentence embeddings based on BERT and LASER are also compared to evaluate their effectiveness for the Hindi language. The paper also serves as a tutorial for popular text classification techniques.