 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperceptible Adversarial Examples in the Physical World
Nov 25, 2024



Adversarial examples in the digital domain against deep learning-based computer vision models allow for perturbations that are imperceptible to human eyes. However, producing similar adversarial examples in the physical world has been difficult due to the non-differentiable image distortion functions in visual sensing systems. The existing algorithms for generating physically realizable adversarial examples often loosen their definition of adversarial examples by allowing unbounded perturbations, resulting in obvious or even strange visual patterns. In this work, we make adversarial examples imperceptible in the physical world using a straight-through estimator (STE, a.k.a. BPDA). We employ STE to overcome the non-differentiability -- applying exact, non-differentiable distortions in the forward pass of the backpropagation step, and using the identity function in the backward pass. Our differentiable rendering extension to STE also enables imperceptible adversarial patches in the physical world. Using printout photos, and experiments in the CARLA simulator, we show that STE enables fast generation of $\ell_\infty$ bounded adversarial examples despite the non-differentiable distortions. To the best of our knowledge, this is the first work demonstrating imperceptible adversarial examples bounded by small $\ell_\infty$ norms in the physical world that force zero classification accuracy in the global perturbation threat model and cause near-zero ($4.22\%$) AP50 in object detection in the patch perturbation threat model. We urge the community to re-evaluate the threat of adversarial examples in the physical world.
Investigating the Semantic Robustness of CLIP-based Zero-Shot Anomaly Segmentation
May 13, 2024Zero-shot anomaly segmentation using pre-trained foundation models is a promising approach that enables effective algorithms without expensive, domain-specific training or fine-tuning. Ensuring that these methods work across various environmental conditions and are robust to distribution shifts is an open problem. We investigate the performance of WinCLIP [14] zero-shot anomaly segmentation algorithm by perturbing test data using three semantic transformations: bounded angular rotations, bounded saturation shifts, and hue shifts. We empirically measure a lower performance bound by aggregating across per-sample worst-case perturbations and find that average performance drops by up to 20% in area under the ROC curve and 40% in area under the per-region overlap curve. We find that performance is consistently lowered on three CLIP backbones, regardless of model architecture or learning objective, demonstrating a need for careful performance evaluation.
Investigating the Adversarial Robustness of Density Estimation Using the Probability Flow ODE
Oct 10, 2023



Beyond their impressive sampling capabilities, score-based diffusion models offer a powerful analysis tool in the form of unbiased density estimation of a query sample under the training data distribution. In this work, we investigate the robustness of density estimation using the probability flow (PF) neural ordinary differential equation (ODE) model against gradient-based likelihood maximization attacks and the relation to sample complexity, where the compressed size of a sample is used as a measure of its complexity. We introduce and evaluate six gradient-based log-likelihood maximization attacks, including a novel reverse integration attack. Our experimental evaluations on CIFAR-10 show that density estimation using the PF ODE is robust against high-complexity, high-likelihood attacks, and that in some cases adversarial samples are semantically meaningful, as expected from a robust estimator.
Robust Principles: Architectural Design Principles for Adversarially Robust CNNs
Sep 01, 2023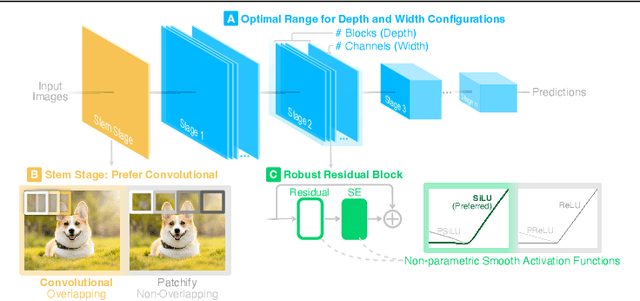
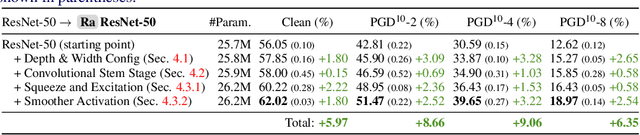
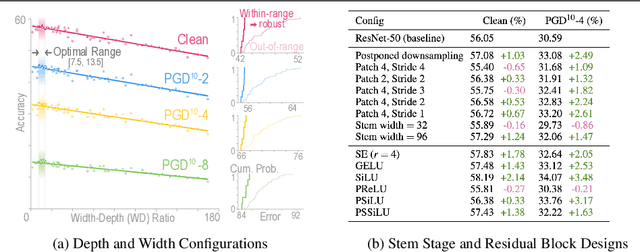

