 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Visual Learning for Stable Diffusion
Apr 22, 2024Diffusion-based generative models' impressive ability to create convincing images has garnered global attention. However, their complex internal structures and operations often pose challenges for non-experts to grasp. We introduce Diffusion Explainer, the first interactive visualization tool designed to elucidate how Stable Diffusion transforms text prompts into images. It tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations. This integration enables users to fluidly transition between multiple levels of abstraction through animations and interactive elements. Offering real-time hands-on experience, Diffusion Explainer allows users to adjust Stable Diffusion's hyperparameters and prompts without the need for installation or specialized hardware. Accessible via users' web browsers, Diffusion Explainer is making significant strides in democratizing AI education, fostering broader public access. More than 7,200 users spanning 113 countries have used our open-sourced tool at https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/MbkIADZjPnA.
ClickDiffusion: Harnessing LLMs for Interactive Precise Image Editing
Apr 05, 2024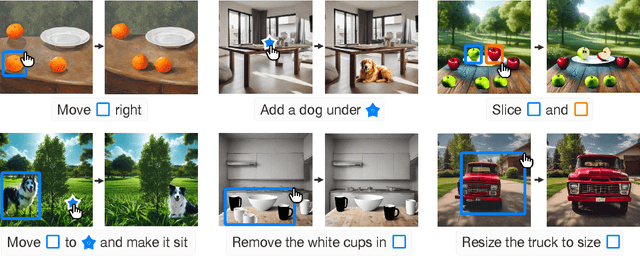


Recently, researchers have proposed powerful systems for generating and manipulating images using natural language instructions. However, it is difficult to precisely specify many common classes of image transformations with text alone. For example, a user may wish to change the location and breed of a particular dog in an image with several similar dogs. This task is quite difficult with natural language alone, and would require a user to write a laboriously complex prompt that both disambiguates the target dog and describes the destination. We propose ClickDiffusion, a system for precise image manipulation and generation that combines natural language instructions with visual feedback provided by the user through a direct manipulation interface. We demonstrate that by serializing both an image and a multi-modal instruction into a textual representation it is possible to leverage LLMs to perform precise transformations of the layout and appearance of an image. Code available at https://github.com/poloclub/ClickDiffusion.
Point and Instruct: Enabling Precise Image Editing by Unifying Direct Manipulation and Text Instructions
Feb 05, 2024Machine learning has enabled the development of powerful systems capable of editing images from natural language instructions. However, in many common scenarios it is difficult for users to specify precise image transformations with text alone. For example, in an image with several dogs, it is difficult to select a particular dog and move it to a precise location. Doing this with text alone would require a complex prompt that disambiguates the target dog and describes the destination. However, direct manipulation is well suited to visual tasks like selecting objects and specifying locations. We introduce Point and Instruct, a system for seamlessly combining familiar direct manipulation and textual instructions to enable precise image manipulation. With our system, a user can visually mark objects and locations, and reference them in textual instructions. This allows users to benefit from both the visual descriptiveness of natural language and the spatial precision of direct manipulation.
Approximate Query Matching for Image Retrieval
Mar 14, 2018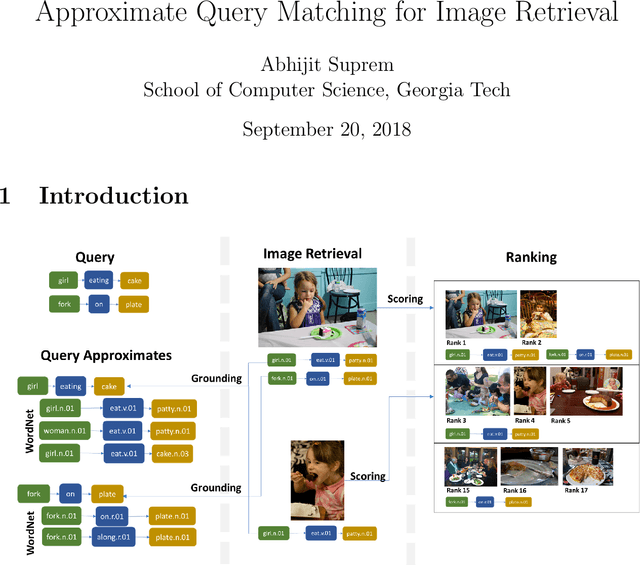
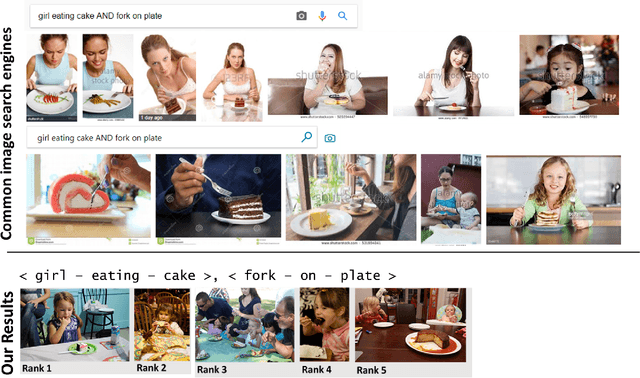
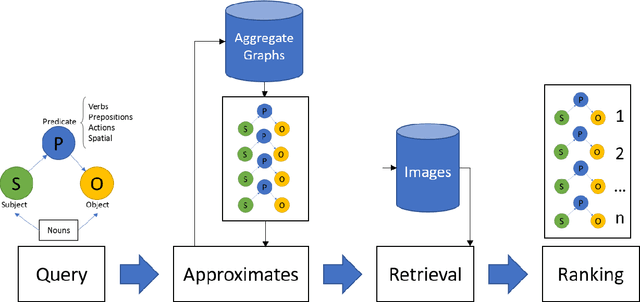
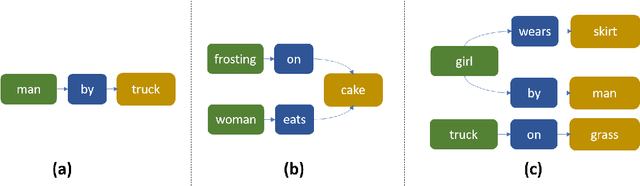
Traditional image recognition involves identifying the key object in a portrait-type image with a single object focus (ILSVRC, AlexNet, and VGG). More recent approaches consider dense image recognition - segmenting an image with appropriate bounding boxes and performing image recognition within these bounding boxes (Semantic segmentation). The Visual Genome dataset [5] is an attempt to bridge these various approaches to a cohesive dataset for each subtask - bounding box generation, image recognition, captioning, and a new operation: scene graph generation. Our focus is on using such scene graphs to perform graph search on image databases to holistically retrieve images based on a search criteria. We develop a method to store scene graphs and metadata in graph databases (using Neo4J) and to perform fast approximate retrieval of images based on a graph search query. We process more complex queries than single object search, e.g. "girl eating cake" retrieves images that contain the specified relation as well as variations.