 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSF: On Pre-training and Scaling of Sleep Foundation Models
Feb 27, 2026Polysomnography (PSG) provides the gold standard for sleep assessment but suffers from substantial heterogeneity across recording devices and cohorts. There have been growing efforts to build general-purpose foundation models (FMs) for sleep physiology, but lack an in-depth understanding of the pre-training process and scaling patterns that lead to more generalizable sleep FMs. To fill this gap, we curate a massive corpus of 166,500 hours of sleep recordings from nine public sources and establish SleepBench, a comprehensive, fully open-source benchmark. Leveraging SleepBench, we systematically evaluate four families of self-supervised pre-training objectives and uncover three critical findings: (1) existing FMs fail to generalize to missing channels at inference; (2) channel-invariant feature learning is essential for pre-training; and (3) scaling sample size, model capacity, and multi-source data mixture consistently improves downstream performance.With an enhanced pre-training and scaling recipe, we introduce OSF, a family of sleep FMs that achieves state-of-the-art performance across nine datasets on diverse sleep and disease prediction tasks. Further analysis of OSF also reveals intriguing properties in sample efficiency, hierarchical aggregation, and cross-dataset scaling.
ConStruct: Structural Distillation of Foundation Models for Prototype-Based Weakly Supervised Histopathology Segmentation
Dec 11, 2025Weakly supervised semantic segmentation (WSSS) in histopathology relies heavily on classification backbones, yet these models often localize only the most discriminative regions and struggle to capture the full spatial extent of tissue structures. Vision-language models such as CONCH offer rich semantic alignment and morphology-aware representations, while modern segmentation backbones like SegFormer preserve fine-grained spatial cues. However, combining these complementary strengths remains challenging, especially under weak supervision and without dense annotations. We propose a prototype learning framework for WSSS in histopathological images that integrates morphology-aware representations from CONCH, multi-scale structural cues from SegFormer, and text-guided semantic alignment to produce prototypes that are simultaneously semantically discriminative and spatially coherent. To effectively leverage these heterogeneous sources, we introduce text-guided prototype initialization that incorporates pathology descriptions to generate more complete and semantically accurate pseudo-masks. A structural distillation mechanism transfers spatial knowledge from SegFormer to preserve fine-grained morphological patterns and local tissue boundaries during prototype learning. Our approach produces high-quality pseudo masks without pixel-level annotations, improves localization completeness, and enhances semantic consistency across tissue types. Experiments on BCSS-WSSS datasets demonstrate that our prototype learning framework outperforms existing WSSS methods while remaining computationally efficient through frozen foundation model backbones and lightweight trainable adapters.
DualProtoSeg: Simple and Efficient Design with Text- and Image-Guided Prototype Learning for Weakly Supervised Histopathology Image Segmentation
Dec 11, 2025Weakly supervised semantic segmentation (WSSS) in histopathology seeks to reduce annotation cost by learning from image-level labels, yet it remains limited by inter-class homogeneity, intra-class heterogeneity, and the region-shrinkage effect of CAM-based supervision. We propose a simple and effective prototype-driven framework that leverages vision-language alignment to improve region discovery under weak supervision. Our method integrates CoOp-style learnable prompt tuning to generate text-based prototypes and combines them with learnable image prototypes, forming a dual-modal prototype bank that captures both semantic and appearance cues. To address oversmoothing in ViT representations, we incorporate a multi-scale pyramid module that enhances spatial precision and improves localization quality. Experiments on the BCSS-WSSS benchmark show that our approach surpasses existing state-of-the-art methods, and detailed analyses demonstrate the benefits of text description diversity, context length, and the complementary behavior of text and image prototypes. These results highlight the effectiveness of jointly leveraging textual semantics and visual prototype learning for WSSS in digital pathology.
