 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fusion Refiner Networks
Apr 08, 2021

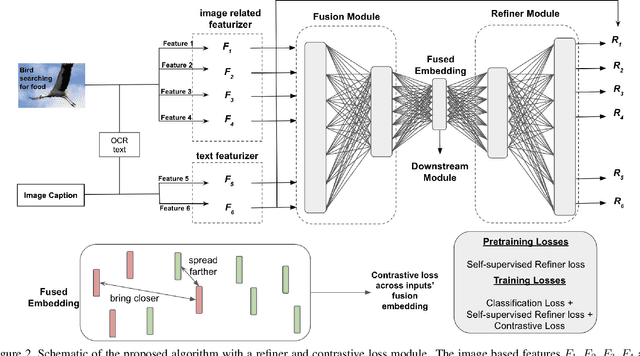

Tasks that rely on multi-modal information typically include a fusion module that combines information from different modalities. In this work, we develop a Refiner Fusion Network (ReFNet) that enables fusion modules to combine strong unimodal representation with strong multimodal representations. ReFNet combines the fusion network with a decoding/defusing module, which imposes a modality-centric responsibility condition. This approach addresses a big gap in existing multimodal fusion frameworks by ensuring that both unimodal and fused representations are strongly encoded in the latent fusion space. We demonstrate that the Refiner Fusion Network can improve upon performance of powerful baseline fusion modules such as multimodal transformers. The refiner network enables inducing graphical representations of the fused embeddings in the latent space, which we prove under certain conditions and is supported by strong empirical results in the numerical experiments. These graph structures are further strengthened by combining the ReFNet with a Multi-Similarity contrastive loss function. The modular nature of Refiner Fusion Network lends itself to be combined with different fusion architectures easily, and in addition, the refiner step can be applied for pre-training on unlabeled datasets, thus leveraging unsupervised data towards improving performance. We demonstrate the power of Refiner Fusion Networks on three datasets, and further show that they can maintain performance with only a small fraction of labeled data.