 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Token Attacks Cannot Reliably Audit Unlearning in Large Language Models
Feb 20, 2025Large language models (LLMs) have become increasingly popular. Their emergent capabilities can be attributed to their massive training datasets. However, these datasets often contain undesirable or inappropriate content, e.g., harmful texts, personal information, and copyrighted material. This has promoted research into machine unlearning that aims to remove information from trained models. In particular, approximate unlearning seeks to achieve information removal by strategically editing the model rather than complete model retraining. Recent work has shown that soft token attacks (STA) can successfully extract purportedly unlearned information from LLMs, thereby exposing limitations in current unlearning methodologies. In this work, we reveal that STAs are an inadequate tool for auditing unlearning. Through systematic evaluation on common unlearning benchmarks (Who Is Harry Potter? and TOFU), we demonstrate that such attacks can elicit any information from the LLM, regardless of (1) the deployed unlearning algorithm, and (2) whether the queried content was originally present in the training corpus. Furthermore, we show that STA with just a few soft tokens (1-10) can elicit random strings over 400-characters long. Thus showing that STAs are too powerful, and misrepresent the effectiveness of the unlearning methods. Our work highlights the need for better evaluation baselines, and more appropriate auditing tools for assessing the effectiveness of unlearning in LLMs.
Imperceptible Adversarial Examples in the Physical World
Nov 25, 2024



Adversarial examples in the digital domain against deep learning-based computer vision models allow for perturbations that are imperceptible to human eyes. However, producing similar adversarial examples in the physical world has been difficult due to the non-differentiable image distortion functions in visual sensing systems. The existing algorithms for generating physically realizable adversarial examples often loosen their definition of adversarial examples by allowing unbounded perturbations, resulting in obvious or even strange visual patterns. In this work, we make adversarial examples imperceptible in the physical world using a straight-through estimator (STE, a.k.a. BPDA). We employ STE to overcome the non-differentiability -- applying exact, non-differentiable distortions in the forward pass of the backpropagation step, and using the identity function in the backward pass. Our differentiable rendering extension to STE also enables imperceptible adversarial patches in the physical world. Using printout photos, and experiments in the CARLA simulator, we show that STE enables fast generation of $\ell_\infty$ bounded adversarial examples despite the non-differentiable distortions. To the best of our knowledge, this is the first work demonstrating imperceptible adversarial examples bounded by small $\ell_\infty$ norms in the physical world that force zero classification accuracy in the global perturbation threat model and cause near-zero ($4.22\%$) AP50 in object detection in the patch perturbation threat model. We urge the community to re-evaluate the threat of adversarial examples in the physical world.
Investigating the Semantic Robustness of CLIP-based Zero-Shot Anomaly Segmentation
May 13, 2024Zero-shot anomaly segmentation using pre-trained foundation models is a promising approach that enables effective algorithms without expensive, domain-specific training or fine-tuning. Ensuring that these methods work across various environmental conditions and are robust to distribution shifts is an open problem. We investigate the performance of WinCLIP [14] zero-shot anomaly segmentation algorithm by perturbing test data using three semantic transformations: bounded angular rotations, bounded saturation shifts, and hue shifts. We empirically measure a lower performance bound by aggregating across per-sample worst-case perturbations and find that average performance drops by up to 20% in area under the ROC curve and 40% in area under the per-region overlap curve. We find that performance is consistently lowered on three CLIP backbones, regardless of model architecture or learning objective, demonstrating a need for careful performance evaluation.
Robust Principles: Architectural Design Principles for Adversarially Robust CNNs
Sep 01, 2023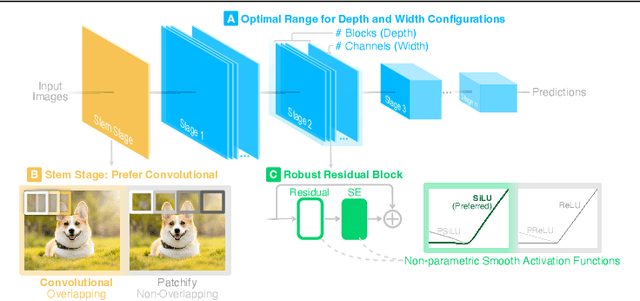
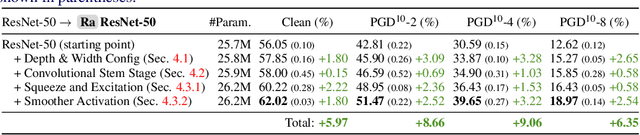
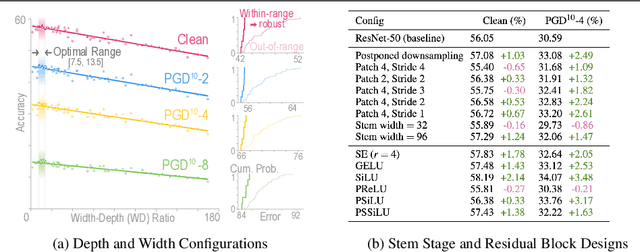

