 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuously Reliable Detection of New-Normal Misinformation: Semantic Masking and Contrastive Smoothing in High-Density Latent Regions
Jan 19, 2023Toxic misinformation campaigns have caused significant societal harm, e.g., affecting elections and COVID-19 information awareness. Unfortunately, despite successes of (gold standard) retrospective studies of misinformation that confirmed their harmful effects after the fact, they arrive too late for timely intervention and reduction of such harm. By design, misinformation evades retrospective classifiers by exploiting two properties we call new-normal: (1) never-seen-before novelty that cause inescapable generalization challenges for previous classifiers, and (2) massive but short campaigns that end before they can be manually annotated for new classifier training. To tackle these challenges, we propose UFIT, which combines two techniques: semantic masking of strong signal keywords to reduce overfitting, and intra-proxy smoothness regularization of high-density regions in the latent space to improve reliability and maintain accuracy. Evaluation of UFIT on public new-normal misinformation data shows over 30% improvement over existing approaches on future (and unseen) campaigns. To the best of our knowledge, UFIT is the first successful effort to achieve such high level of generalization on new-normal misinformation data with minimal concession (1 to 5%) of accuracy compared to oracles trained with full knowledge of all campaigns.
Time-Aware Datasets are Adaptive Knowledgebases for the New Normal
Nov 22, 2022



Recent advances in text classification and knowledge capture in language models have relied on availability of large-scale text datasets. However, language models are trained on static snapshots of knowledge and are limited when that knowledge evolves. This is especially critical for misinformation detection, where new types of misinformation continuously appear, replacing old campaigns. We propose time-aware misinformation datasets to capture time-critical phenomena. In this paper, we first present evidence of evolving misinformation and show that incorporating even simple time-awareness significantly improves classifier accuracy. Second, we present COVID-TAD, a large-scale COVID-19 misinformation da-taset spanning 25 months. It is the first large-scale misinformation dataset that contains multiple snapshots of a datastream and is orders of magnitude bigger than related misinformation datasets. We describe the collection and labeling pro-cess, as well as preliminary experiments.
Targeted Attention for Generalized- and Zero-Shot Learning
Nov 17, 2022The Zero-Shot Learning (ZSL) task attempts to learn concepts without any labeled data. Unlike traditional classification/detection tasks, the evaluation environment is provided unseen classes never encountered during training. As such, it remains both challenging, and promising on a variety of fronts, including unsupervised concept learning, domain adaptation, and dataset drift detection. Recently, there have been a variety of approaches towards solving ZSL, including improved metric learning methods, transfer learning, combinations of semantic and image domains using, e.g. word vectors, and generative models to model the latent space of known classes to classify unseen classes. We find many approaches require intensive training augmentation with attributes or features that may be commonly unavailable (attribute-based learning) or susceptible to adversarial attacks (generative learning). We propose combining approaches from the related person re-identification task for ZSL, with key modifications to ensure sufficiently improved performance in the ZSL setting without the need for feature or training dataset augmentation. We are able to achieve state-of-the-art performance on the CUB200 and Cars196 datasets in the ZSL setting compared to recent works, with NMI (normalized mutual inference) of 63.27 and top-1 of 61.04 for CUB200, and NMI 66.03 with top-1 82.75% in Cars196. We also show state-of-the-art results in the Generalized Zero-Shot Learning (GZSL) setting, with Harmonic Mean R-1 of 66.14% on the CUB200 dataset.
ATEAM: Knowledge Integration from Federated Datasets for Vehicle Feature Extraction using Annotation Team of Experts
Nov 16, 2022



The vehicle recognition area, including vehicle make-model recognition (VMMR), re-id, tracking, and parts-detection, has made significant progress in recent years, driven by several large-scale datasets for each task. These datasets are often non-overlapping, with different label schemas for each task: VMMR focuses on make and model, while re-id focuses on vehicle ID. It is promising to combine these datasets to take advantage of knowledge across datasets as well as increased training data; however, dataset integration is challenging due to the domain gap problem. This paper proposes ATEAM, an annotation team-of-experts to perform cross-dataset labeling and integration of disjoint annotation schemas. ATEAM uses diverse experts, each trained on datasets that contain an annotation schema, to transfer knowledge to datasets without that annotation. Using ATEAM, we integrated several common vehicle recognition datasets into a Knowledge Integrated Dataset (KID). We evaluate ATEAM and KID for vehicle recognition problems and show that our integrated dataset can help off-the-shelf models achieve excellent accuracy on VMMR and vehicle re-id with no changes to model architectures. We achieve mAP of 0.83 on VeRi, and accuracy of 0.97 on CompCars. We have released both the dataset and the ATEAM framework for public use.
