 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniFusion: Vision-Language Model as Unified Encoder in Image Generation
Oct 14, 2025
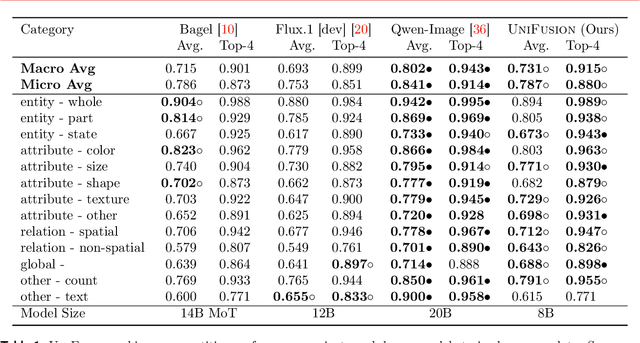

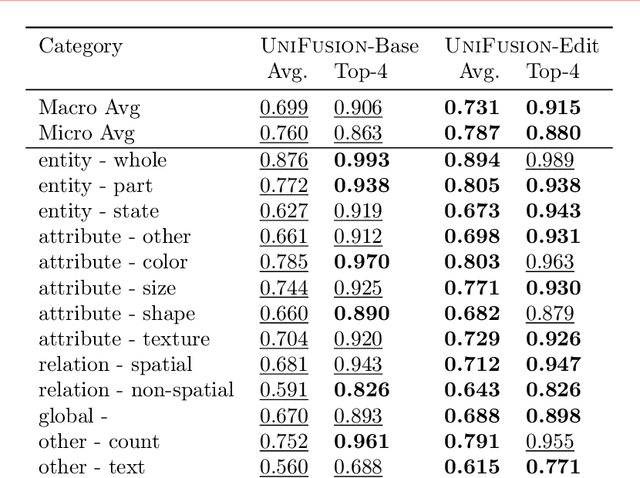
Although recent advances in visual generation have been remarkable, most existing architectures still depend on distinct encoders for images and text. This separation constrains diffusion models' ability to perform cross-modal reasoning and knowledge transfer. Prior attempts to bridge this gap often use the last layer information from VLM, employ multiple visual encoders, or train large unified models jointly for text and image generation, which demands substantial computational resources and large-scale data, limiting its accessibility.We present UniFusion, a diffusion-based generative model conditioned on a frozen large vision-language model (VLM) that serves as a unified multimodal encoder. At the core of UniFusion is the Layerwise Attention Pooling (LAP) mechanism that extracts both high level semantics and low level details from text and visual tokens of a frozen VLM to condition a diffusion generative model. We demonstrate that LAP outperforms other shallow fusion architectures on text-image alignment for generation and faithful transfer of visual information from VLM to the diffusion model which is key for editing. We propose VLM-Enabled Rewriting Injection with Flexibile Inference (VERIFI), which conditions a diffusion transformer (DiT) only on the text tokens generated by the VLM during in-model prompt rewriting. VERIFI combines the alignment of the conditioning distribution with the VLM's reasoning capabilities for increased capabilities and flexibility at inference. In addition, finetuning on editing task not only improves text-image alignment for generation, indicative of cross-modality knowledge transfer, but also exhibits tremendous generalization capabilities. Our model when trained on single image editing, zero-shot generalizes to multiple image references further motivating the unified encoder design of UniFusion.
Prompting Decision Transformers for Zero-Shot Reach-Avoid Policies
May 25, 2025Offline goal-conditioned reinforcement learning methods have shown promise for reach-avoid tasks, where an agent must reach a target state while avoiding undesirable regions of the state space. Existing approaches typically encode avoid-region information into an augmented state space and cost function, which prevents flexible, dynamic specification of novel avoid-region information at evaluation time. They also rely heavily on well-designed reward and cost functions, limiting scalability to complex or poorly structured environments. We introduce RADT, a decision transformer model for offline, reward-free, goal-conditioned, avoid region-conditioned RL. RADT encodes goals and avoid regions directly as prompt tokens, allowing any number of avoid regions of arbitrary size to be specified at evaluation time. Using only suboptimal offline trajectories from a random policy, RADT learns reach-avoid behavior through a novel combination of goal and avoid-region hindsight relabeling. We benchmark RADT against 3 existing offline goal-conditioned RL models across 11 tasks, environments, and experimental settings. RADT generalizes in a zero-shot manner to out-of-distribution avoid region sizes and counts, outperforming baselines that require retraining. In one such zero-shot setting, RADT achieves 35.7% improvement in normalized cost over the best retrained baseline while maintaining high goal-reaching success. We apply RADT to cell reprogramming in biology, where it reduces visits to undesirable intermediate gene expression states during trajectories to desired target states, despite stochastic transitions and discrete, structured state dynamics.