Effect of nearby Metals on Electro-Quasistatic Human Body Communication
Oct 06, 2025In recent decades Human Body Communication has emerged as a promising alternative to traditional radio wave communication, utilizing the body's conductive properties for low-power connectivity among wearables. This method harnesses the human body as an energy-efficient channel for data transmission within the electro-quasistatic frequency range, enabling advancements in human-machine interaction. While prior work has noted the role of parasitic return paths in such capacitively coupled systems, the influence of surrounding metallic objects on these paths, which are critical for EQS wireless signaling, has not been fully explored. This paper fills that gap with a structured study of how various conducting objects, from non-grounded (floating) metals and grounded metals to enclosed metallic environments such as elevators and cars, affect the body-communication channel. We present a theoretical framework supported by finite element method simulations and experiments with wearable devices. Results show that metallic objects within 20 cm of devices can reduce transmission loss by about 10 dB. When a device ground connects to a grounded metallic object, channel gain can increase by at least 20 dB. Contact area during touch-based interactions with grounded metals produces contact-impedance dependent high-pass channel characteristics. Proximity to metallic objects introduces variability within a critical distance, with grounded metals producing a larger overall effect than floating metals. These findings improve understanding of body-centric communication links and inform design for healthcare, consumer electronics, defense, and industrial applications.
Beyond the First Read: AI-Assisted Perceptual Error Detection in Chest Radiography Accounting for Interobserver Variability
Jun 16, 2025Chest radiography is widely used in diagnostic imaging. However, perceptual errors -- especially overlooked but visible abnormalities -- remain common and clinically significant. Current workflows and AI systems provide limited support for detecting such errors after interpretation and often lack meaningful human--AI collaboration. We introduce RADAR (Radiologist--AI Diagnostic Assistance and Review), a post-interpretation companion system. RADAR ingests finalized radiologist annotations and CXR images, then performs regional-level analysis to detect and refer potentially missed abnormal regions. The system supports a "second-look" workflow and offers suggested regions of interest (ROIs) rather than fixed labels to accommodate inter-observer variation. We evaluated RADAR on a simulated perceptual-error dataset derived from de-identified CXR cases, using F1 score and Intersection over Union (IoU) as primary metrics. RADAR achieved a recall of 0.78, precision of 0.44, and an F1 score of 0.56 in detecting missed abnormalities in the simulated perceptual-error dataset. Although precision is moderate, this reduces over-reliance on AI by encouraging radiologist oversight in human--AI collaboration. The median IoU was 0.78, with more than 90% of referrals exceeding 0.5 IoU, indicating accurate regional localization. RADAR effectively complements radiologist judgment, providing valuable post-read support for perceptual-error detection in CXR interpretation. Its flexible ROI suggestions and non-intrusive integration position it as a promising tool in real-world radiology workflows. To facilitate reproducibility and further evaluation, we release a fully open-source web implementation alongside a simulated error dataset. All code, data, demonstration videos, and the application are publicly available at https://github.com/avutukuri01/RADAR.
Edge-boosted graph learning for functional brain connectivity analysis
Apr 21, 2025Predicting disease states from functional brain connectivity is critical for the early diagnosis of severe neurodegenerative diseases such as Alzheimer's Disease and Parkinson's Disease. Existing studies commonly employ Graph Neural Networks (GNNs) to infer clinical diagnoses from node-based brain connectivity matrices generated through node-to-node similarities of regionally averaged fMRI signals. However, recent neuroscience studies found that such node-based connectivity does not accurately capture ``functional connections" within the brain. This paper proposes a novel approach to brain network analysis that emphasizes edge functional connectivity (eFC), shifting the focus to inter-edge relationships. Additionally, we introduce a co-embedding technique to integrate edge functional connections effectively. Experimental results on the ADNI and PPMI datasets demonstrate that our method significantly outperforms state-of-the-art GNN methods in classifying functional brain networks.