EdnaML: A Declarative API and Framework for Reproducible Deep Learning
Nov 13, 2022Machine Learning has become the bedrock of recent advances in text, image, video, and audio processing and generation. Most production systems deal with several models during deployment and training, each with a variety of tuned hyperparameters. Furthermore, data collection and processing aspects of ML pipelines are receiving increasing interest due to their importance in creating sustainable high-quality classifiers. We present EdnaML, a framework with a declarative API for reproducible deep learning. EdnaML provides low-level building blocks that can be composed manually, as well as a high-level pipeline orchestration API to automate data collection, data processing, classifier training, classifier deployment, and model monitoring. Our layered API allows users to manage ML pipelines at high-level component abstractions, while providing flexibility to modify any part of it through the building blocks. We present several examples of ML pipelines with EdnaML, including a large-scale fake news labeling and classification system with six sub-pipelines managed by EdnaML.
Evaluating Generalizability of Fine-Tuned Models for Fake News Detection
May 23, 2022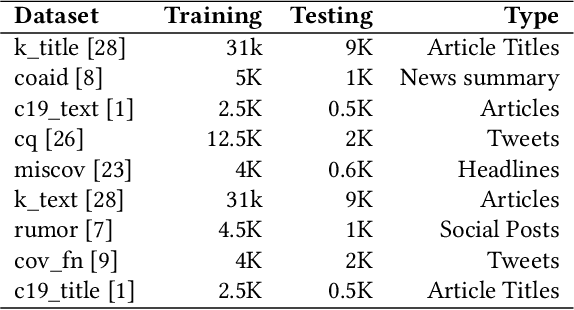
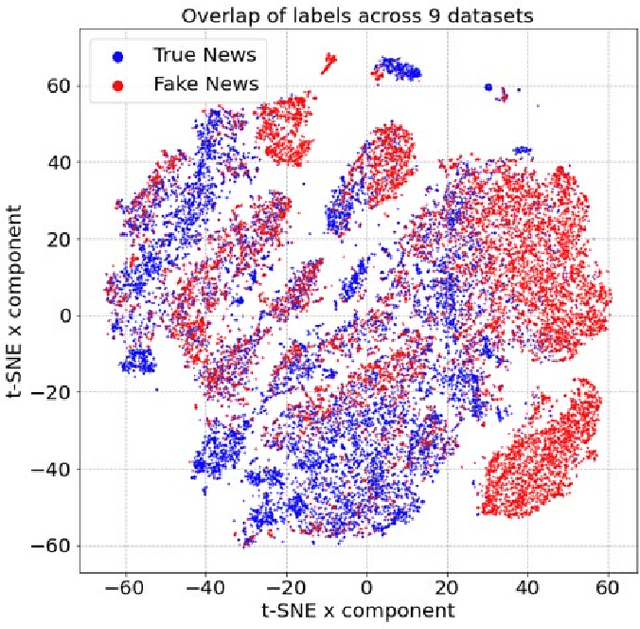
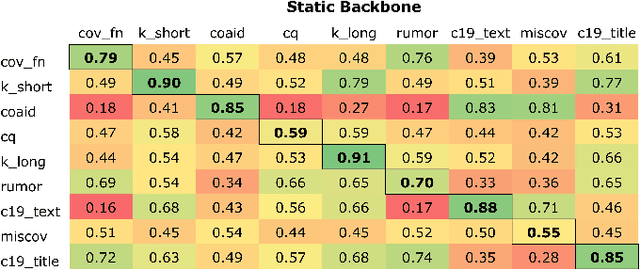
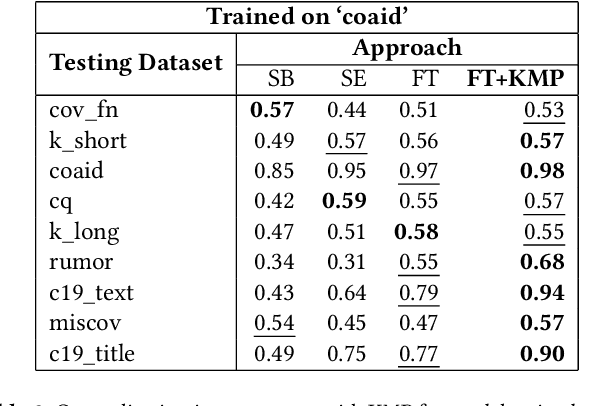
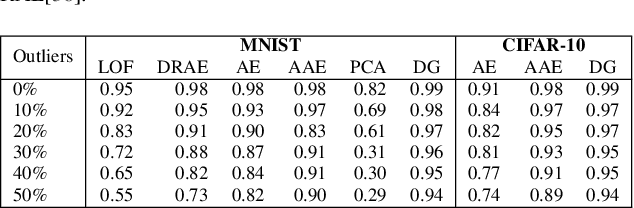
The Covid-19 pandemic has caused a dramatic and parallel rise in dangerous misinformation, denoted an `infodemic' by the CDC and WHO. Misinformation tied to the Covid-19 infodemic changes continuously; this can lead to performance degradation of fine-tuned models due to concept drift. Degredation can be mitigated if models generalize well-enough to capture some cyclical aspects of drifted data. In this paper, we explore generalizability of pre-trained and fine-tuned fake news detectors across 9 fake news datasets. We show that existing models often overfit on their training dataset and have poor performance on unseen data. However, on some subsets of unseen data that overlap with training data, models have higher accuracy. Based on this observation, we also present KMeans-Proxy, a