Our research aims to unify existing works' diverging opinions on how architectural components affect the adversarial robustness of CNNs. To accomplish our goal, we synthesize a suite of three generalizable robust architectural design principles: (a) optimal range for depth and width configurations, (b) preferring convolutional over patchify stem stage, and (c) robust residual block design through adopting squeeze and excitation blocks and non-parametric smooth activation functions. Through extensive experiments across a wide spectrum of dataset scales, adversarial training methods, model parameters, and network design spaces, our principles consistently and markedly improve AutoAttack accuracy: 1-3 percentage points (pp) on CIFAR-10 and CIFAR-100, and 4-9 pp on ImageNet. The code is publicly available at https://github.com/poloclub/robust-principles.
RobArch: Designing Robust Architectures against Adversarial Attacks
Jan 08, 2023Adversarial Training is the most effective approach for improving the robustness of Deep Neural Networks (DNNs). However, compared to the large body of research in optimizing the adversarial training process, there are few investigations into how architecture components affect robustness, and they rarely constrain model capacity. Thus, it is unclear where robustness precisely comes from. In this work, we present the first large-scale systematic study on the robustness of DNN architecture components under fixed parameter budgets. Through our investigation, we distill 18 actionable robust network design guidelines that empower model developers to gain deep insights. We demonstrate these guidelines' effectiveness by introducing the novel Robust Architecture (RobArch) model that instantiates the guidelines to build a family of top-performing models across parameter capacities against strong adversarial attacks. RobArch achieves the new state-of-the-art AutoAttack accuracy on the RobustBench ImageNet leaderboard. The code is available at $\href{https://github.com/ShengYun-Peng/RobArch}{\text{this url}}$.
Membership-Doctor: Comprehensive Assessment of Membership Inference Against Machine Learning Models
Aug 22, 2022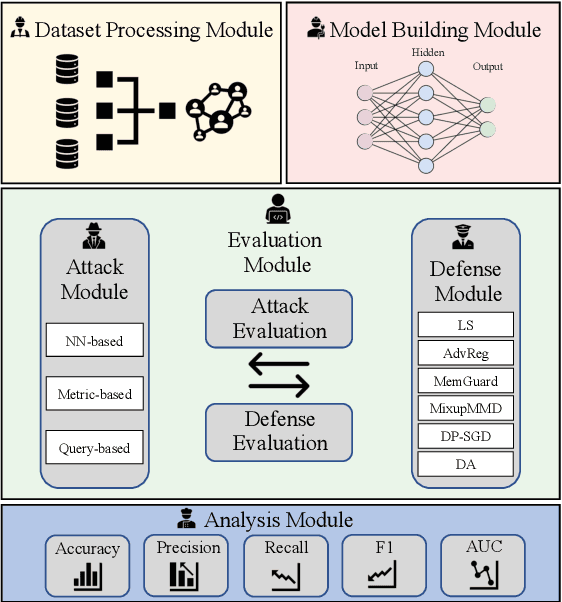
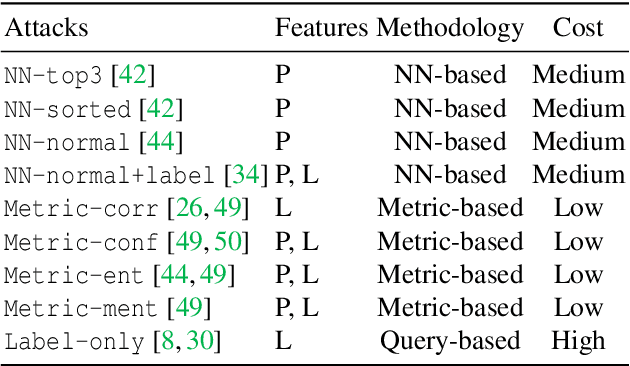