CompCap: Improving Multimodal Large Language Models with Composite Captions
Dec 06, 2024



How well can Multimodal Large Language Models (MLLMs) understand composite images? Composite images (CIs) are synthetic visuals created by merging multiple visual elements, such as charts, posters, or screenshots, rather than being captured directly by a camera. While CIs are prevalent in real-world applications, recent MLLM developments have primarily focused on interpreting natural images (NIs). Our research reveals that current MLLMs face significant challenges in accurately understanding CIs, often struggling to extract information or perform complex reasoning based on these images. We find that existing training data for CIs are mostly formatted for question-answer tasks (e.g., in datasets like ChartQA and ScienceQA), while high-quality image-caption datasets, critical for robust vision-language alignment, are only available for NIs. To bridge this gap, we introduce Composite Captions (CompCap), a flexible framework that leverages Large Language Models (LLMs) and automation tools to synthesize CIs with accurate and detailed captions. Using CompCap, we curate CompCap-118K, a dataset containing 118K image-caption pairs across six CI types. We validate the effectiveness of CompCap-118K by supervised fine-tuning MLLMs of three sizes: xGen-MM-inst.-4B and LLaVA-NeXT-Vicuna-7B/13B. Empirical results show that CompCap-118K significantly enhances MLLMs' understanding of CIs, yielding average gains of 1.7%, 2.0%, and 2.9% across eleven benchmarks, respectively.
Practical Phase Retrieval Using Double Deep Image Priors
Nov 02, 2022



Phase retrieval (PR) concerns the recovery of complex phases from complex magnitudes. We identify the connection between the difficulty level and the number and variety of symmetries in PR problems. We focus on the most difficult far-field PR (FFPR), and propose a novel method using double deep image priors. In realistic evaluation, our method outperforms all competing methods by large margins. As a single-instance method, our method requires no training data and minimal hyperparameter tuning, and hence enjoys good practicality.
Object-Centric Unsupervised Image Captioning
Dec 02, 2021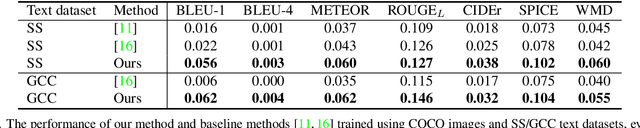



Training an image captioning model in an unsupervised manner without utilizing annotated image-caption pairs is an important step towards tapping into a wider corpus of text and images. In the supervised setting, image-caption pairs are "well-matched", where all objects mentioned in the sentence appear in the corresponding image. These pairings are, however, not available in the unsupervised setting. To overcome this, a main school of research that has been shown to be effective in overcoming this is to construct pairs from the images and texts in the training set according to their overlap of objects. Unlike in the supervised setting, these constructed pairings are however not guaranteed to have fully overlapping set of objects. Our work in this paper overcomes this by harvesting objects corresponding to a given sentence from the training set, even if they don't belong to the same image. When used as input to a transformer, such mixture of objects enable larger if not full object coverage, and when supervised by the corresponding sentence, produced results that outperform current state of the art unsupervised methods by a significant margin. Building upon this finding, we further show that (1) additional information on relationship between objects and attributes of objects also helps in boosting performance; and (2) our method also extends well to non-English image captioning, which usually suffers from a scarcer level of annotations. Our findings are supported by strong empirical results.
Phase Retrieval using Single-Instance Deep Generative Prior
Jun 22, 2021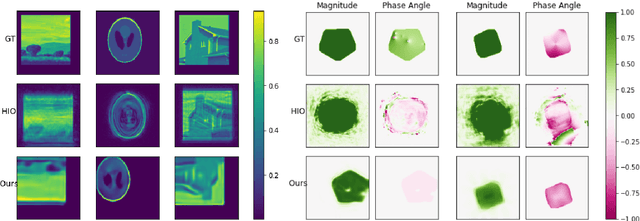
Several deep learning methods for phase retrieval exist, but most of them fail on realistic data without precise support information. We propose a novel method based on single-instance deep generative prior that works well on complex-valued crystal data.