Exploiting Concavity Information in Gaussian Process Contextual Bandit Optimization
Mar 13, 2025The contextual bandit framework is widely used to solve sequential optimization problems where the reward of each decision depends on auxiliary context variables. In settings such as medicine, business, and engineering, the decision maker often possesses additional structural information on the generative model that can potentially be used to improve the efficiency of bandit algorithms. We consider settings in which the mean reward is known to be a concave function of the action for each fixed context. Examples include patient-specific dose-response curves in medicine and expected profit in online advertising auctions. We propose a contextual bandit algorithm that accelerates optimization by conditioning the posterior of a Bayesian Gaussian Process model on this concavity information. We design a novel shape-constrained reward function estimator using a specially chosen regression spline basis and constrained Gaussian Process posterior. Using this model, we propose a UCB algorithm and derive corresponding regret bounds. We evaluate our algorithm on numerical examples and test functions used to study optimal dosing of Anti-Clotting medication.
Controllable Sequence Editing for Counterfactual Generation
Feb 05, 2025



Sequence models generate counterfactuals by modifying parts of a sequence based on a given condition, enabling reasoning about "what if" scenarios. While these models excel at conditional generation, they lack fine-grained control over when and where edits occur. Existing approaches either focus on univariate sequences or assume that interventions affect the entire sequence globally. However, many applications require precise, localized modifications, where interventions take effect only after a specified time and impact only a subset of co-occurring variables. We introduce CLEF, a controllable sequence editing model for counterfactual reasoning about both immediate and delayed effects. CLEF learns temporal concepts that encode how and when interventions should influence a sequence. With these concepts, CLEF selectively edits relevant time steps while preserving unaffected portions of the sequence. We evaluate CLEF on cellular and patient trajectory datasets, where gene regulation affects only certain genes at specific time steps, or medical interventions alter only a subset of lab measurements. CLEF improves immediate sequence editing by up to 36.01% in MAE compared to baselines. Unlike prior methods, CLEF enables one-step generation of counterfactual sequences at any future time step, outperforming baselines by up to 65.71% in MAE. A case study on patients with type 1 diabetes mellitus shows that CLEF identifies clinical interventions that shift patient trajectories toward healthier outcomes.
Analysis on Riemann Hypothesis with Cross Entropy Optimization and Reasoning
Sep 29, 2024In this paper, we present a novel framework for the analysis of Riemann Hypothesis [27], which is composed of three key components: a) probabilistic modeling with cross entropy optimization and reasoning; b) the application of the law of large numbers; c) the application of mathematical inductions. The analysis is mainly conducted by virtue of probabilistic modeling of cross entropy optimization and reasoning with rare event simulation techniques. The application of the law of large numbers [2, 3, 6] and the application of mathematical inductions make the analysis of Riemann Hypothesis self-contained and complete to make sure that the whole complex plane is covered as conjectured in Riemann Hypothesis. We also discuss the method of enhanced top-p sampling with large language models (LLMs) for reasoning, where next token prediction is not just based on the estimated probabilities of each possible token in the current round but also based on accumulated path probabilities among multiple top-k chain of thoughts (CoTs) paths. The probabilistic modeling of cross entropy optimization and reasoning may suit well with the analysis of Riemann Hypothesis as Riemann Zeta functions are inherently dealing with the sums of infinite components of a complex number series. We hope that our analysis in this paper could shed some light on some of the insights of Riemann Hypothesis. The framework and techniques presented in this paper, coupled with recent developments with chain of thought (CoT) or diagram of thought (DoT) reasoning in large language models (LLMs) with reinforcement learning (RL) [1, 7, 18, 21, 24, 34, 39-41], could pave the way for eventual proof of Riemann Hypothesis [27].
TalkMosaic: Interactive PhotoMosaic with Multi-modal LLM Q&A Interactions
Sep 20, 2024We use images of cars of a wide range of varieties to compose an image of an animal such as a bird or a lion for the theme of environmental protection to maximize the information about cars in a single composed image and to raise the awareness about environmental challenges. We present a novel way of image interaction with an artistically-composed photomosaic image, in which a simple operation of "click and display" is used to demonstrate the interactive switch between a tile image in a photomosaic image and the corresponding original car image, which will be automatically saved on the Desktop. We build a multimodal custom GPT named TalkMosaic by incorporating car images information and the related knowledge to ChatGPT. By uploading the original car image to TalkMosaic, we can ask questions about the given car image and get the corresponding answers efficiently and effectively such as where to buy the tire in the car image that satisfies high environmental standards. We give an in-depth analysis on how to speed up the inference of multimodal LLM using sparse attention and quantization techniques with presented probabilistic FlashAttention (PrFlashAttention) and Staircase Adaptive Quantization (SAQ) methods. The implemented prototype demonstrates the feasibility and effectiveness of the presented approach.
