 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretation Meets Safety: A Survey on Interpretation Methods and Tools for Improving LLM Safety
Jun 05, 2025As large language models (LLMs) see wider real-world use, understanding and mitigating their unsafe behaviors is critical. Interpretation techniques can reveal causes of unsafe outputs and guide safety, but such connections with safety are often overlooked in prior surveys. We present the first survey that bridges this gap, introducing a unified framework that connects safety-focused interpretation methods, the safety enhancements they inform, and the tools that operationalize them. Our novel taxonomy, organized by LLM workflow stages, summarizes nearly 70 works at their intersections. We conclude with open challenges and future directions. This timely survey helps researchers and practitioners navigate key advancements for safer, more interpretable LLMs.
Inference Compute-Optimal Video Vision Language Models
May 24, 2025This work investigates the optimal allocation of inference compute across three key scaling factors in video vision language models: language model size, frame count, and the number of visual tokens per frame. While prior works typically focuses on optimizing model efficiency or improving performance without considering resource constraints, we instead identify optimal model configuration under fixed inference compute budgets. We conduct large-scale training sweeps and careful parametric modeling of task performance to identify the inference compute-optimal frontier. Our experiments reveal how task performance depends on scaling factors and finetuning data size, as well as how changes in data size shift the compute-optimal frontier. These findings translate to practical tips for selecting these scaling factors.
Shape it Up! Restoring LLM Safety during Finetuning
May 22, 2025Finetuning large language models (LLMs) enables user-specific customization but introduces critical safety risks: even a few harmful examples can compromise safety alignment. A common mitigation strategy is to update the model more strongly on examples deemed safe, while downweighting or excluding those flagged as unsafe. However, because safety context can shift within a single example, updating the model equally on both harmful and harmless parts of a response is suboptimal-a coarse treatment we term static safety shaping. In contrast, we propose dynamic safety shaping (DSS), a framework that uses fine-grained safety signals to reinforce learning from safe segments of a response while suppressing unsafe content. To enable such fine-grained control during finetuning, we introduce a key insight: guardrail models, traditionally used for filtering, can be repurposed to evaluate partial responses, tracking how safety risk evolves throughout the response, segment by segment. This leads to the Safety Trajectory Assessment of Response (STAR), a token-level signal that enables shaping to operate dynamically over the training sequence. Building on this, we present STAR-DSS, guided by STAR scores, that robustly mitigates finetuning risks and delivers substantial safety improvements across diverse threats, datasets, and model families-all without compromising capability on intended tasks. We encourage future safety research to build on dynamic shaping principles for stronger mitigation against evolving finetuning risks.
CompCap: Improving Multimodal Large Language Models with Composite Captions
Dec 06, 2024



How well can Multimodal Large Language Models (MLLMs) understand composite images? Composite images (CIs) are synthetic visuals created by merging multiple visual elements, such as charts, posters, or screenshots, rather than being captured directly by a camera. While CIs are prevalent in real-world applications, recent MLLM developments have primarily focused on interpreting natural images (NIs). Our research reveals that current MLLMs face significant challenges in accurately understanding CIs, often struggling to extract information or perform complex reasoning based on these images. We find that existing training data for CIs are mostly formatted for question-answer tasks (e.g., in datasets like ChartQA and ScienceQA), while high-quality image-caption datasets, critical for robust vision-language alignment, are only available for NIs. To bridge this gap, we introduce Composite Captions (CompCap), a flexible framework that leverages Large Language Models (LLMs) and automation tools to synthesize CIs with accurate and detailed captions. Using CompCap, we curate CompCap-118K, a dataset containing 118K image-caption pairs across six CI types. We validate the effectiveness of CompCap-118K by supervised fine-tuning MLLMs of three sizes: xGen-MM-inst.-4B and LLaVA-NeXT-Vicuna-7B/13B. Empirical results show that CompCap-118K significantly enhances MLLMs' understanding of CIs, yielding average gains of 1.7%, 2.0%, and 2.9% across eleven benchmarks, respectively.
