 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Datasets are Adaptive Knowledgebases for the New Normal
Nov 22, 2022



Recent advances in text classification and knowledge capture in language models have relied on availability of large-scale text datasets. However, language models are trained on static snapshots of knowledge and are limited when that knowledge evolves. This is especially critical for misinformation detection, where new types of misinformation continuously appear, replacing old campaigns. We propose time-aware misinformation datasets to capture time-critical phenomena. In this paper, we first present evidence of evolving misinformation and show that incorporating even simple time-awareness significantly improves classifier accuracy. Second, we present COVID-TAD, a large-scale COVID-19 misinformation da-taset spanning 25 months. It is the first large-scale misinformation dataset that contains multiple snapshots of a datastream and is orders of magnitude bigger than related misinformation datasets. We describe the collection and labeling pro-cess, as well as preliminary experiments.
ATEAM: Knowledge Integration from Federated Datasets for Vehicle Feature Extraction using Annotation Team of Experts
Nov 16, 2022



The vehicle recognition area, including vehicle make-model recognition (VMMR), re-id, tracking, and parts-detection, has made significant progress in recent years, driven by several large-scale datasets for each task. These datasets are often non-overlapping, with different label schemas for each task: VMMR focuses on make and model, while re-id focuses on vehicle ID. It is promising to combine these datasets to take advantage of knowledge across datasets as well as increased training data; however, dataset integration is challenging due to the domain gap problem. This paper proposes ATEAM, an annotation team-of-experts to perform cross-dataset labeling and integration of disjoint annotation schemas. ATEAM uses diverse experts, each trained on datasets that contain an annotation schema, to transfer knowledge to datasets without that annotation. Using ATEAM, we integrated several common vehicle recognition datasets into a Knowledge Integrated Dataset (KID). We evaluate ATEAM and KID for vehicle recognition problems and show that our integrated dataset can help off-the-shelf models achieve excellent accuracy on VMMR and vehicle re-id with no changes to model architectures. We achieve mAP of 0.83 on VeRi, and accuracy of 0.97 on CompCars. We have released both the dataset and the ATEAM framework for public use.
EdnaML: A Declarative API and Framework for Reproducible Deep Learning
Nov 13, 2022Machine Learning has become the bedrock of recent advances in text, image, video, and audio processing and generation. Most production systems deal with several models during deployment and training, each with a variety of tuned hyperparameters. Furthermore, data collection and processing aspects of ML pipelines are receiving increasing interest due to their importance in creating sustainable high-quality classifiers. We present EdnaML, a framework with a declarative API for reproducible deep learning. EdnaML provides low-level building blocks that can be composed manually, as well as a high-level pipeline orchestration API to automate data collection, data processing, classifier training, classifier deployment, and model monitoring. Our layered API allows users to manage ML pipelines at high-level component abstractions, while providing flexibility to modify any part of it through the building blocks. We present several examples of ML pipelines with EdnaML, including a large-scale fake news labeling and classification system with six sub-pipelines managed by EdnaML.
Constructive Interpretability with CoLabel: Corroborative Integration, Complementary Features, and Collaborative Learning
May 20, 2022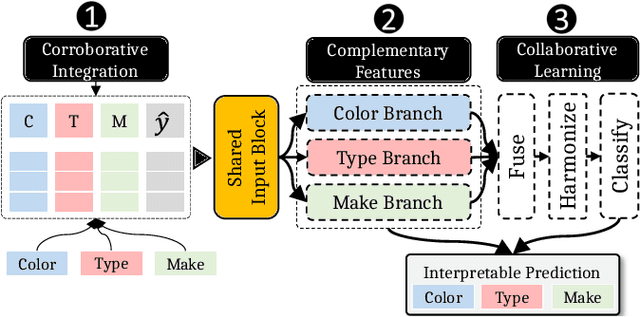
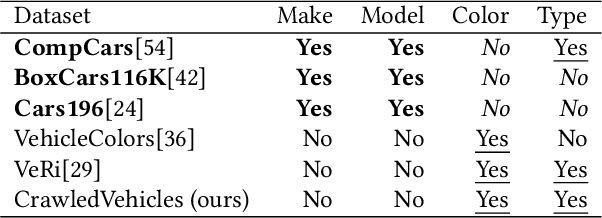
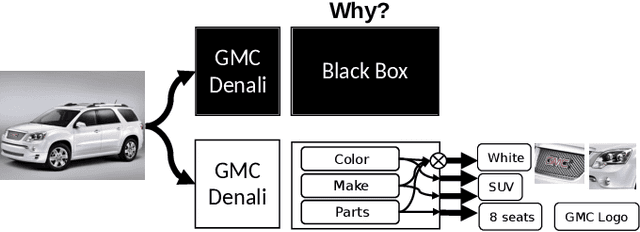
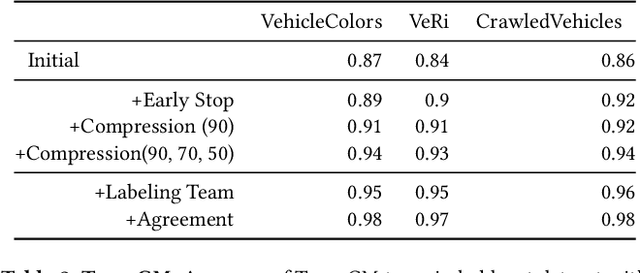
Machine learning models with explainable predictions are increasingly sought after, especially for real-world, mission-critical applications that require bias detection and risk mitigation. Inherent interpretability, where a model is designed from the ground-up for interpretability, provides intuitive insights and transparent explanations on model prediction and performance. In this paper, we present CoLabel, an approach to build interpretable models with explanations rooted in the ground truth. We demonstrate CoLabel in a vehicle feature extraction application in the context of vehicle make-model recognition (VMMR). CoLabel performs VMMR with a composite of interpretable features such as vehicle color, type, and make, all based on interpretable annotations of the ground truth labels. First, CoLabel performs corroborative integration to join multiple datasets that each have a subset of desired annotations of color, type, and make. Then, CoLabel uses decomposable branches to extract complementary features corresponding to desired annotations. Finally, CoLabel fuses them together for final predictions. During feature fusion, CoLabel harmonizes complementary branches so that VMMR features are compatible with each other and can be projected to the same semantic space for classification. With inherent interpretability, CoLabel achieves superior performance to the state-of-the-art black-box models, with accuracy of 0.98, 0.95, and 0.94 on CompCars, Cars196, and BoxCars116K, respectively. CoLabel provides intuitive explanations due to constructive interpretability, and subsequently achieves high accuracy and usability in mission-critical situations.