fast and effective method based on K-Means clustering for quickly identifying these overlapping subsets of unseen data. KMeans-Proxy improves generalizability on unseen fake news datasets by 0.1-0.2 f1-points across datasets. We present both our generalizability experiments as well as KMeans-Proxy to further research in tackling the fake news problem.
Constructive Interpretability with CoLabel: Corroborative Integration, Complementary Features, and Collaborative Learning
May 20, 2022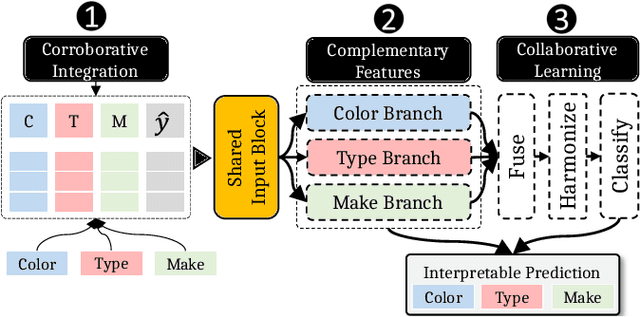
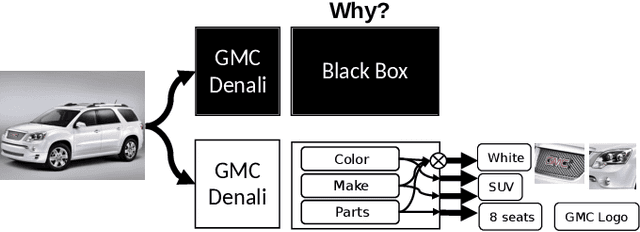
Machine learning models with explainable predictions are increasingly sought after, especially for real-world, mission-critical applications that require bias detection and risk mitigation. Inherent interpretability, where a model is designed from the ground-up for interpretability, provides intuitive insights and transparent explanations on model prediction and performance. In this paper, we present CoLabel, an approach to build interpretable models with explanations rooted in the ground truth. We demonstrate CoLabel in a vehicle feature extraction application in the context of vehicle make-model recognition (VMMR). CoLabel performs VMMR with a composite of interpretable features such as vehicle color, type, and make, all based on interpretable annotations of the ground truth labels. First, CoLabel performs corroborative integration to join multiple datasets that each have a subset of desired annotations of color, type, and make. Then, CoLabel uses decomposable branches to extract complementary features corresponding to desired annotations. Finally, CoLabel fuses them together for final predictions. During feature fusion, CoLabel harmonizes complementary branches so that VMMR features are compatible with each other and can be projected to the same semantic space for classification. With inherent interpretability, CoLabel achieves superior performance to the state-of-the-art black-box models, with accuracy of 0.98, 0.95, and 0.94 on CompCars, Cars196, and BoxCars116K, respectively. CoLabel provides intuitive explanations due to constructive interpretability, and subsequently achieves high accuracy and usability in mission-critical situations.
