 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTable: Towards a Unified Framework for Table Structure Recognition via Self-Supervised Pretraining
Mar 07, 2024



Tables convey factual and quantitative data with implicit conventions created by humans that are often challenging for machines to parse. Prior work on table structure recognition (TSR) has mainly centered around complex task-specific combinations of available inputs and tools. We present UniTable, a training framework that unifies both the training paradigm and training objective of TSR. Its training paradigm combines the simplicity of purely pixel-level inputs with the effectiveness and scalability empowered by self-supervised pretraining (SSP) from diverse unannotated tabular images. Our framework unifies the training objectives of all three TSR tasks - extracting table structure, cell content, and cell bounding box (bbox) - into a unified task-agnostic training objective: language modeling. Extensive quantitative and qualitative analyses highlight UniTable's state-of-the-art (SOTA) performance on four of the largest TSR datasets. To promote reproducible research, enhance transparency, and SOTA innovations, we open-source our code at https://github.com/poloclub/unitable and release the first-of-its-kind Jupyter Notebook of the whole inference pipeline, fine-tuned across multiple TSR datasets, supporting all three TSR tasks.
Self-Supervised Pre-Training for Table Structure Recognition Transformer
Feb 23, 2024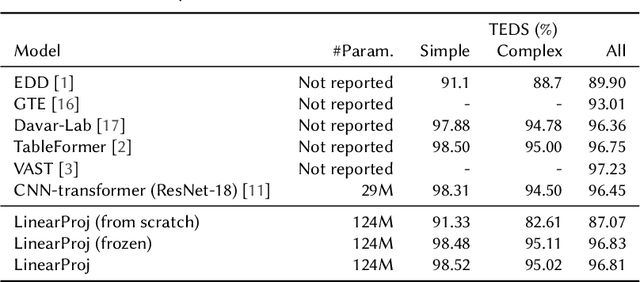
Table structure recognition (TSR) aims to convert tabular images into a machine-readable format. Although hybrid convolutional neural network (CNN)-transformer architecture is widely used in existing approaches, linear projection transformer has outperformed the hybrid architecture in numerous vision tasks due to its simplicity and efficiency. However, existing research has demonstrated that a direct replacement of CNN backbone with linear projection leads to a marked performance drop. In this work, we resolve the issue by proposing a self-supervised pre-training (SSP) method for TSR transformers. We discover that the performance gap between the linear projection transformer and the hybrid CNN-transformer can be mitigated by SSP of the visual encoder in the TSR model. We conducted reproducible ablation studies and open-sourced our code at https://github.com/poloclub/unitable to enhance transparency, inspire innovations, and facilitate fair comparisons in our domain as tables are a promising modality for representation learning.
High-Performance Transformers for Table Structure Recognition Need Early Convolutions
Nov 09, 2023
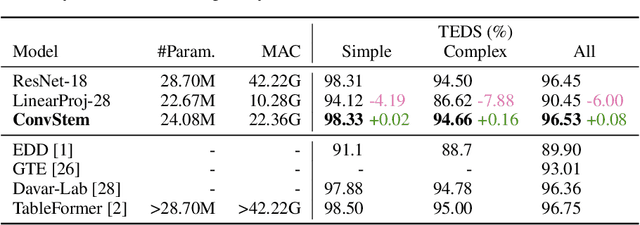

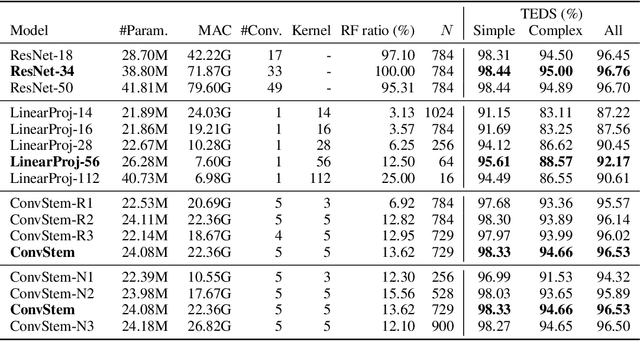
Table structure recognition (TSR) aims to convert tabular images into a machine-readable format, where a visual encoder extracts image features and a textual decoder generates table-representing tokens. Existing approaches use classic convolutional neural network (CNN) backbones for the visual encoder and transformers for the textual decoder. However, this hybrid CNN-Transformer architecture introduces a complex visual encoder that accounts for nearly half of the total model parameters, markedly reduces both training and inference speed, and hinders the potential for self-supervised learning in TSR. In this work, we design a lightweight visual encoder for TSR without sacrificing expressive power. We discover that a convolutional stem can match classic CNN backbone performance, with a much simpler model. The convolutional stem strikes an optimal balance between two crucial factors for high-performance TSR: a higher receptive field (RF) ratio and a longer sequence length. This allows it to "see" an appropriate portion of the table and "store" the complex table structure within sufficient context length for the subsequent transformer. We conducted reproducible ablation studies and open-sourced our code at https://github.com/poloclub/tsr-convstem to enhance transparency, inspire innovations, and facilitate fair comparisons in our domain as tables are a promising modality for representation learning.