 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks Using Differentiable Rendering: A Survey
Nov 14, 2024Differentiable rendering methods have emerged as a promising means for generating photo-realistic and physically plausible adversarial attacks by manipulating 3D objects and scenes that can deceive deep neural networks (DNNs). Recently, differentiable rendering capabilities have evolved significantly into a diverse landscape of libraries, such as Mitsuba, PyTorch3D, and methods like Neural Radiance Fields and 3D Gaussian Splatting for solving inverse rendering problems that share conceptually similar properties commonly used to attack DNNs, such as back-propagation and optimization. However, the adversarial machine learning research community has not yet fully explored or understood such capabilities for generating attacks. Some key reasons are that researchers often have different attack goals, such as misclassification or misdetection, and use different tasks to accomplish these goals by manipulating different representation in a scene, such as the mesh or texture of an object. This survey adopts a task-oriented unifying framework that systematically summarizes common tasks, such as manipulating textures, altering illumination, and modifying 3D meshes to exploit vulnerabilities in DNNs. Our framework enables easy comparison of existing works, reveals research gaps and spotlights exciting future research directions in this rapidly evolving field. Through focusing on how these tasks enable attacks on various DNNs such as image classification, facial recognition, object detection, optical flow and depth estimation, our survey helps researchers and practitioners better understand the vulnerabilities of computer vision systems against photorealistic adversarial attacks that could threaten real-world applications.
Navigating the Safety Landscape: Measuring Risks in Finetuning Large Language Models
May 28, 2024Safety alignment is the key to guiding the behaviors of large language models (LLMs) that are in line with human preferences and restrict harmful behaviors at inference time, but recent studies show that it can be easily compromised by finetuning with only a few adversarially designed training examples. We aim to measure the risks in finetuning LLMs through navigating the LLM safety landscape. We discover a new phenomenon observed universally in the model parameter space of popular open-source LLMs, termed as "safety basin": randomly perturbing model weights maintains the safety level of the original aligned model in its local neighborhood. Our discovery inspires us to propose the new VISAGE safety metric that measures the safety in LLM finetuning by probing its safety landscape. Visualizing the safety landscape of the aligned model enables us to understand how finetuning compromises safety by dragging the model away from the safety basin. LLM safety landscape also highlights the system prompt's critical role in protecting a model, and that such protection transfers to its perturbed variants within the safety basin. These observations from our safety landscape research provide new insights for future work on LLM safety community.
REVAMP: Automated Simulations of Adversarial Attacks on Arbitrary Objects in Realistic Scenes
Oct 18, 2023

Deep Learning models, such as those used in an autonomous vehicle are vulnerable to adversarial attacks where an attacker could place an adversarial object in the environment, leading to mis-classification. Generating these adversarial objects in the digital space has been extensively studied, however successfully transferring these attacks from the digital realm to the physical realm has proven challenging when controlling for real-world environmental factors. In response to these limitations, we introduce REVAMP, an easy-to-use Python library that is the first-of-its-kind tool for creating attack scenarios with arbitrary objects and simulating realistic environmental factors, lighting, reflection, and refraction. REVAMP enables researchers and practitioners to swiftly explore various scenarios within the digital realm by offering a wide range of configurable options for designing experiments and using differentiable rendering to reproduce physically plausible adversarial objects. We will demonstrate and invite the audience to try REVAMP to produce an adversarial texture on a chosen object while having control over various scene parameters. The audience will choose a scene, an object to attack, the desired attack class, and the number of camera positions to use. Then, in real time, we show how this altered texture causes the chosen object to be mis-classified, showcasing the potential of REVAMP in real-world scenarios. REVAMP is open-source and available at https://github.com/poloclub/revamp.
Robust Principles: Architectural Design Principles for Adversarially Robust CNNs
Sep 01, 2023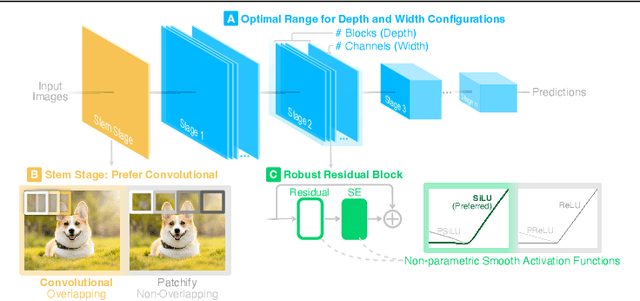
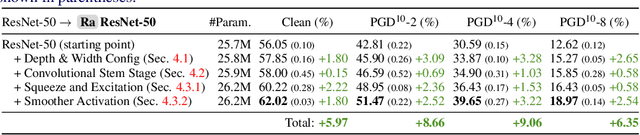
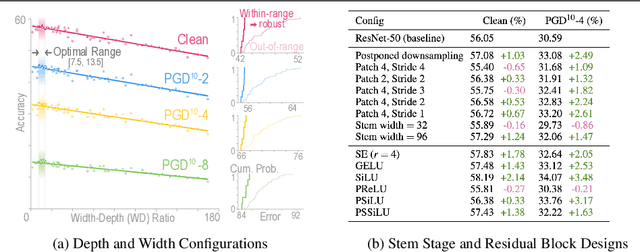

Our research aims to unify existing works' diverging opinions on how architectural components affect the adversarial robustness of CNNs. To accomplish our goal, we synthesize a suite of three generalizable robust architectural design principles: (a) optimal range for depth and width configurations, (b) preferring convolutional over patchify stem stage, and (c) robust residual block design through adopting squeeze and excitation blocks and non-parametric smooth activation functions. Through extensive experiments across a wide spectrum of dataset scales, adversarial training methods, model parameters, and network design spaces, our principles consistently and markedly improve AutoAttack accuracy: 1-3 percentage points (pp) on CIFAR-10 and CIFAR-100, and 4-9 pp on ImageNet. The code is publicly available at https://github.com/poloclub/robust-principles.
LLM Self Defense: By Self Examination, LLMs Know They Are Being Tricked
Aug 15, 2023



Large language models (LLMs) have skyrocketed in popularity in recent years due to their ability to generate high-quality text in response to human prompting. However, these models have been shown to have the potential to generate harmful content in response to user prompting (e.g., giving users instructions on how to commit crimes). There has been a focus in the literature on mitigating these risks, through methods like aligning models with human values through reinforcement learning. However, it has been shown that even aligned language models are susceptible to adversarial attacks that bypass their restrictions on generating harmful text. We propose a simple approach to defending against these attacks by having a large language model filter its own responses. Our current results show that even if a model is not fine-tuned to be aligned with human values, it is possible to stop it from presenting harmful content to users by validating the content using a language model.