MiDAS: Multi-integrated Domain Adaptive Supervision for Fake News Detection
May 19, 2022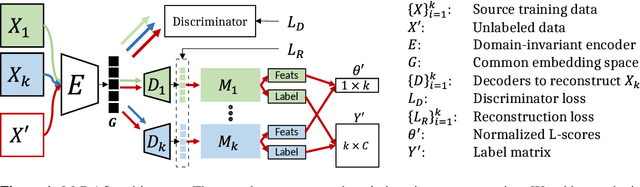
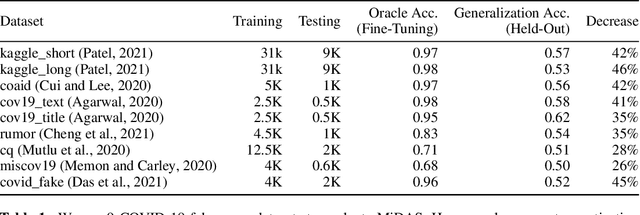
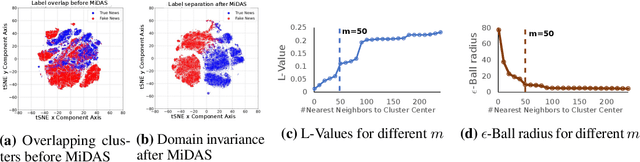
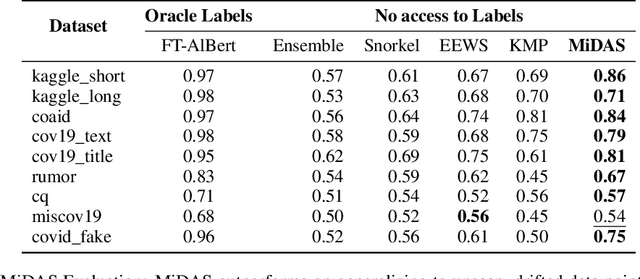
COVID-19 related misinformation and fake news, coined an 'infodemic', has dramatically increased over the past few years. This misinformation exhibits concept drift, where the distribution of fake news changes over time, reducing effectiveness of previously trained models for fake news detection. Given a set of fake news models trained on multiple domains, we propose an adaptive decision module to select the best-fit model for a new sample. We propose MiDAS, a multi-domain adaptative approach for fake news detection that ranks relevancy of existing models to new samples. MiDAS contains 2 components: a doman-invariant encoder, and an adaptive model selector. MiDAS integrates multiple pre-trained and fine-tuned models with their training data to create a domain-invariant representation. Then, MiDAS uses local Lipschitz smoothness of the invariant embedding space to estimate each model's relevance to a new sample. Higher ranked models provide predictions, and lower ranked models abstain. We evaluate MiDAS on generalization to drifted data with 9 fake news datasets, each obtained from different domains and modalities. MiDAS achieves new state-of-the-art performance on multi-domain adaptation for out-of-distribution fake news classification.
Challenges and Opportunities in Rapid Epidemic Information Propagation with Live Knowledge Aggregation from Social Media
Nov 09, 2020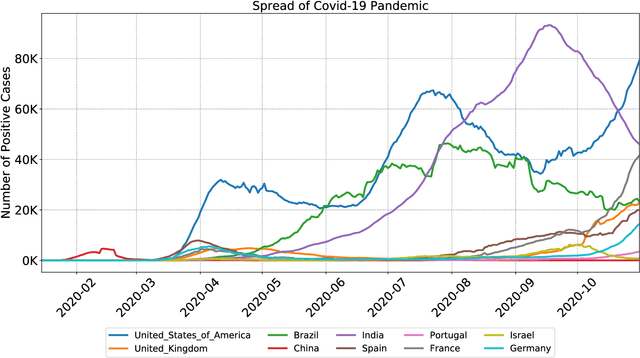
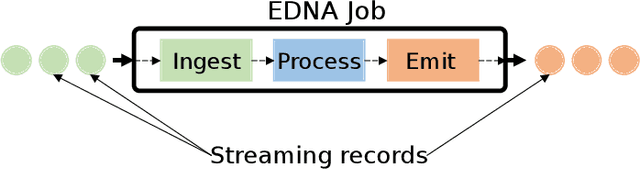
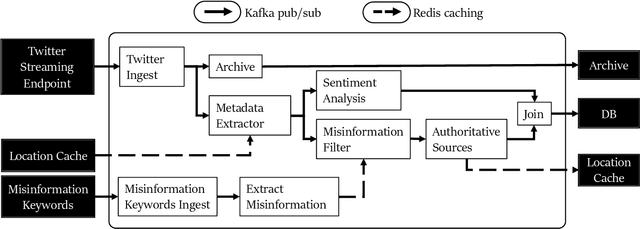
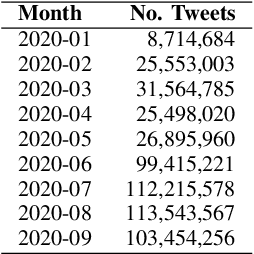
A rapidly evolving situation such as the COVID-19 pandemic is a significant challenge for AI/ML models because of its unpredictability. %The most reliable indicator of the pandemic spreading has been the number of test positive cases. However, the tests are both incomplete (due to untested asymptomatic cases) and late (due the lag from the initial contact event, worsening symptoms, and test results). Social media can complement physical test data due to faster and higher coverage, but they present a different challenge: significant amounts of noise, misinformation and disinformation. We believe that social media can become good indicators of pandemic, provided two conditions are met. The first (True Novelty) is the capture of new, previously unknown, information from