Non-Robust Features are Not Always Useful in One-Class Classification
Jul 08, 2024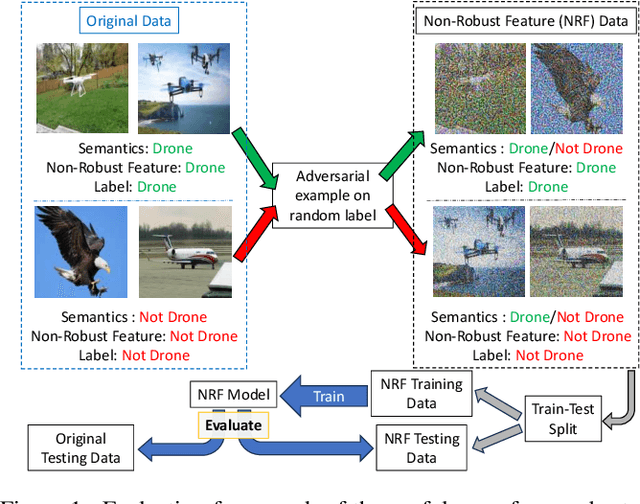

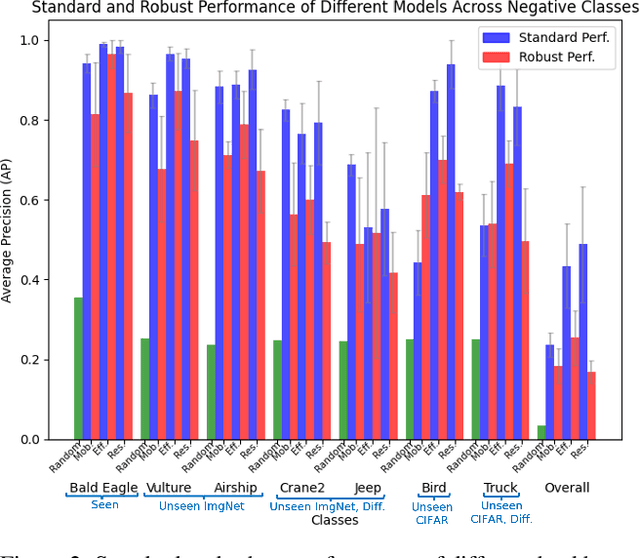
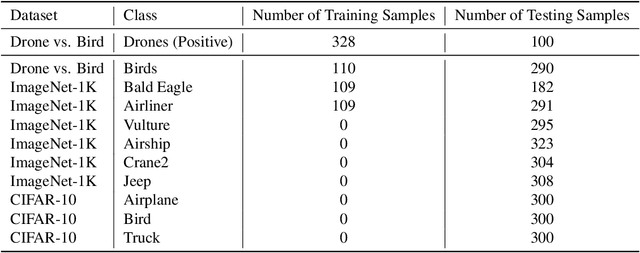
The robustness of machine learning models has been questioned by the existence of adversarial examples. We examine the threat of adversarial examples in practical applications that require lightweight models for one-class classification. Building on Ilyas et al. (2019), we investigate the vulnerability of lightweight one-class classifiers to adversarial attacks and possible reasons for it. Our results show that lightweight one-class classifiers learn features that are not robust (e.g. texture) under stronger attacks. However, unlike in multi-class classification (Ilyas et al., 2019), these non-robust features are not always useful for the one-class task, suggesting that learning these unpredictive and non-robust features is an unwanted consequence of training.
Navigating the Safety Landscape: Measuring Risks in Finetuning Large Language Models
May 28, 2024Safety alignment is the key to guiding the behaviors of large language models (LLMs) that are in line with human preferences and restrict harmful behaviors at inference time, but recent studies show that it can be easily compromised by finetuning with only a few adversarially designed training examples. We aim to measure the risks in finetuning LLMs through navigating the LLM safety landscape. We discover a new phenomenon observed universally in the model parameter space of popular open-source LLMs, termed as "safety basin": randomly perturbing model weights maintains the safety level of the original aligned model in its local neighborhood. Our discovery inspires us to propose the new VISAGE safety metric that measures the safety in LLM finetuning by probing its safety landscape. Visualizing the safety landscape of the aligned model enables us to understand how finetuning compromises safety by dragging the model away from the safety basin. LLM safety landscape also highlights the system prompt's critical role in protecting a model, and that such protection transfers to its perturbed variants within the safety basin. These observations from our safety landscape research provide new insights for future work on LLM safety community.