Our research aims to unify existing works' diverging opinions on how architectural components affect the adversarial robustness of CNNs. To accomplish our goal, we synthesize a suite of three generalizable robust architectural design principles: (a) optimal range for depth and width configurations, (b) preferring convolutional over patchify stem stage, and (c) robust residual block design through adopting squeeze and excitation blocks and non-parametric smooth activation functions. Through extensive experiments across a wide spectrum of dataset scales, adversarial training methods, model parameters, and network design spaces, our principles consistently and markedly improve AutoAttack accuracy: 1-3 percentage points (pp) on CIFAR-10 and CIFAR-100, and 4-9 pp on ImageNet. The code is publicly available at https://github.com/poloclub/robust-principles.
RobArch: Designing Robust Architectures against Adversarial Attacks
Jan 08, 2023Adversarial Training is the most effective approach for improving the robustness of Deep Neural Networks (DNNs). However, compared to the large body of research in optimizing the adversarial training process, there are few investigations into how architecture components affect robustness, and they rarely constrain model capacity. Thus, it is unclear where robustness precisely comes from. In this work, we present the first large-scale systematic study on the robustness of DNN architecture components under fixed parameter budgets. Through our investigation, we distill 18 actionable robust network design guidelines that empower model developers to gain deep insights. We demonstrate these guidelines' effectiveness by introducing the novel Robust Architecture (RobArch) model that instantiates the guidelines to build a family of top-performing models across parameter capacities against strong adversarial attacks. RobArch achieves the new state-of-the-art AutoAttack accuracy on the RobustBench ImageNet leaderboard. The code is available at $\href{https://github.com/ShengYun-Peng/RobArch}{\text{this url}}$.
Membership-Doctor: Comprehensive Assessment of Membership Inference Against Machine Learning Models
Aug 22, 2022
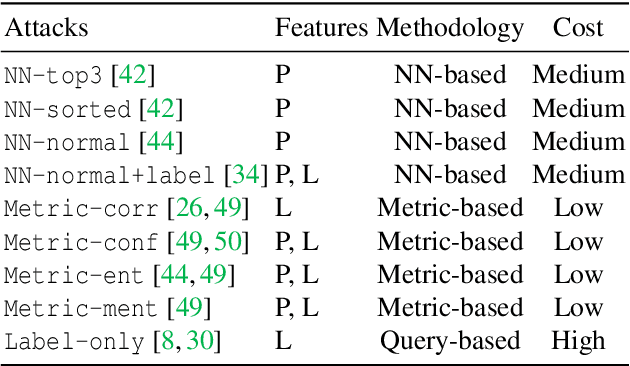


Machine learning models are prone to memorizing sensitive data, making them vulnerable to membership inference attacks in which an adversary aims to infer whether an input sample was used to train the model. Over the past few years, researchers have produced many membership inference attacks and defenses. However, these attacks and defenses employ a variety of strategies and are conducted in different models and datasets. The lack of comprehensive benchmark, however, means we do not understand the strengths and weaknesses of existing attacks and defenses. We fill this gap by presenting a large-scale measurement of different membership inference attacks and defenses. We systematize membership inference through the study of nine attacks and six defenses and measure the performance of different attacks and defenses in the holistic evaluation. We then quantify the impact of the threat model on the results of these attacks. We find that some assumptions of the threat model, such as same-architecture and same-distribution between shadow and target models, are unnecessary. We are also the first to execute attacks on the real-world data collected from the Internet, instead of laboratory datasets. We further investigate what determines the performance of membership inference attacks and reveal that the commonly believed overfitting level is not sufficient for the success of the attacks. Instead, the Jensen-Shannon distance of entropy/cross-entropy between member and non-member samples correlates with attack performance much better. This gives us a new way to accurately predict membership inference risks without running the attack. Finally, we find that data augmentation degrades the performance of existing attacks to a larger extent, and we propose an adaptive attack using augmentation to train shadow and attack models that improve attack performance.
Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks
Dec 05, 2017



Although deep neural networks (DNNs) have achieved great success in many tasks, they can often be fooled by \emph{adversarial examples} that are generated by adding small but purposeful distortions to natural examples. Previous studies to defend against adversarial examples mostly focused on refining the DNN models, but have either shown limited success or required expensive computation. We propose a new strategy, \emph{feature squeezing}, that can be used to harden DNN models by detecting adversarial examples. Feature squeezing reduces the search space available to an adversary by coalescing samples that correspond to many different feature vectors in the original space into a single sample. By comparing a DNN model's prediction on the original input with that on squeezed inputs, feature squeezing detects adversarial examples with high accuracy and few false positives. This paper explores two feature squeezing methods: reducing the color bit depth of each pixel and spatial smoothing. These simple strategies are inexpensive and complementary to other defenses, and can be combined in a joint detection framework to achieve high detection rates against state-of-the-art attacks.
Feature Squeezing Mitigates and Detects Carlini/Wagner Adversarial Examples
May 30, 2017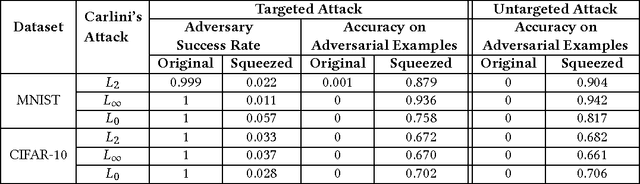