unpredictably evolving situations. The second (Fact vs. Fiction) is the distinction of verifiable facts from misinformation and disinformation. Social media information that satisfy those two conditions are called live knowledge. We apply evidence-based knowledge acquisition (EBKA) approach to collect, filter, and update live knowledge through the integration of social media sources with authoritative sources. Although limited in quantity, the reliable training data from authoritative sources enable the filtering of misinformation as well as capturing truly new information. We describe the EDNA/LITMUS tools that implement EBKA, integrating social media such as Twitter and Facebook with authoritative sources such as WHO and CDC, creating and updating live knowledge on the COVID-19 pandemic.
ODIN: Automated Drift Detection and Recovery in Video Analytics
Sep 09, 2020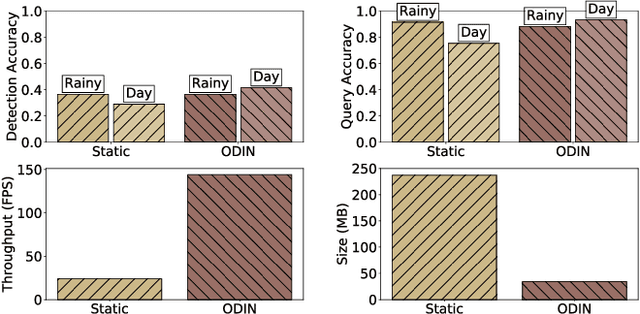

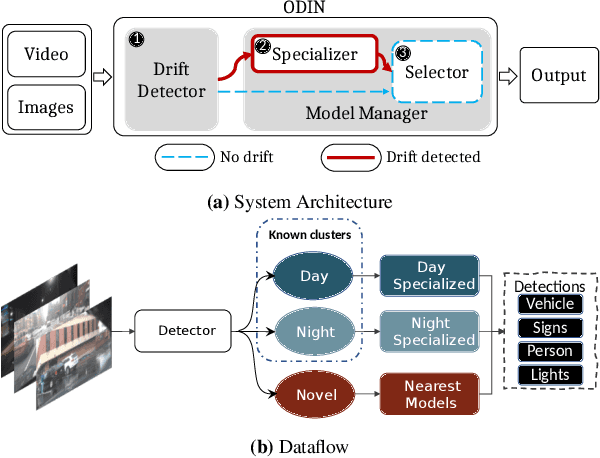
Recent advances in computer vision have led to a resurgence of interest in visual data analytics. Researchers are developing systems for effectively and efficiently analyzing visual data at scale. A significant challenge that these systems encounter lies in the drift in real-world visual data. For instance, a model for self-driving vehicles that is not trained on images containing snow does not work well when it encounters them in practice. This drift phenomenon limits the accuracy of models employed for visual data analytics. In this paper, we present a visual data analytics system, called ODIN, that automatically detects and recovers from drift. ODIN uses adversarial autoencoders to learn the distribution of high-dimensional images. We present an unsupervised algorithm for detecting drift by comparing the distributions of the given data against that of previously seen data. When ODIN detects drift, it invokes a drift recovery algorithm to deploy specialized models tailored towards the novel data points. These specialized models outperform their non-specialized counterpart on accuracy, performance, and memory footprint. Lastly, we present a model selection algorithm for picking an ensemble of best-fit specialized models to process a given input. We evaluate the efficacy and efficiency of ODIN on high-resolution dashboard camera videos captured under diverse environments from the Berkeley DeepDrive dataset. We demonstrate that ODIN's models deliver 6x higher throughput, 2x higher accuracy, and 6x smaller memory footprint compared to a baseline system without automated drift detection and recovery.