Cross-Entropy Optimization for Hyperparameter Optimization in Stochastic Gradient-based Approaches to Train Deep Neural Networks
Sep 14, 2024In this paper, we present a cross-entropy optimization method for hyperparameter optimization in stochastic gradient-based approaches to train deep neural networks. The value of a hyperparameter of a learning algorithm often has great impact on the performance of a model such as the convergence speed, the generalization performance metrics, etc. While in some cases the hyperparameters of a learning algorithm can be part of learning parameters, in other scenarios the hyperparameters of a stochastic optimization algorithm such as Adam [5] and its variants are either fixed as a constant or are kept changing in a monotonic way over time. We give an in-depth analysis of the presented method in the framework of expectation maximization (EM). The presented algorithm of cross-entropy optimization for hyperparameter optimization of a learning algorithm (CEHPO) can be equally applicable to other areas of optimization problems in deep learning. We hope that the presented methods can provide different perspectives and offer some insights for optimization problems in different areas of machine learning and beyond.
Interactive Visual Learning for Stable Diffusion
Apr 22, 2024Diffusion-based generative models' impressive ability to create convincing images has garnered global attention. However, their complex internal structures and operations often pose challenges for non-experts to grasp. We introduce Diffusion Explainer, the first interactive visualization tool designed to elucidate how Stable Diffusion transforms text prompts into images. It tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations. This integration enables users to fluidly transition between multiple levels of abstraction through animations and interactive elements. Offering real-time hands-on experience, Diffusion Explainer allows users to adjust Stable Diffusion's hyperparameters and prompts without the need for installation or specialized hardware. Accessible via users' web browsers, Diffusion Explainer is making significant strides in democratizing AI education, fostering broader public access. More than 7,200 users spanning 113 countries have used our open-sourced tool at https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/MbkIADZjPnA.
Trigonometric Quadrature Fourier Features for Scalable Gaussian Process Regression
Oct 23, 2023



Fourier feature approximations have been successfully applied in the literature for scalable Gaussian Process (GP) regression. In particular, Quadrature Fourier Features (QFF) derived from Gaussian quadrature rules have gained popularity in recent years due to their improved approximation accuracy and better calibrated uncertainty estimates compared to Random Fourier Feature (RFF) methods. However, a key limitation of QFF is that its performance can suffer from well-known pathologies related to highly oscillatory quadrature, resulting in mediocre approximation with limited features. We address this critical issue via a new Trigonometric Quadrature Fourier Feature (TQFF) method, which uses a novel non-Gaussian quadrature rule specifically tailored for the desired Fourier transform. We derive an exact quadrature rule for TQFF, along with kernel approximation error bounds for the resulting feature map. We then demonstrate the improved performance of our method over RFF and Gaussian QFF in a suite of numerical experiments and applications, and show the TQFF enjoys accurate GP approximations over a broad range of length-scales using fewer features.
Robust Principles: Architectural Design Principles for Adversarially Robust CNNs
Sep 01, 2023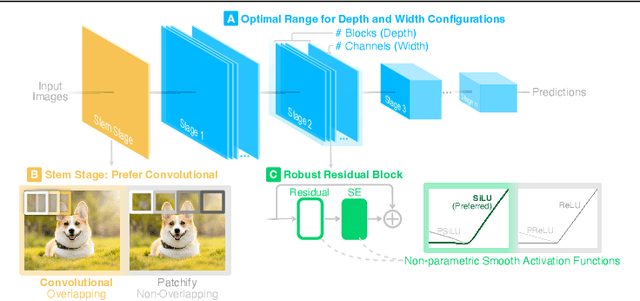
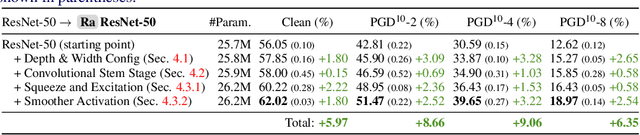
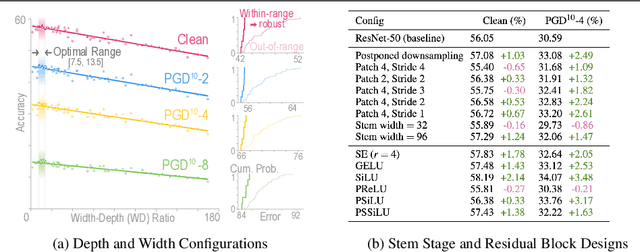

Our research aims to unify existing works' diverging opinions on how architectural components affect the adversarial robustness of CNNs. To accomplish our goal, we synthesize a suite of three generalizable robust architectural design principles: (a) optimal range for depth and width configurations, (b) preferring convolutional over patchify stem stage, and (c) robust residual block design through adopting squeeze and excitation blocks and non-parametric smooth activation functions. Through extensive experiments across a wide spectrum of dataset scales, adversarial training methods, model parameters, and network design spaces, our principles consistently and markedly improve AutoAttack accuracy: 1-3 percentage points (pp) on CIFAR-10 and CIFAR-100, and 4-9 pp on ImageNet. The code is publicly available at https://github.com/poloclub/robust-principles.