Machine learning models are prone to memorizing sensitive data, making them vulnerable to membership inference attacks in which an adversary aims to infer whether an input sample was used to train the model. Over the past few years, researchers have produced many membership inference attacks and defenses. However, these attacks and defenses employ a variety of strategies and are conducted in different models and datasets. The lack of comprehensive benchmark, however, means we do not understand the strengths and weaknesses of existing attacks and defenses. We fill this gap by presenting a large-scale measurement of different membership inference attacks and defenses. We systematize membership inference through the study of nine attacks and six defenses and measure the performance of different attacks and defenses in the holistic evaluation. We then quantify the impact of the threat model on the results of these attacks. We find that some assumptions of the threat model, such as same-architecture and same-distribution between shadow and target models, are unnecessary. We are also the first to execute attacks on the real-world data collected from the Internet, instead of laboratory datasets. We further investigate what determines the performance of membership inference attacks and reveal that the commonly believed overfitting level is not sufficient for the success of the attacks. Instead, the Jensen-Shannon distance of entropy/cross-entropy between member and non-member samples correlates with attack performance much better. This gives us a new way to accurately predict membership inference risks without running the attack. Finally, we find that data augmentation degrades the performance of existing attacks to a larger extent, and we propose an adaptive attack using augmentation to train shadow and attack models that improve attack performance.
Synthetic Dataset Generation for Adversarial Machine Learning Research
Jul 21, 2022
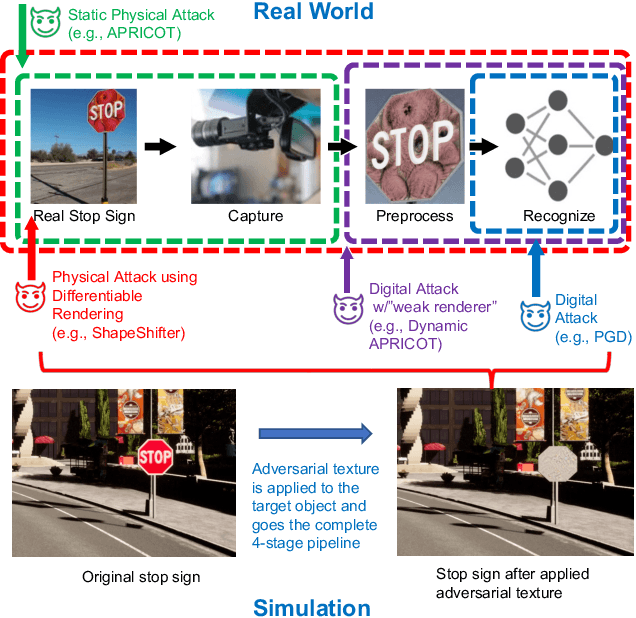


Existing adversarial example research focuses on digitally inserted perturbations on top of existing natural image datasets. This construction of adversarial examples is not realistic because it may be difficult, or even impossible, for an attacker to deploy such an attack in the real-world due to sensing and environmental effects. To better understand adversarial examples against cyber-physical systems, we propose approximating the real-world through simulation. In this paper we describe our synthetic dataset generation tool that enables scalable collection of such a synthetic dataset with realistic adversarial examples. We use the CARLA simulator to collect such a dataset and demonstrate simulated attacks that undergo the same environmental transforms and processing as real-world images. Our tools have been used to collect datasets to help evaluate the efficacy of adversarial examples, and can be found at https://github.com/carla-simulator/carla/pull/4992.
Toward Few-step Adversarial Training from a Frequency Perspective
Oct 13, 2020
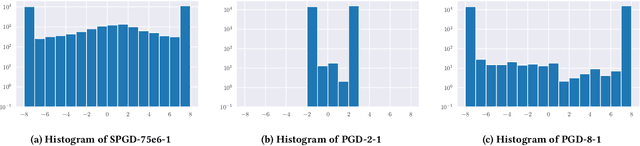
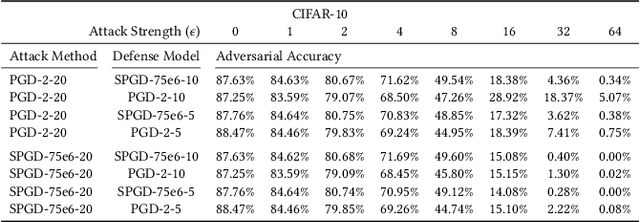
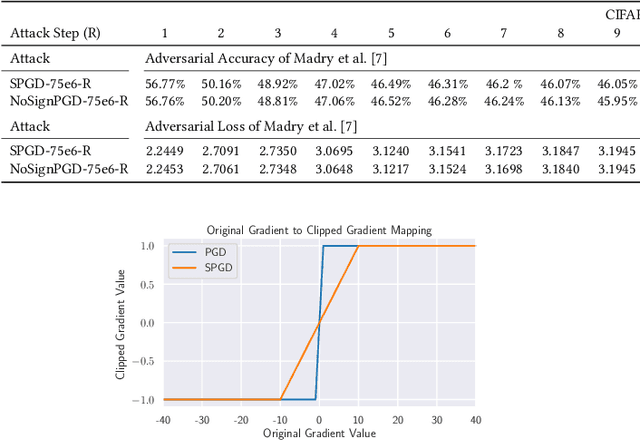
We investigate adversarial-sample generation methods from a frequency domain perspective and extend standard $l_{\infty}$ Projected Gradient Descent (PGD) to the frequency domain. The resulting method, which we call Spectral Projected Gradient Descent (SPGD), has better success rate compared to PGD during early steps of the method. Adversarially training models using SPGD achieves greater adversarial accuracy compared to PGD when holding the number of attack steps constant. The use of SPGD can, therefore, reduce the overhead of adversarial training when utilizing adversarial generation with a smaller number of steps. However, we also prove that SPGD is equivalent to a variant of the PGD ordinarily used for the $l_{\infty}$ threat model. This PGD variant omits the sign function which is ordinarily applied to the gradient. SPGD can, therefore, be performed without explicitly transforming into the frequency domain. Finally, we visualize the perturbations SPGD generates and find they use both high and low-frequency components, which suggests that removing either high-frequency components or low-frequency components is not an effective defense.
* 9 pages, 9 figures, SPAI'20, ACM ASIACCS 2020
Talk Proposal: Towards the Realistic Evaluation of Evasion Attacks using CARLA
Apr 18, 2019