Feature squeezing is a recently-introduced framework for mitigating and detecting adversarial examples. In previous work, we showed that it is effective against several earlier methods for generating adversarial examples. In this short note, we report on recent results showing that simple feature squeezing techniques also make deep learning models significantly more robust against the Carlini/Wagner attacks, which are the best known adversarial methods discovered to date.
DeepCloak: Masking Deep Neural Network Models for Robustness Against Adversarial Samples
Apr 17, 2017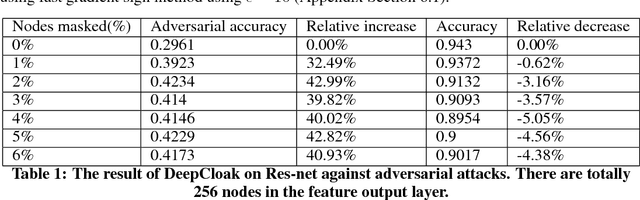
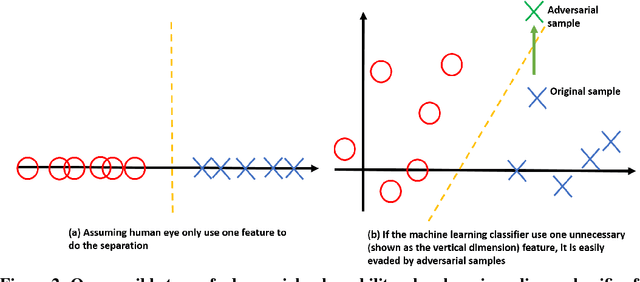
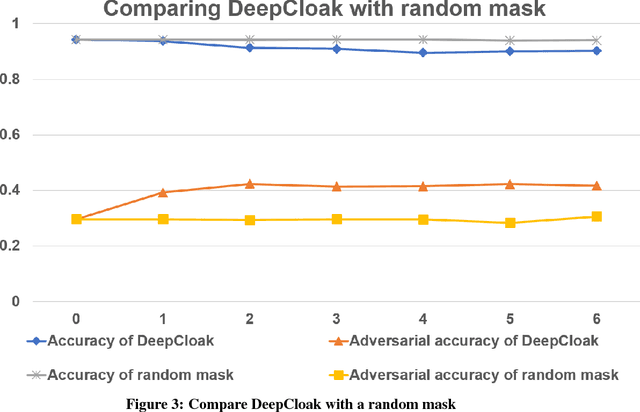
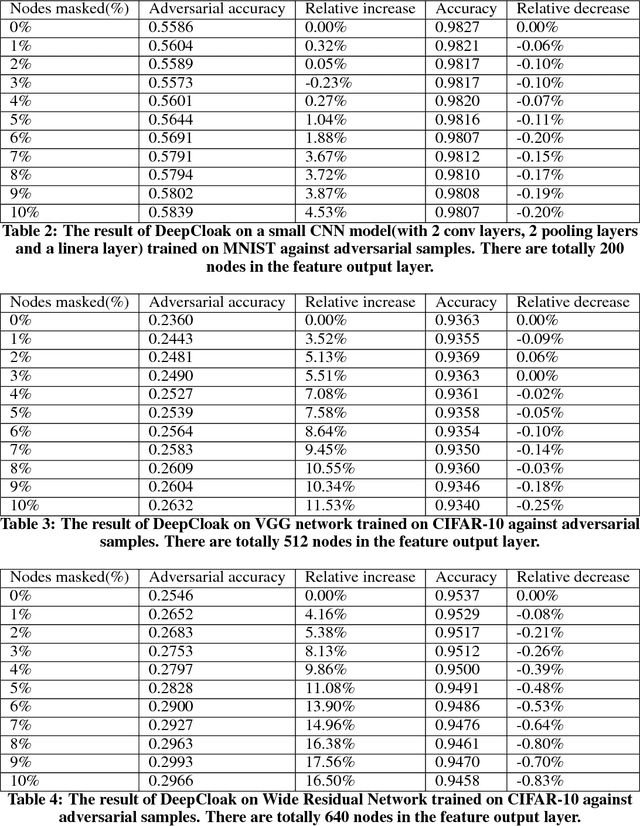
Recent studies have shown that deep neural networks (DNN) are vulnerable to adversarial samples: maliciously-perturbed samples crafted to yield incorrect model outputs. Such attacks can severely undermine DNN systems, particularly in security-sensitive settings. It was observed that an adversary could easily generate adversarial samples by making a small perturbation on irrelevant feature dimensions that are unnecessary for the current classification task. To overcome this problem, we introduce a defensive mechanism called DeepCloak. By identifying and removing unnecessary features in a DNN model, DeepCloak limits the capacity an attacker can use generating adversarial samples and therefore increase the robustness against such inputs. Comparing with other defensive approaches, DeepCloak is easy to implement and computationally efficient. Experimental results show that DeepCloak can increase the performance of state-of-the-art DNN models against adversarial samples.