 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODIN: Automated Drift Detection and Recovery in Video Analytics
Paper and Code
Sep 09, 2020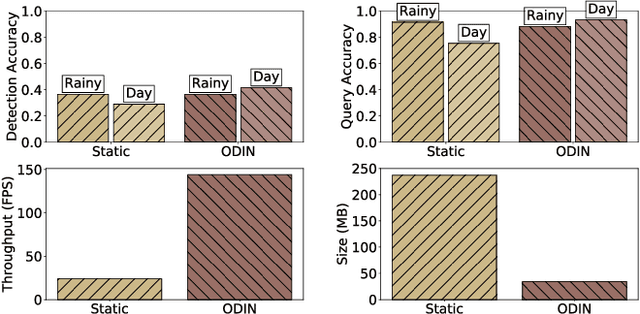
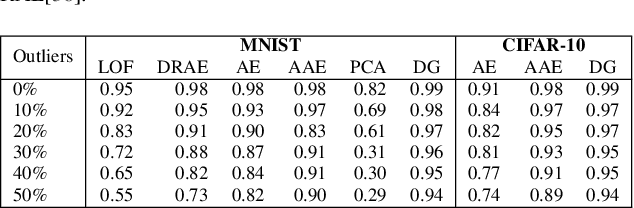

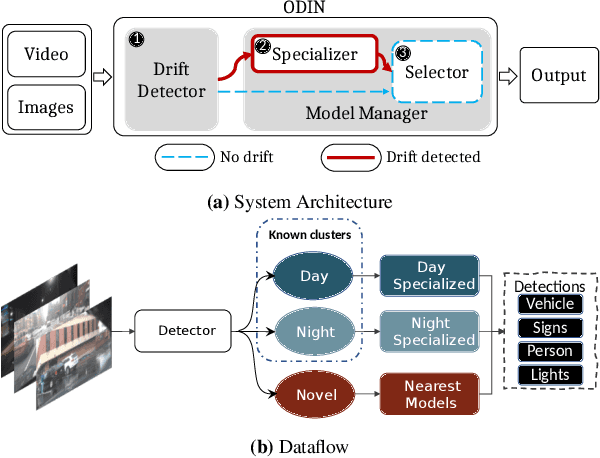
Recent advances in computer vision have led to a resurgence of interest in visual data analytics. Researchers are developing systems for effectively and efficiently analyzing visual data at scale. A significant challenge that these systems encounter lies in the drift in real-world visual data. For instance, a model for self-driving vehicles that is not trained on images containing snow does not work well when it encounters them in practice. This drift phenomenon limits the accuracy of models employed for visual data analytics. In this paper, we present a visual data analytics system, called ODIN, that automatically detects and recovers from drift. ODIN uses adversarial autoencoders to learn the distribution of high-dimensional images. We present an unsupervised algorithm for detecting drift by comparing the distributions of the given data against that of previously seen data. When ODIN detects drift, it invokes a drift recovery algorithm to deploy specialized models tailored towards the novel data points. These specialized models outperform their non-specialized counterpart on accuracy, performance, and memory footprint. Lastly, we present a model selection algorithm for picking an ensemble of best-fit specialized models to process a given input. We evaluate the efficacy and efficiency of ODIN on high-resolution dashboard camera videos captured under diverse environments from the Berkeley DeepDrive dataset. We demonstrate that ODIN's models deliver 6x higher throughput, 2x higher accuracy, and 6x smaller memory footprint compared to a baseline system without automated drift detection and recovery.