Interactive Visual Learning for Stable Diffusion
Apr 22, 2024Diffusion-based generative models' impressive ability to create convincing images has garnered global attention. However, their complex internal structures and operations often pose challenges for non-experts to grasp. We introduce Diffusion Explainer, the first interactive visualization tool designed to elucidate how Stable Diffusion transforms text prompts into images. It tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations. This integration enables users to fluidly transition between multiple levels of abstraction through animations and interactive elements. Offering real-time hands-on experience, Diffusion Explainer allows users to adjust Stable Diffusion's hyperparameters and prompts without the need for installation or specialized hardware. Accessible via users' web browsers, Diffusion Explainer is making significant strides in democratizing AI education, fostering broader public access. More than 7,200 users spanning 113 countries have used our open-sourced tool at https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/MbkIADZjPnA.
LLM Attributor: Interactive Visual Attribution for LLM Generation
Apr 01, 2024

While large language models (LLMs) have shown remarkable capability to generate convincing text across diverse domains, concerns around its potential risks have highlighted the importance of understanding the rationale behind text generation. We present LLM Attributor, a Python library that provides interactive visualizations for training data attribution of an LLM's text generation. Our library offers a new way to quickly attribute an LLM's text generation to training data points to inspect model behaviors, enhance its trustworthiness, and compare model-generated text with user-provided text. We describe the visual and interactive design of our tool and highlight usage scenarios for LLaMA2 models fine-tuned with two different datasets: online articles about recent disasters and finance-related question-answer pairs. Thanks to LLM Attributor's broad support for computational notebooks, users can easily integrate it into their workflow to interactively visualize attributions of their models. For easier access and extensibility, we open-source LLM Attributor at https://github.com/poloclub/ LLM-Attribution. The video demo is available at https://youtu.be/mIG2MDQKQxM.
UniTable: Towards a Unified Framework for Table Structure Recognition via Self-Supervised Pretraining
Mar 07, 2024



Tables convey factual and quantitative data with implicit conventions created by humans that are often challenging for machines to parse. Prior work on table structure recognition (TSR) has mainly centered around complex task-specific combinations of available inputs and tools. We present UniTable, a training framework that unifies both the training paradigm and training objective of TSR. Its training paradigm combines the simplicity of purely pixel-level inputs with the effectiveness and scalability empowered by self-supervised pretraining (SSP) from diverse unannotated tabular images. Our framework unifies the training objectives of all three TSR tasks - extracting table structure, cell content, and cell bounding box (bbox) - into a unified task-agnostic training objective: language modeling. Extensive quantitative and qualitative analyses highlight UniTable's state-of-the-art (SOTA) performance on four of the largest TSR datasets. To promote reproducible research, enhance transparency, and SOTA innovations, we open-source our code at https://github.com/poloclub/unitable and release the first-of-its-kind Jupyter Notebook of the whole inference pipeline, fine-tuned across multiple TSR datasets, supporting all three TSR tasks.
Self-Supervised Pre-Training for Table Structure Recognition Transformer
Feb 23, 2024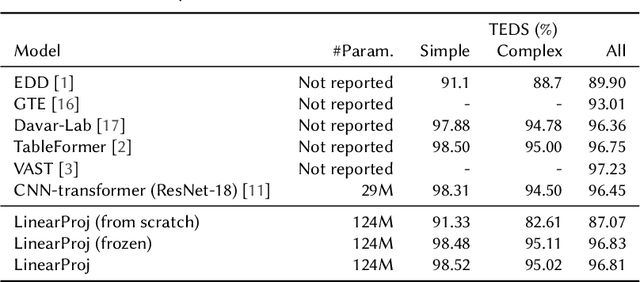
Table structure recognition (TSR) aims to convert tabular images into a machine-readable format. Although hybrid convolutional neural network (CNN)-transformer architecture is widely used in existing approaches, linear projection transformer has outperformed the hybrid architecture in numerous vision tasks due to its simplicity and efficiency. However, existing research has demonstrated that a direct replacement of CNN backbone with linear projection leads to a marked performance drop. In this work, we resolve the issue by proposing a self-supervised pre-training (SSP) method for TSR transformers. We discover that the performance gap between the linear projection transformer and the hybrid CNN-transformer can be mitigated by SSP of the visual encoder in the TSR model. We conducted reproducible ablation studies and open-sourced our code at https://github.com/poloclub/unitable to enhance transparency, inspire innovations, and facilitate fair comparisons in our domain as tables are a promising modality for representation learning.