In this talk we describe our content-preserving attack on object detectors, ShapeShifter, and demonstrate how to evaluate this threat in realistic scenarios. We describe how we use CARLA, a realistic urban driving simulator, to create these scenarios, and how we use ShapeShifter to generate content-preserving attacks against those scenarios.
The Efficacy of SHIELD under Different Threat Models
Feb 01, 2019


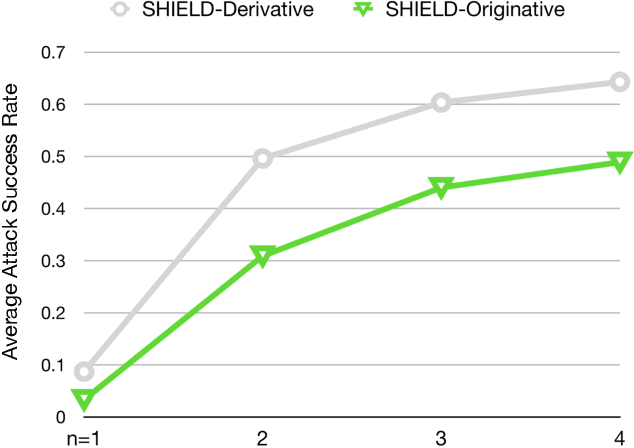
We study the efficacy of SHIELD in the face of alternative threat models. We find that SHIELD's robustness decreases by 65% (accuracy drops from 63% to 22%) against an adaptive adversary (one who knows JPEG compression is being used as a pre-processing step but not necessarily the compression level) in the gray-box threat model (adversary is aware of the model architecture but not necessarily the weights of that model). However, these adversarial examples are, so far, unable to force a targeted prediction. We also find that the robustness of the JPEG-trained models used in SHIELD decreases by 67% (accuracy drops from 57% to 19% on average) against an adaptive adversary in the gray-box threat model. The addition of SLQ pre-processing to these JPEG-trained models is also not a robust defense (accuracy drops to 0.1%) against an adaptive adversary in the gray-box threat model, and an adversary can create adversarial perturbations that force a chosen prediction. We find that neither JPEG-trained models with SLQ pre-processing nor SHIELD are robust against an adaptive adversary in the white-box threat model (accuracy is 0.1%) and the adversary can control the predicted output of their adversarial images. Finally, ensemble-based attacks transfer better (29.8% targeted accuracy) than non-ensemble based attacks (1.4%) against the JPEG-trained models in SHIELD.